









talk
这篇文章是 图对比学习中 常会比较的一篇文章。 原论文中的数据都存在问题,由于dgl的数据集问题,很多人无法在cora复现出86.大多结果都在82-83。文章核心采用 ppnp来进行 视图生成(宏观的视角)。 通过不同视角之间 进行互信息最大化。这里 存在两个projector,存在sample操作。 这是区别于 图对比框架的操作。
1. model
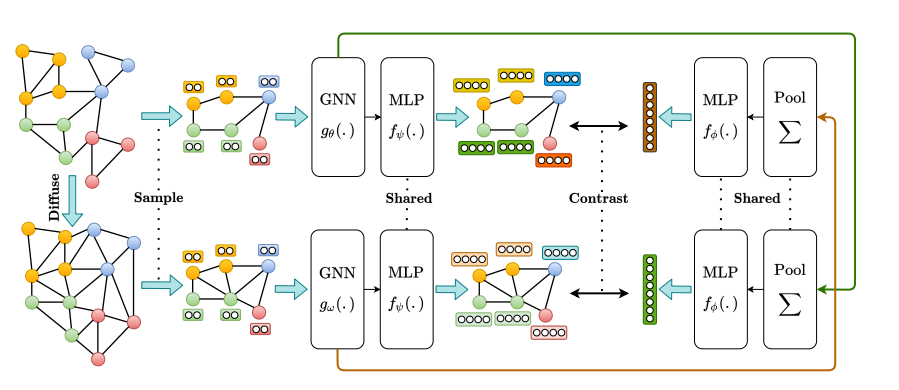
1.1 通过diffusion(PPNP或者热核方程)生成新视角
作者论点:两个视图就是最好的,再多就不能提升了。 这里没有采用APPNP,因此无法可扩展。这里求得S,是在接下来的 encoder中,作为邻接矩阵进行传入,而不是预先计算出SX。
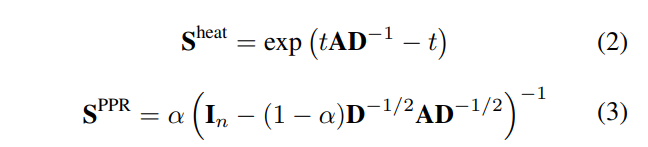
1.2 采样 随机,防止gpu溢出
当获得第二个视图之后,采用采样的操作,来获得两个子图,这里的采样 是通过随机选取节点和边。 同时在另外一个视图,选取相同的节点和边。
1.3 encoder
采用gcn作为编码器,两个视图采用两个不同的编码器。 当获得两个视图的 编码器表征 之后,均送入 到一个 共享的projection head(两层MLP)获得两个视图的 最终表征。

1.4 pool
