







 本文详细介绍了计算机缓存Cache的三种结构:直接映射、全相联和组相联,以及它们各自的工作原理。直接映射中,地址仅分为tag和blockoffset两部分;全相联结构中,任意tag可存储在任意行,通常需要使用CAM进行匹配;组相联则是两者折衷,结合了直接映射的简单性和全相联的灵活性。此外,文章还提及了受害者Cache的概念,以及CAM(内容寻址存储器)在全相联Cache中的应用。
本文详细介绍了计算机缓存Cache的三种结构:直接映射、全相联和组相联,以及它们各自的工作原理。直接映射中,地址仅分为tag和blockoffset两部分;全相联结构中,任意tag可存储在任意行,通常需要使用CAM进行匹配;组相联则是两者折衷,结合了直接映射的简单性和全相联的灵活性。此外,文章还提及了受害者Cache的概念,以及CAM(内容寻址存储器)在全相联Cache中的应用。
目录
2.3 set-Associative mapping cache
2.CAM(content addressable memory)原理
1.cache的组成
假设内存容量为2^m bytes,内存地址为m位,寻址范围为0~2^m-1.
可以把内存地址分为以下三个区间:

tag,set index,和block offset的意义如下,他们共同描述了给定内存地址所对应的数据在cache中的位置。
下图给出了cache结构,是一个E-way S-set的cache。 又将这个cache成为E路S组的cache。每个cache block(cache line)为B byte。
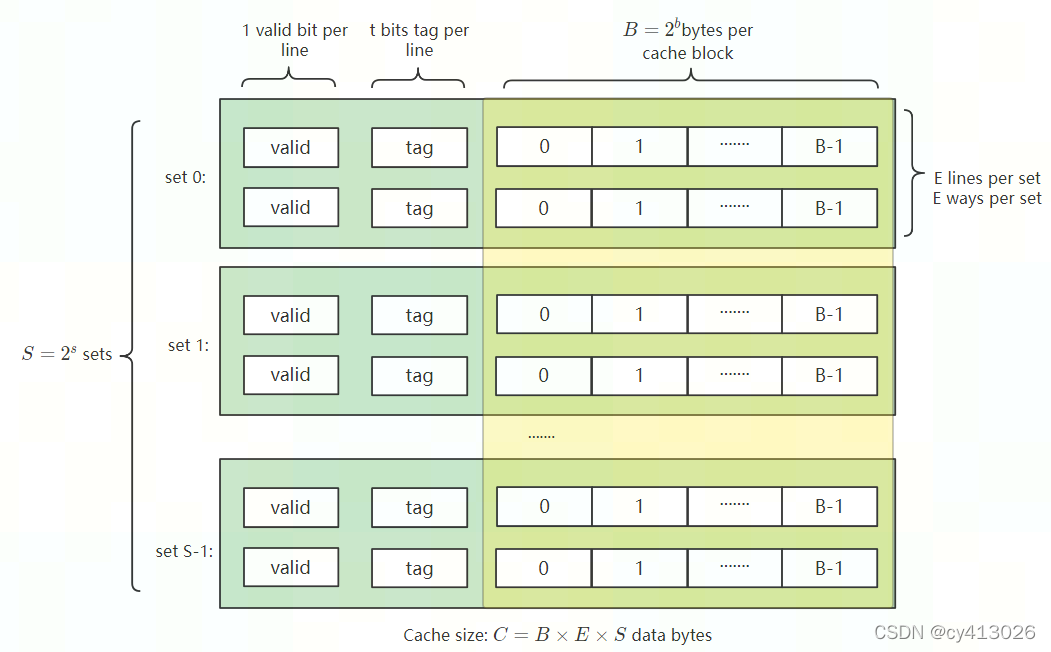
其中上图的黄色部分被称作cache line。Cache存储数据是固定大小为单位的,称为一个Cache entry,这个单位称为Cache line或Cache block。
由地址分割知道同一组(set)的cache line具有相同的set index,所以先有set index确定数据处于哪一set;然后组内的E ways有不同的tag号,所以组内根据tag号定位到确定的cache line。也就是说组内的cache line可以放在任意位置。最后根据block offset在cache line中找到具体的byte位置。
可参考blog 计算机缓存Cache以及Cache Line详解 https://zhuanlan.zhihu.com/p/37749443
https://zhuanlan.zhihu.com/p/37749443
2.cache的三种结构
cache有三种结构,分别是:
1.直接相连 Direct mapping cache
2.全相联 Associative mapping cache或者又叫做全相关cache
3.组相联 set-Associative mapping cache 或者又叫做集相关cache
2.1 Direct mapping cache
直接相连的cache没有set和way的概念。地址只分为了2部分
【这种存储和普通的SRAM存储类似,可以直接由内存地址得到cache line地址】
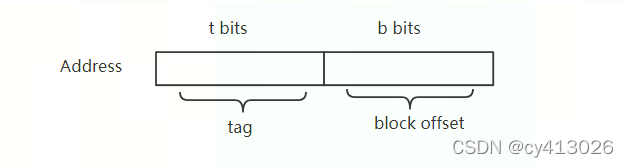
上图给出了直接映射的cache,没有set。给定t bit的tag号之后,对应的数据存储位置就固定了,该cache共E lines。设当前数据的地址高t bit为则,应该在第
行,如果检查该行的cache line tag号不等于
,说明cache miss,需要读写main memory。
在直接相连的cache中,如果需要的两个cache line数据存储在同一地址,这时这个地址只能存储一个cache line,如果出现交替使用这两个cache line就会出现一直在miss的情况,也有统计显示在直接mapping中刚被替换的cache line,经常会被再次使用。为了解决上述问题就有了victim cache的概念。
2.2.1 victim cache(受害者cache)
在直接mapping的cache中,用一个小的全联通cache来存储刚刚被替换的cache line(victim cache line).这个victim cache通常只有4~32个cache line(cache block).
