










摘要
通过对比图的结构视图,引入了一种学习节点级和图级表示的自监督方法。我们表明,将视图数量增加到两个以上或对比多尺度编码并不能提高性能,最佳性能是通过对比一阶邻居和图扩散的编码实现的。
1 引言
本文介绍了一种自监督方法,通过最大化图的不同结构视图编码的表示之间的MI来训练图编码器。
- 增加视图的数量,即增强,到两个以上并没有提高性能,最好的性能是通过对比一阶邻居和一般的图扩散的编码;
- 与对比图-图或多尺度编码相比,跨视图的对比节点和图编码在节点和图分类任务上都取得了更好的结果;
- 与分层图池化方法(例如可微池(DiffPool))相比,一个简单的图读出层在节点和图分类任务上都取得了更好的性能;
- 应用正则化(early-stopping除外)或归一化层对性能有负面影响。
2 相关工作
图扩散网络(Graph Diffusion Networks):
GDN协调空间消息传递和广义图扩散,其中扩散作为去噪滤波器允许消息通过高阶邻域。
根据扩散的阶段可以将GDN分为早期和晚期融合模型。
早期融合模型使用图扩散来决定邻居,例如,图扩散卷积(GDC)用稀疏扩散矩阵代替图卷积中的邻接矩阵。
晚期融合模型将节点特征映射到潜在空间,然后传播基于扩散的学习表示。
3 方法
受视觉表示学习中多视图对比学习的启发,我们的方法通过最大化一个视图的节点表示和另一个视图的图表示之间的MI来学习节点和图表示,反之亦然,与对比全局或多尺度编码相比,该方法在节点和图分类任务上都获得了更好的结果。

如图1所示,我们的方法由以下组件组成:
- 一种将样本图转换为同一图的相关视图的增强机制。我们只将图的增强应用于结构,而不是初始节点特征。然后是一个采样器,该采样器对两个视图中的相同节点进行子采样,类似于视觉领域的裁剪。
- 两个专用的GNN(即图编码器),每个视图一个,接着是一个共享的MLP(即投影头),以学习两个视图的节点表示。
- 一个图池化层(即读出函数),接着是一个共享的MLP(即投影头),以学习两个视图的图表示。
- 一个鉴别器,它将一个视图的节点表示与另一个视图的图表示进行对比,反之亦然,并对它们之间的一致性进行评分。
3.1 增强
我们可以考虑图上的两种增强方法:
- 作用于初始节点特征上的特征-空间增强,例如掩蔽或添加高斯噪声;
- 通过 ┌ \ulcorner ┌添加或删除连接 ┘ \lrcorner ┘、 ┌ \ulcorner ┌子采样 ┘ \lrcorner ┘或 ┌ \ulcorner ┌使用最短距离或扩散矩阵生成全局视图 ┘ \lrcorner ┘,对图结构进行操作的结构-空间增强和损坏。
第一个增强可能会出现问题,因为许多基准测试不具有初始节点特征。此外,我们观察到,在任何一个空间上掩蔽或添加噪声都会降低性能。因此,我们选择 ┌ \ulcorner ┌生成一个全局视图,然后进行子采样 ┘ \lrcorner ┘。
我们的经验表明,在大多数情况下最好的结果是这样获得的:将邻接矩阵转换为扩散矩阵,并将这两个矩阵视为同一图结构的两个合同(congruent)视图。我们推测,由于邻接矩阵和扩散矩阵分别提供了图结构的局部和全局视图,因此从这两个视图中学习到的表示之间的一致性最大化,允许模型同时编码丰富的局部和全局信息。
扩散公式如下所示:
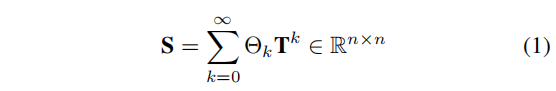
其中,
T
∈
R
n
×
n
\pmb{T}∈\mathbb{R}^{n×n}
TTT∈Rn×n是广义转换矩阵,
Θ
Θ
Θ是决定全局-局部信息比值的权重系数。引入
∑
k
=
0
∞
θ
k
=
1
,
θ
k
∈
[
0
,
1
]
\sum_{k=0}^∞\theta_k=1,\theta_k∈[0,1]
∑k=0∞θk=1,θk∈[0,1]以及
λ
i
∈
[
0
,
1
]
\lambda_i∈[0,1]
λi∈[0,1](
λ
i
\lambda_i
λi是
T
\pmb{T}
TTT的特征值),保证收敛性。
给定一个邻接矩阵
A
∈
R
n
×
n
\pmb{A}∈\mathbb{R}^{n×n}
AAA∈Rn×n和一个对角度矩阵
D
∈
R
n
×
n
\pmb{D}∈\mathbb{R}^{n×n}
DDD∈Rn×n,Personalized PageRank (PPR) 和 heat kernel,即广义图扩散的两个实例,分别通过设置
T
=
A
D
−
1
\pmb{T}=\pmb{A}\pmb{D}^{-1}
TTT=AAADDD−1,
θ
k
=
α
(
1
−
α
)
k
\theta_k=\alpha(1-\alpha)^k
θk=α(1−α)k和
θ
k
=
e
−
t
t
k
/
k
!
