









朴素贝叶斯概述
朴素贝叶斯算法就是利用我们在概率论中学习的条件概率公式来处理一些分类问题。朴素贝叶斯 优点:在数据较少的情况下仍然有效,可以处理多类别问题 缺点:对于输入数据的准备方式较为敏感 适用数据类型:标称型数据 朴素贝叶斯算法原理
概率论中有一个大名鼎鼎的概率公式,贝叶斯公式:
推导过程如下:
举一个例子来阐述贝叶斯公式,据统计百分之八十的女孩会留长发,百分之四十的男孩也留长发,通过观察发现大街上的人留长发的比例是0.6,而且男女比例为6:4,某个雨夜交加的夜晚,一个人被抢了,警察询问罪犯性别时,这个人不知道罪犯是男是女,只知道罪犯留着一头飘逸的长发,请问警察怎么判断罪犯的性别?
根据贝叶斯公式我们大致可以判断,罪犯为女性。有一个疑问,为什么男人和女人的概率相加为0.93而不是1呢,剩下的那0.7是什么人,双性人?
问题出在了我们的观察上,由于女人天性喜欢逛街,所以总会在大街上出没,我们在大街上观察的时候当然看到的美女就更多一些,没有做到完全随机,所以0.6的概率和理论值有误差,我只能这么解释了。。。- 示例:使用朴素贝叶斯进行文本分类
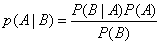
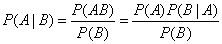


# -*- coding: utf-8 -*-
# Project:Python
# File:Bayes
# Author:mm.liu
# Date:2016-04-29:09:24
# TODO: 利用贝叶斯算法进行分类 p(ci/w)=p(w/ci)p(ci)/p(w)
from numpy import *
class Bayes:
# 获取训练样本
# posting_list是一些留言分词后的文档集合
# class_vec是以上留言的标注分类结果,0-正常言论 1-侮辱性言论
def load_data_set(self):
posting_list = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'hime', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'hime'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'hime'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
class_vec = [0, 1, 0, 1, 0, 1]
return posting_list, class_vec
# 建立词典(词库)
# data_set是存储一批文本语料的集合
# vocab_set是建立好的词库集合
def create_vocab_list(self, data_set):
vocab_set = set([])
for document in data_set:
# 取文档词集合和原有词库的并集,即添加文档中出现的新词
vocab_set = vocab_set | set(document)
return list(vocab_set)
# 将文档转换为词向量,维度是词库的容量
# vocab_list词库集合
# input_set输入的一篇文档词集合
def set_words2vec(self, vocab_list, input_set):
# 初始创建一个维度是词库容量,元素都为0的向量
return_vec = [0] * len(vocab_list)
for word in input_set:
if word in vocab_list:
# 将在词库中存在的词的位置设为1
return_vec[vocab_list.index(word)] = 1
else:
print "单词[%s]未收录到词典!" % word
return return_vec
# 对样本进行训练,获得p(w/ci)和p(ci)等
# 假设w1,w2...wn是相互独立的,所以p(w/ci)=p(w1,w2...wn/ci)=p(w1/ci)p(w2/ci)...p(wn/ci)
def train(self, train_matrix, train_category):
train_docs_num = len(train_matrix)
words_num = len(train_matrix[0])
# 计算侮辱类1的文档总数,从而计算p(c1)的概率,p(c0)=1-p(c1),注意sum是将所有元素求和,应和len函数区分
p_abusive = sum(train_category) / float(train_docs_num)
# 创建长度为words_num,元素为0的矩阵
p0_num = zeros(words_num)
p1_num = zeros(words_num)
p0_denom = 0.0
p1_denom = 0.0
for i in range(train_docs_num):
if train_category[i] == 1:
# 向量中每个元素存储的是某个单词在c1中出现的次数
p1_num += train_matrix[i]
# 计算c1中所有单词总数,同一个词重复计算
p1_denom += sum(train_matrix[i])
else:
p0_num += train_matrix[i]
p0_denom += sum(train_matrix[i])
# 计算每个单词在c1中出现的概率,向量中的一个元素保存一个单词的条件概率p(wi/c1)
p1_vect = p1_num / p1_denom
p0_vect = p0_num / p0_denom
# p1_vect是[p(w1/c1),p(w2/c1)...p(wn/c1)],p0_vect是[p(w1/c0),p(w2/c0)...p(wn/c0)],p_abusive是p(c1)
return p0_vect, p1_vect, p_abusive
# 训练函数改进
# 1.如果某个p(wi/c)的值为0,会导致整个p(w1/ci)p(w2/ci)...p(wn/ci)的乘积为0,
# 所以p_num初始化为1,p_denom初始化为2来避免这种情况
# 2.如果最后求得的概率向量中元素的值太小会造成内存下溢,
# 所以对概率取对数来避免这种情况,log(p(wi/c))和p(wi/c)拥有相同的单调性
def train_better(self, train_matrix, train_category):
train_docs_num = len(train_matrix)
words_num = len(train_matrix[0])
# 计算侮辱类1的文档总数,从而计算p(c1)的概率,p(c0)=1-p(c1),注意sum是将所有元素求和,应和len函数区分
p_abusive = sum(train_category) / float(train_docs_num)
# 创建长度为words_num,元素为0的矩阵
p0_num = ones(words_num)
p1_num = ones(words_num)
p0_denom = 2.0
p1_denom = 2.0
for i in range(train_docs_num):
if train_category[i] == 1:
# 向量中每个元素存储的是某个单词在c1中出现的次数
p1_num += train_matrix[i]
# 计算c1中所有单词总数,同一个词重复计算
p1_denom += sum(train_matrix[i])
else:
p0_num += train_matrix[i]
p0_denom += sum(train_matrix[i])
# 计算每个单词在c1中出现的概率,向量中的一个元素保存一个单词的条件概率p(wi/c1)
p1_vect = log(p1_num / p1_denom)
p0_vect = log(p0_num / p0_denom)
# p1_vect是[p(w1/c1),p(w2/c1)...p(wn/c1)],
# p0_vect是[p(w1/c0),p(w2/c0)...p(wn/c0)],p_abusive是p(c1)
return p0_vect, p1_vect, p_abusive
# 贝叶斯分类函数,假设每个词出现的概率相同,即p(wi)=p(wj)。由于仅比较大小,所以分母p(w)不用计算
# 数学中有公式ln(a*b) = ln(a)+ln(b)由于在训练过程中我们队概率都取了对数,
# 所以有ln(p(w1/ci)p(w2/ci...p(wn/ci))= ln(p(w1/ci))+ln(p(w2/ci))...+ln(p(wn/ci))
# 同理,ln(p(w/ci)p(ci)) = ln(p(w/ci))+ln(p(ci))
def classify(self, vec2_classify, p0_vec, p1_vec, p_class1):
p1 = sum(vec2_classify * p1_vec) + log(p_class1)
p0 = sum(vec2_classify * p0_vec) + log(1.0 - p_class1)
if p1 > p0:
return 1
else:
return 0
def test_classify(self):
posting_list, class_vec = self.load_data_set()
vocab_list = self.create_vocab_list(posting_list)
train_mat = []
for post_in_doc in posting_list:
train_mat.append(self.set_words2vec(vocab_list,post_in_doc))
p0_vec,p1_vec,p_abusive = self.train_better(array(train_mat),array(class_vec))
test_entity = ['stupid', 'garbage']
this_doc = array(self.set_words2vec(vocab_list,test_entity))
print test_entity,'的分类为:',self.classify(this_doc,p0_vec,p1_vec,p_abusive)
bayes = Bayes()
bayes.test_classify()














 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