同时 将编码器表征(没有project前)求和之后(sum) 进行多层堆叠,jknet式,然后拼接(采用横着拼)再乘W转换维度。 i.e. 当只有一层gcn时,这里就是 所有节点的h进行求和,然后通过W进行映射,获得图级表征,这里也是和 DGI等 其他工作 不同的地方。 当获得两个视图图级表征后,送入一个共享参数的 两层mlp进行学习,最终获得图级表征。
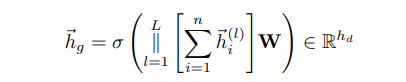
1.5 损失
第一个视图节点h和 第二个视图 图级s。 反之,相当于是 双重 交叉的dgi损失
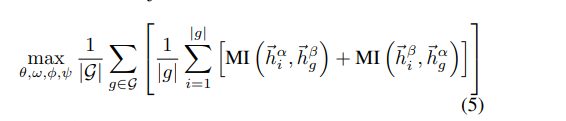
不同于DGI,这里的MI采用的判别器是 两个表征之间的内积,作者观察到,如果采用bilinear,只是轻微改善了效果。同时在实验部分,进行了多个MI estimator的 实验(代码是借鉴了 infograph)
1.6 负采样
借鉴了DGI做法,A不变 shuffleX。 通过生成负样本来 进行判别器训练。

2. 实验
节点级任务
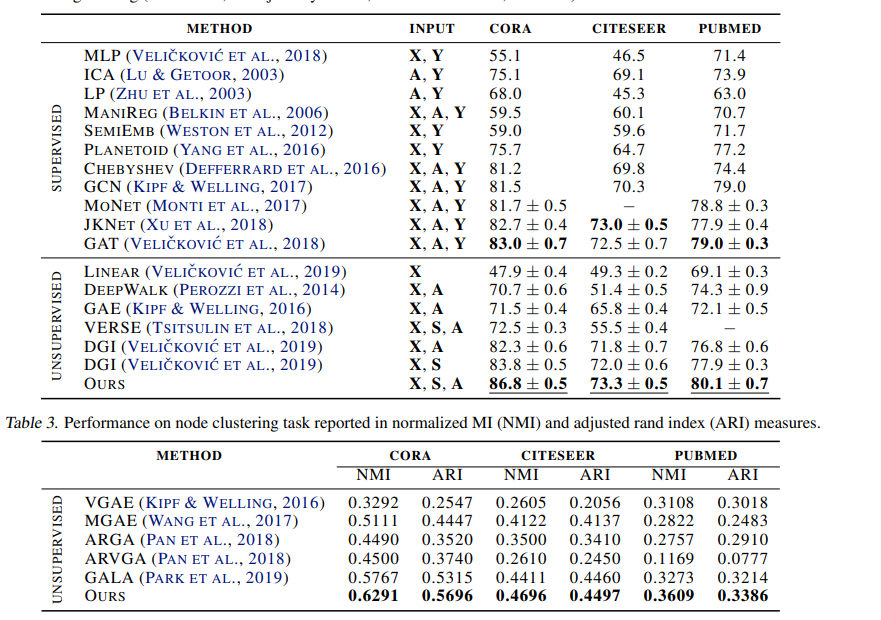
节点分类实验 存在问题,86.8 到2022 年现在,cora上都很难达到,GCNII等变体也在85-86. 这个结果不可复现
聚类结果 我认为也存在 问题, GALA本来就是 一个 有争议的方法,无法复现,也不开源。 作者这里 关于聚类的 其他方法 都是抄表GALA的,他的这三个数据集上的指标,2021CVPR DBGAN都没办法超越。真的能复现吗????
图级任务
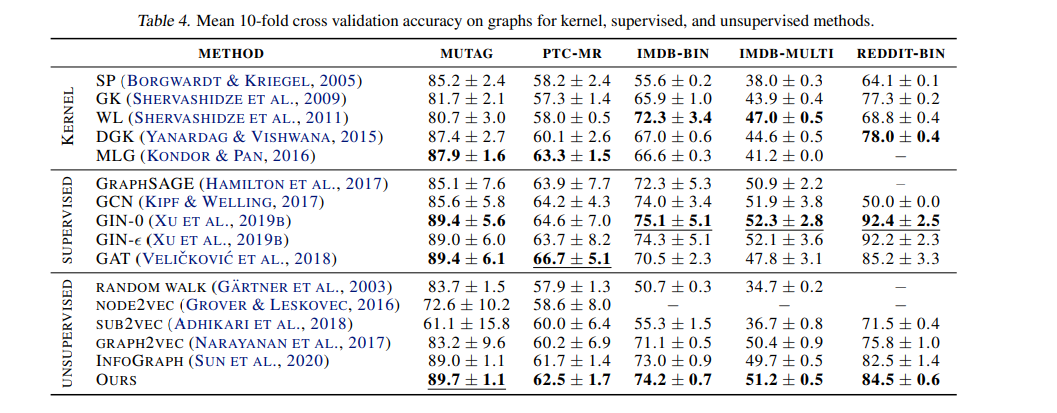