\theta_k=e^{-t}t^k/k!
θk=e−ttk/k!来定义,其中
α
α
α表示随机游走中的传输概率,
t
t
t表示扩散时间。heat 和 PPR diffusion 的封闭式解见公式(2)和式(3):
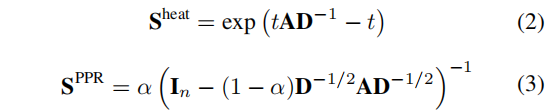
对于子采样,我们从一个视图中随机采样节点及其边,并从另一个视图中选择准确的节点和边。这个过程允许我们的方法应用于不适合GPU内存的图的inductive任务,也可以通过将子样本视为独立的图来应用于转换任务。
3.2 编码器
我们的框架允许网络架构的各种选择,而没有任何约束。为了简单起见,我们选择了常用的GCN作为我们的基本图编码器。如图1所示,我们为每个视图使用一个专用的图编码器,即 g θ ( . ) , g w ( . ) : R n × d x × R n × n → R n × d h g_{\theta}(.),g_w(.):\mathbb{R}^{n×d_x}×\mathbb{R}^{n×n}→\mathbb{R}^{n×d_h} gθ(.),gw(.):Rn×dx×Rn×n→Rn×dh。我们将邻接矩阵和扩散矩阵视为两个congruent的结构视图,并将GCN层定义为 σ ( A ~ X Θ ) \sigma(\widetilde{\pmb{A}}\pmb{X}\pmb{Θ}) σ(AAA XXXΘΘΘ)和 σ ( S X Θ ) \sigma(\pmb{S}\pmb{X}\pmb{Θ}) σ(SSSXXXΘΘΘ),以学习两组分别对应于其中一个视图的节点表示。 A ~ = D ^ − 1 / 2 A ^ D ^ − 1 / 2 ∈ R n × n \widetilde{\pmb{A}}=\hat{\pmb{D}}^{-1/2}\hat{\pmb{A}}\hat{\pmb{D}}^{-1/2}∈\mathbb{R}^{n×n} AAA =DDD^−1/2AAA^DDD^−1/2∈Rn×n是对称归一化的邻接矩阵, D ^ ∈ R n × n \hat{\pmb{D}}∈\mathbb{R}^{n×n} DDD^∈Rn×n是 A ^ = A + I N \hat{\pmb{A}}=\pmb{A}+\pmb{I}_N AAA^=AAA+IIIN的度矩阵( I N \pmb{I}_N IIIN是单位矩阵), S ∈ R n × n \pmb{S}∈\mathbb{R}^{n×n} SSS∈Rn×n是扩散矩阵, X ∈ R n × d x \pmb{X}∈\mathbb{R}^{n×d_x} XXX∈Rn×dx是初始节点特征, Θ ∈ R d x × d h \pmb{Θ}∈\mathbb{R}^{d_x×d_h} ΘΘΘ∈Rdx×dh是网络参数, σ \sigma σ是PReLU。
MLP:全连接神经网络
然后,将学习到的表示输入一个共享的投影头 f ψ ( . ) : R n × d h → R n × d h f_\psi(.):\mathbb{R}^{n×d_h}→\mathbb{R}^{n×d_h} fψ(.):Rn×dh→Rn×dh,这是一个具有两个隐藏层和PReLU的MLP。这就得到了两组节点表示 H α , H β ∈ R n × d h \pmb{H}^α,\pmb{H}^β∈\mathbb{R}^{n×d_h} HHHα,HHHβ∈Rn×dh,它们对应于同一图的两个congruent视图。
对于每个视图,我们将GNN学到的节点表示(在投影头之前)使用一个图池化(读出)函数
P
(
.
