







 本文介绍了配对设计中,当主要研究指标为连续变量时,如何使用PASS15软件进行两样本均数比较的样本含量估计。以治疗老年高血压为例,详细解释了参数设置和计算过程,结果显示至少需要26例患者以达到统计学显著性。
本文介绍了配对设计中,当主要研究指标为连续变量时,如何使用PASS15软件进行两样本均数比较的样本含量估计。以治疗老年高血压为例,详细解释了参数设置和计算过程,结果显示至少需要26例患者以达到统计学显著性。
配对设计的两样本均数比较的样本含量估计
配对设计由于其所需样本量较小,容易捕捉阳性的结果等,是一种医学上常见的研究设计。常见于单组人群前后对比研究,或者相似的个体匹配形成两组,针对干预措施进行研究。
在配对设计中,其主要研究指标一般在两组数据中成对出现,这些成对数据通常有三种可能的来源形式,当数据来自同一个体,则叫做自身配对设计;当数据来自母体相同的两个个体,叫做同源配对设计;当数据来自条件接近的两个个体,则叫做条件相近配对设计。
当主要研究指标为连续变量时,其样本含量的计算公式主要有两种情况:
单侧:
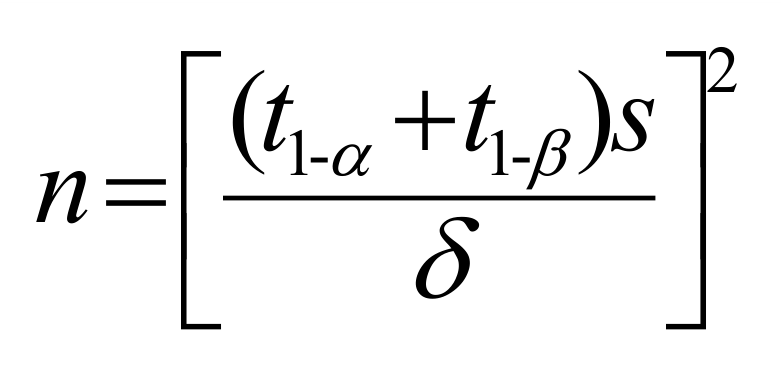
双侧:
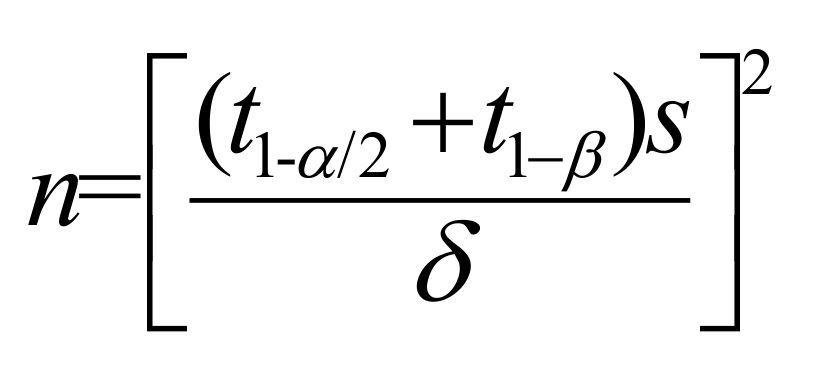
公式中n代表单组设计所需的样本含量,S代表标准公认的总体标准差,δ表示具有临床意义的差值,t1- α/2为t分布概率密度曲线对应的第1-α/2分位数(其他类同)。
本节将主要讲解采用PASS15软件实现配对设计当主要研究指标为连续变量时两样本均数比较的样本含量估计方法。
例:用某药物治疗老年高血压,治疗前平均收缩压为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