消融
探究了 四种不同的 判别器损失 nce损失 jsd(dgi) nt-xent 带有温度的交叉熵 dv
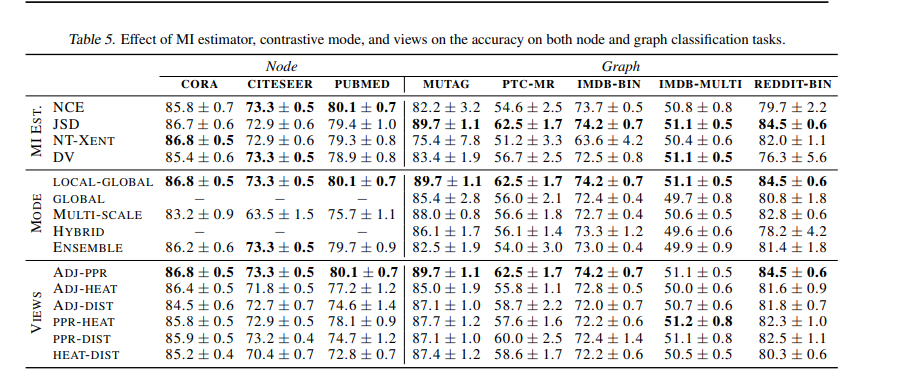
Code
计算 diffusion 矩阵S ppr+ heat_kernel
encoder : dgi的 GCN
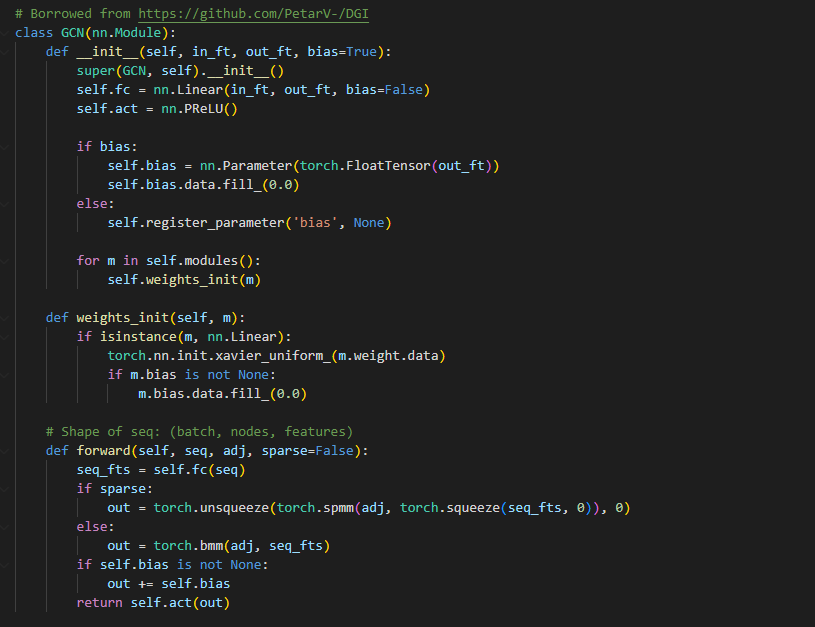
池化: 并没有实现jk-net的池化,和dgi一样。 判别器 这里是 双重dgi 传入两个 c(图级s) h1-4 两个正 两个负 返回的 logits是 把 两个 得分拼起来
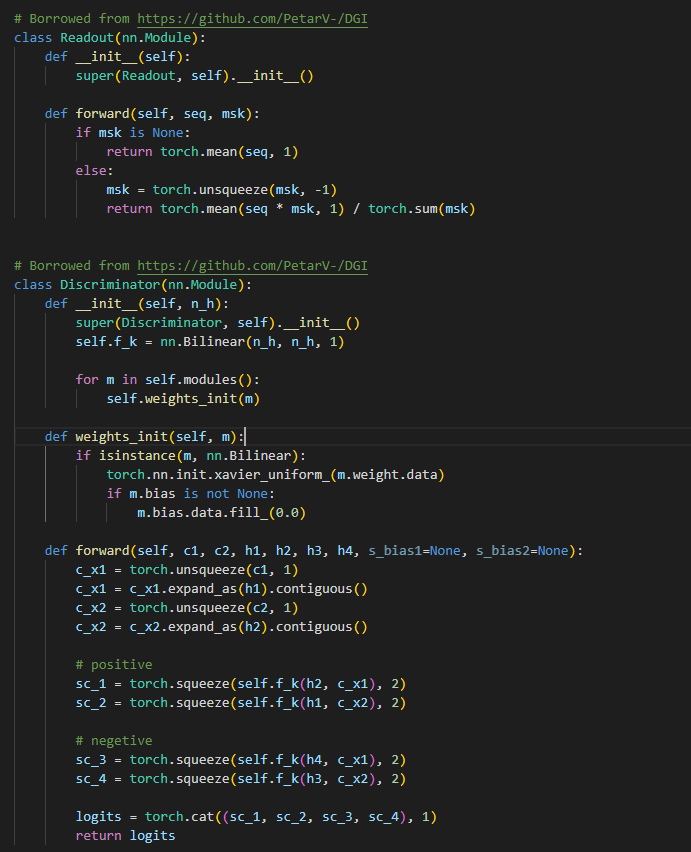
model : 这里传播过程 都是采用了 单层gcn,同时也没有 论文里的 projector head
一层gcn之后 送入池化 获得 图级表征c,h1 h2 正样本 h3 h4负样本, 是seq2计算出来的 seq2 是shufflex
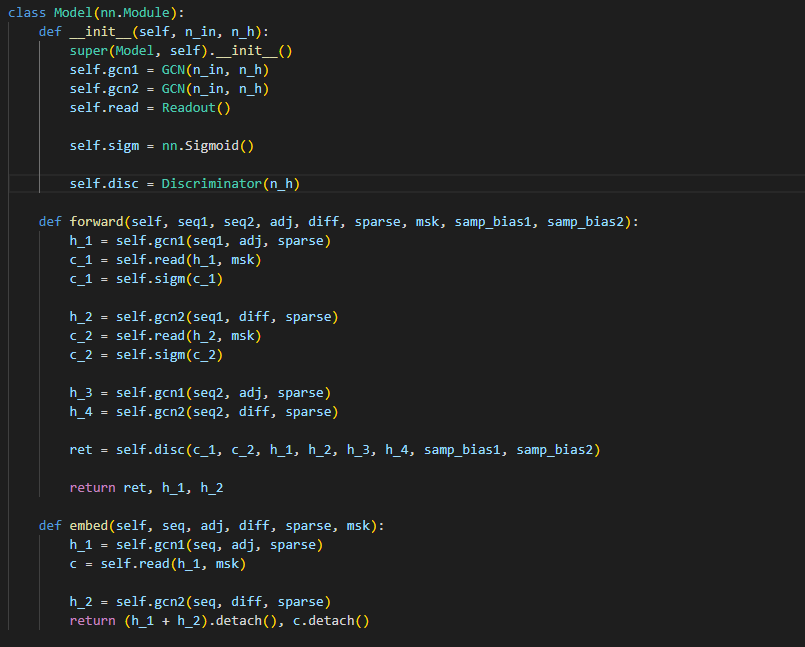
train
ba: adjacency matrix 取邻接矩阵 第i到i+sample_size行 第i到i+sample_size列
bd: diffusion matrix
bf: 特征矩阵 取原特征矩阵的 第i到i+sample_size
这里的 diff 是 在读数据的时候预先计算,和subcon一样,而并不是论文里面写的 计算传播矩阵

这里经过 idx个循环 得到一个 list,每个元素都是矩阵,调整大小为 batchsamplesample 这里的sample就是每个采样的大小,,
这里是 生成batch_size个 大小的 节点下标。从这个下标 开始 一直往后 sample_size个节点 作为采样出来的 节点。
直观上来看 新生成的邻接矩阵是 块状的,原A的子集。 特征矩阵是 连续的原特征的 子集
这里的采样好直接,这样naive的采样 居然不会破坏连通性吗,是因为 数据集 相邻的点 大概率存在边吗?
model的输入 seq1 seq2 这里就和 dgi不一样了,dgi里面都是batch_size =1 这里 有很多batch。
但是具体计算时候,仍然可以使用 DGI里面的 gcn实现传播,dgi的代码 可以通用处理 ppi等
----------------------------------------------last--------------------------------------------
看完文章感觉有一些地方都和dgi不一样,代码里面 实际就是 计算ppr的X(区别)之后,通过两个gcn来传播(区别),并计算损失,又因为 这样计算量太大,所以采用了 这样naive的采样(区别)。 至于文章里面的 projection head 和 jk-pool 都不存在
















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