Victim Cache有两个特点:1)块的数量很少;2)使用全相关
但这个使用方法并没有被推广,这主要是因为Victime Cache提出的那个时代,受限于集成电路技术,Cache的规模都非常小。而等到Victim Cache理论和实践都成熟之后,集成电路技术也有了很大的进展。这时候已经出现了大容量的L1 Cache和L2 Cache,所以Victim Cache并没有推广开来。
目前发现在arm A78的cpu中是有victim cache的。
2.2 Full-Associative mapping cache
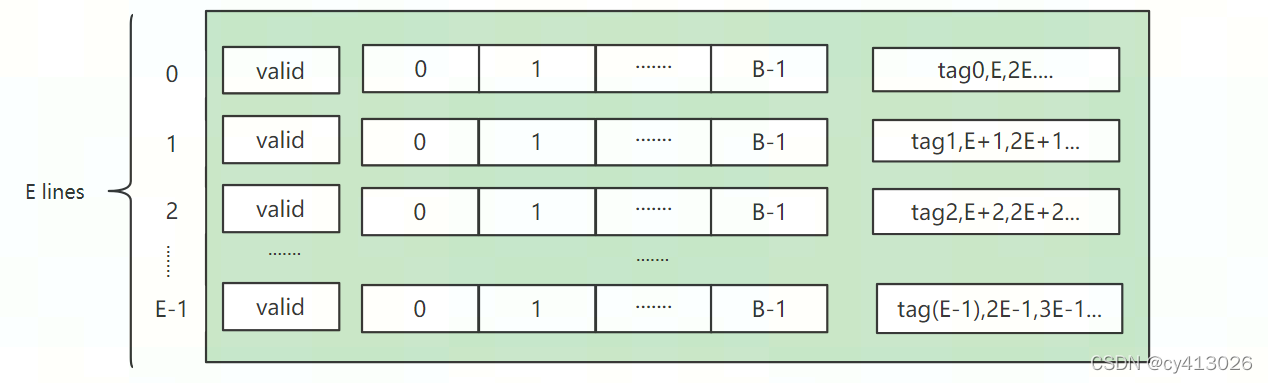
全相连mapping的cache也没有set的概念,和direct mapping的区别在于,对于任意一个tag号,可以存储在cache mem的任意一行。这种结构也是将数据地址分为tag和block offset两部分。
但是相比于直接相连cache,由于cache line的存储没有规则,所以在cache mem中匹配数据时需要比对所有的tag号,对于cache line较多的情况下就需要使用专用电路。
这个电路就是CAM (content addressable memory)基于内容寻址的存储器。
2.3 set-Associative mapping cache
组连接cache是直接cache和全连接cache的折衷方案,其结构在第一节 cache的组成中给出。其实direct mapping cache和Associative mapping cache都可以看作是set-Associative mapping cache的一种特例。
对于直接相连cache,可以认为是tag bit width=0;m=s+b;此时根据s的低 bit确定当前数据在cache mem中哪一行,然后比对整个tag是否match,不match则miss。
对于全连接cache,可以认为是set index bit width=0;m=t+b;此时需要匹配全部t bit的tag号来查询cache mem。
2.CAM(content addressable memory)原理
常规的RAM都是根据给定地址,根据地址查询存储器中的数据;而CAM恰恰相反,是根据给定的内容(数据)来查询对应的地址。CAM的一个地址存储一个数据,但是相同的数据可以存储在多个地址当中。
CAM常用于路由器的地址交换表中,由内容ip地址查询item的地址,在用查询而得的地址读取mem找到对应该IP地址的更多信息。
另一种就是运用于全连接的cache中,通过输入的tag查询该tag对应的cache line地址(如果没有则miss),再通过该cache line地址在cache中得到数据。
定义一个位宽为深度为
的
的CAM。
CAM有两种实现方法,一种是基于SRL16E(最大16位移位的移位寄存器是Xilinx FPGA的一个原语cell);另一种是基于RAM的实现(在这里说一下有的会说是BRAM(block RAM),其实这是FPGA才用到的说法用以和以LUT实现的Distributed RAM(分布式RAM)做区分)。在这里我们介绍基于RAM的实现方式。
设CAM深度,宽度
,则对应的该CAM可以对应查找位宽为
(对应为内容),深度为4的SRAM。下表给出ram_data,ram_addr,cam_data,cam_addr的相对关系。
| ram_data 3bit数据 | ||
| ram_addr | 2'b00 | 3'b110 |
| 2'b01 | 3'b000 | |
| 2'b10 | 3'b100 | |
| 2'b11 | 3'b000 |
图2-1 ram_addr与存储的3bit ram_data
| cam_data 4bit数据独热码表示(0~3) | |||||