)
:
R
n
×
d
h
→
R
d
h
\mathcal{P}(.):\mathbb{R}^{n×d_h}→\mathbb{R}^{d_h}
P(.):Rn×dh→Rdh聚合为一个图表示。我们使用一个类似于JK-Net的读出函数,其中我们将每个GCN层中的节点表示的总和连接起来,然后将它们输入到一个单层前馈网络,以在节点和图表示之间具有一致的维度大小:
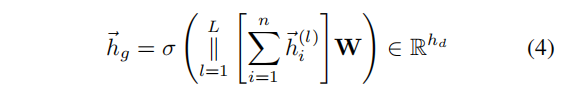
其中,
h
⃗
i
(
l
)
\vec{h}^{(l)}_i
hi(l)是节点
i
i
i在第
l
l
l层的隐藏表示,
∣
∣
||
∣∣是连接操作,
L
L
L是GCN层数,
W
∈
R
(
L
×
h
d
)
×
h
d
\pmb{W}∈\mathbb{R}^{(L×h_d)×h_d}
WWW∈R(L×hd)×hd是网络参数,
σ
\sigma
σ是PReLU。在实验中,我们展示了与更复杂的图池化方法(例如,DiffPool)相比,该池化方法取得了更好的结果。
然后,将上述表示输入到一个共享的投影头 f ϕ ( . ) : R d h → R d h f_\phi(.):\mathbb{R}^{d_h}→\mathbb{R}^{d_h} fϕ(.):Rdh→Rdh,这是一个具有两个隐藏层和PReLU的MLP,得到最终的图表示: h ⃗ g α , h ⃗ g β ∈ R d h \vec{h}^{\alpha}_g,\vec{h}^{\beta}_g∈\mathbb{R}^{d_h} hgα,hgβ∈Rdh。
我们汇总两个视图上的节点和图级别表示: h ⃗ = h ⃗ g α + h ⃗ g β ∈ R n \vec{h}=\vec{h}^{\alpha}_g+\vec{h}^{\beta}_g∈\mathbb{R}^n h=hgα+hgβ∈Rn【?】和 H = H α + H β ∈ R n × d h \pmb{H}=\pmb{H}^α+\pmb{H}^β∈\mathbb{R}^{n×d_h} HHH=HHHα+HHHβ∈Rn×dh,并将它们分别作为图和节点表示,用于下游任务。
3.3 训练
目标如下:
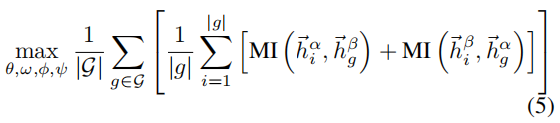
其中,
θ
,
w
,
ϕ
,
ψ
\theta,w,\phi,\psi
θ,w,ϕ,ψ是图编码器和投影头参数,
∣
G
∣
|\mathcal{G}|
∣G∣是训练集中图的数量或transductive设置中子采样图的数量,
∣
g
∣
|g|
∣g∣是图
g
g
g中节点的数量。
MI被建模为鉴别器 D ( . , . ) : R d h × R d h → R \mathcal{D}(.,.):\mathbb{R}^{d_h}×\mathbb{R}^{d_h}→\mathbb{R} D(.,.):Rdh×Rdh→R,它从一个视图获取节点表示,从另一个视图获取图表示,并对它们之间的一致性进行评分。 我们简单地将鉴别器作为两个表示之间的点积来实现: D ( h ⃗ n , h ⃗ g ) = h ⃗ n . h ⃗ g T \mathcal{D}(\vec{h}_n,\vec{h}_g)=\vec{h}_n.\vec{h}^T_g D(hn,hg)=hn.hgT。我们观察到,当鉴别器和投影头集成到双线性层时,节点分类基准略有改进。为了确定MI估计器,我们研究了四个估计器,并为每个基准选择了最好的一个估计器。
正样本来自联合分布 x p ∼ p ( [ X , τ α ( A ) ] , [ X , τ β ( A ) ] ) x_p∼p([\pmb{X},\tau_\alpha(\pmb{A})],[\pmb{X},\tau_\beta(\pmb{A})]) xp∼p([XXX,τα(AAA)],[XXX,τβ(AAA)]),负样本来自边缘分布的乘积 x n ∼ p ( [ X , τ α ( A ) ] ) p ( [ X , τ β ( A ) ] ) x_n∼p([\pmb{X},\tau_\alpha(\pmb{A})])p([\pmb{X},\tau_\beta(\pmb{A})]) xn∼p([XXX,τα(AAA)])p([XXX,τβ(AAA)])。为了在transductive任务中生成负样本,我们随机清洗特征。最后,我们利用小批量随机梯度下降对模型参数进行了优化。
假设一组训练图
G
\mathcal{G}
G,其中一个样本图
g
=
(
A
,
X
)
∈
G
g=(\pmb{A},\pmb{X})∈\mathcal{G}
g=(AAA,XXX)∈G由一个邻接矩阵
A
∈
{
0
,
1
}
n
×
n
\pmb{A}∈\{0,1\}^{n×n}
AAA∈{0,1}n×n和初始节点特征
X
∈
R
n
×
d
x
\pmb{X}∈\mathbb{R}^{n×d_x}
XXX∈Rn×dx组成,我们提出的多视图表示学习算法总结如下:

4 实验



















 1273
1273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









