







learning_rate
loss函数设为L=f(x)-y,要求的就是L的最小值,用梯度下降法,x=x-adL/dx,x为单变量时就是导数,x为多变量时,dL/dx为loss函数的梯度,就是loss函数值增长最快的方向,于是x减去a梯度就向着极小值逼近了一点,每次逼近多少?就是a,也就是每次逼近极小值的步长,叫做learning_rate.
weight_decay
权重衰减。理解不深,只是直观上的感觉。
c0是原来的那个损失函数,c是新的损失函数,加入了一项新的东西。其中λ就是权重衰减系数,n是w参数的个数,也就是损失函数在原来的基础上加上了一个参数w的平方和。
新的损失函数智慧对权重w产生影响,不会影响bias,求梯度可以看出这一点。
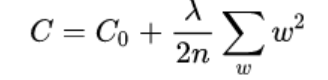
下图就是权重w不断向真实值逼近的过程,比原来多减了一项,原来是1w,现在w变小了,也就是权重衰减了,最后求出来的权重w就会变小了,目的是防止过拟合。为什么呢?我的个人理解是这样的:
拟合出来的函数是y=wx+b,w越大,说明最后的曲线越陡峭,最后弯弯曲曲,就容易过拟合,但是w变小了,曲线各个部分斜率变小,曲线救更加平滑,不容易过拟合。
对于w中,不知道有没有二次方、三次方,如果有的话还可以让高次项减少的更多,让它调整的时候更不敏感。

momentum
在loss在向着最小值逼近的过程中,那些梯度比较小的地方,参数w更新的幅度比较小,训练变得漫长,或者收敛慢.有时候遇到非最优的凸点,会出现冲不出去的现象.
而冲量加进来是一种快速效应.借助上一次的势能来和当前的梯度来调节当前的参数w。
v = momentum * v - learning_rate * gradient
w =w + v
其中v被初始化为0.















 8618
8618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