| 0 | 1 | 2 | 3 | ||
| cam_addr | 3'b000 | 0 | 1 | 0 | 1 |
| 3'b001 | 0 | 0 | 0 | 0 | |
| 3'b010 | 0 | 0 | 0 | 0 | |
| 3'b011 | 0 | 0 | 0 | 0 | |
| 3'b100 | 0 | 0 | 1 | 0 | |
| 3'b101 | 0 | 0 | 0 | 0 | |
| 3'b110 | 1 | 0 | 0 | 0 | |
| 3'b111 | 0 | 0 | 0 | 0 | |
图2-2 cam_addr与存储的4bit数据
由图2-1知道ram_addr的地址1和地址3存储数据内容3'b000;ram_addr的地址0存储数据内容3'b110;ram_addr的地址2存储数据内容3‘b100。
那么现在要找到数据内容为3'b000存储在哪一个ram地址中?
一种方法就是将所有的4个ram地址全部读取并作判断,最终得到地址1和地址3。但是这种方法消耗的cycNum和ram的地址深度成正比,ram越深需要的cycNum越多。
另一种方法就是在写ram的时候同时维护一份cam的mem,以ram_data为cam_addr,将ram_addr的地址以独热码的形式作为cam_data。
所以cam_addr=3'b110的数据是独热码形式的0,即4'b0001;
cam_addr=3'b000的数据是独热码形式的1,即4'b0010;
cam_addr=3'b100的数据是独热码形式的2,即4'b0100
cam_addr=3'b000,发现3'b000已经有有效数据,此时需要读出该有效数据,并于当前的数据3的独热码4'b1000计算或得到4'b1010,然后将数据4'b1010写到cam_addr=3'b000。
ram和cam更新完成后,现在需要找到ram_data=3'b000的地址,则可以将3'b000作为cam的地址,读出cam_addr=0的数据为4'b1010,用组合逻辑(编码器)将4'b1010转为2'b01和2'b11即可(用移位寄存器来转换时间和直接读取ram是一样的,意义不大)。
2.1 参考文档
CAM(Content-Addressable Memory)介绍https://blog.csdn.net/qq_42322644/article/details/109170011 这篇文章给出了FPGA中基于ram构成的CAM,假设给定{ram_data, ram_addr}={[9:0], [4:0]},总共地址空间为[14:0]共15bit。所以该文章给出的电路有一个 1bit wide x 32K deep的write Port A和一块32 bit wide x 1024 deep的write port B。
这两片ram都是=32K bit的容量。
在描述写32K x 1的 write Port A时,说明给出{ram_data,ram_addr}就可以将write Port A的该地址置为1.其实是因为ram使用了所有[4:0]bit表示的所有地址空间,更普遍性的描述这个实际地址camA_addr=。
在以上的例子中,所以{ram_data, ram_addr}的拼位就是正确的32K x 1的write Port A的地址。
在描述读1024 x 32的write port B时,camB_addr=ram_data。
问题在于上面参考文章给的 write port A和write port B这两个mem一个只用到了写,另外一个只用到了读,两个mem之间数据没有交互,通过文章的描述也没搞清楚write port B的数据是从哪里来的。

















 2473
2473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









