






系列文章目录
类别损失权重
前言
不平衡数据集是分类任务中的一个常见问题,其中一个类中的实例数量明显小于另一类中的实例数量。这将导致有偏差的模型在少数群体中表现不佳。
加权损失函数是训练模型时使用的标准损失函数的修改。权重用于对少数类别的错误分类分配更高的惩罚。这个想法是通过增加该类别的错误分类成本来使模型对少数类别更加敏感。
实现加权损失函数的最常见方法是为少数类分配较高的权重,为多数类分配较低的权重。权重可以与类别的频率成反比,使得少数类别获得较高的权重,而多数类别获得较低的权重。
原文链接
一、二元分类
torch.nn.BCEWithLogitsLoss函数是二元分类问题常用的损失函数,其中模型输出是 0 到 1 之间的概率值。它结合了 sigmoid 激活函数和二元交叉熵损失。
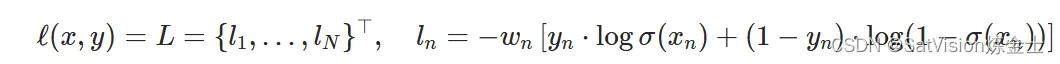
对于不平衡数据集,其中一类中的实例数量明显小于其他类,torch.nn.BCEWithLogitsLoss可以通过向损失函数添加权重参数来修改函数。权重参数允许为正类和负类分配不同的权重。
权重参数是一个大小为2(class)的张量
import torch
import torch.nn as nn
#定义带有权重参数的 BCEWithLogitsLoss 函数
weight = torch.tensor([ 0.1 , 0.9 ]) # 正类的权重更高
criteria = nn.BCEWithLogitsLoss(weight=weight)
#生成一些随机数二元分类问题的数据
input = torch.randn( 3 , 1 )
target = torch.tensor([[ 0. ], [ 1. ], [ 1. ]])
#计算指定权重损失的损失 =标准(输入,目标)打印(损失)
我们将正类的权重设置为 0.9,将负类的权重设置为 0.1。input张量包含模型预测的逻辑。target张量包含二元分类问题的真实标签。
类比权重计算:
类别 i 的权重= 样本总数 / (类别 i 中的样本数 * 类别数)
其中total_samples是数据集中的样本总数,num_samples_in_class_i是类别 i 中的样本数量,num_classes是类别总数(在二元分类的情况下,num_classes为 2)。
注意:计算权重的具体公式和方法可能取决于问题和数据集,并且可能还需要考虑其他方法,例如使用重采样技术或其他旨在处理类别不平衡的损失函数。
除了weight参数之外,torch.nn.BCEWithLogitsLoss还有一个pos_weight参数,这是在二元分类问题中指定正类权重的更简单的方法。
该pos_weight参数是一个标量,表示正类的权重。相当于将weight参数设置为[1, pos_weight],其中负类的权重为 1。
import torch
import torch.nn as nn
#使用 pos_weight 参数定义 BCEWithLogitsLoss 函数
pos_weight = torch.tensor([ 3.0 ]) # 正类的权重较高
criteria = nn.BCEWithLogitsLoss(pos_weight=pos_weight)
#生成一些随机数据二元分类问题
input = torch.randn( 3 , 1 )
target = torch.tensor([[ 0. ], [ 1. ], [ 1. ]])
#使用指定的 pos_weight 计算损失
loss= criteria(输入,目标)打印(损失)
将参数设置pos_weight为3.0,表示正类的权重是负类的3倍。criterion我们使用指定的函数计算损失pos_weight。如果同时指定weight和pos_weight参数,pos_weight则参数优先于正类的权重。如果设置pos_weight为 1.0 以外的值,则weight张量中正类的权重将被忽略。
二、多分类
1.权重计算案例
假设我们有一个包含 1000 个样本的数据集,目标变量分为三类:A 类、B 类和 C 类。数据集中样本的分布如下:
| 类别 | 数量 |
|---|---|
| A类 | 100个样品 |
| B类 | 800个样品 |
| C类 | 100个样品 |
| 为了解决类别不平衡问题,我们可以为每个类别分配与其频率成反比的权重。各类别的权重可按下式计算: | |
| 类别 | 数量 |
| ------ | ------- |
| A类 | 1000 / 100 = 10 |
| B类 | 1000 / 800 = 1.25 |
| C类 | 1000 / 100 = 10 |
2.label_smoothing
在 PyTorch 中torch.nn.CrossEntropyLoss,label_smoothing参数用于平滑 one-hot 编码目标值,以鼓励模型对其预测不太自信并防止过度拟合训练数据。
这种平滑是通过向 one-hot 编码目标值的非对角线元素添加一个小值(即平滑因子)并从对角线元素中减去该相同值来实现的。这会降低模型预测的置信度并鼓励其探索更广泛的解决方案。
总结
label_smoothing和参数都weight可以用来解决多类分类问题中与类不平衡和过度拟合相关的问题。然而,这两个参数的工作方式不同,并且具有不同的用例。
weight参数用于在损失计算中对每个类别应用权重,这在处理不平衡数据集时非常有用。真实类别的权重乘以真实类别的负对数似然,因此代表性不足的类别的损失会增加。weight参数不会影响预测概率或模型对其预测的置信度,而是调整损失计算中分配给每个类别的权重。
label_smoothing参数用于平滑 one-hot 编码目标值,以鼓励模型对其预测不太自信并防止过度拟合训练数据。平滑是通过向 one-hot 编码目标值的非对角线元素添加一个小值(即平滑因子)并从对角线元素中减去该相同值来实现的。这会降低模型预测的置信度,并鼓励模型探索更广泛的解决方案。label_smoothing参数不会影响损失计算中分配给每个类别的权重,而是调整损失计算中使用的目标值。
一般来说,weight参数在处理不平衡的数据集时很有用,其中所有类的错误分类成本并不相同。另一方面,label_smoothing在处理过度拟合和高置信度预测时很有用,其中模型对其预测过于自信并且没有探索广泛的解决方案。
weight\label_smoothing可以一起使用来解决多类分类问题中的类不平衡和过度拟合问题
然而,两个参数可能并不总是一起使用,它们的使用取决于数据集的具体特征和手头的问题。尝试不同的超参数组合(包括label_smoothing和weight)以确定针对给定问题的最佳方法非常重要。



















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











