







神经网络和反向传播
1,为什么说神经网络要比线性分类器好?优势在哪?
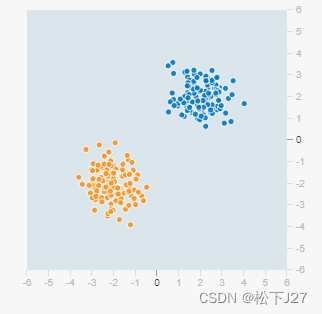
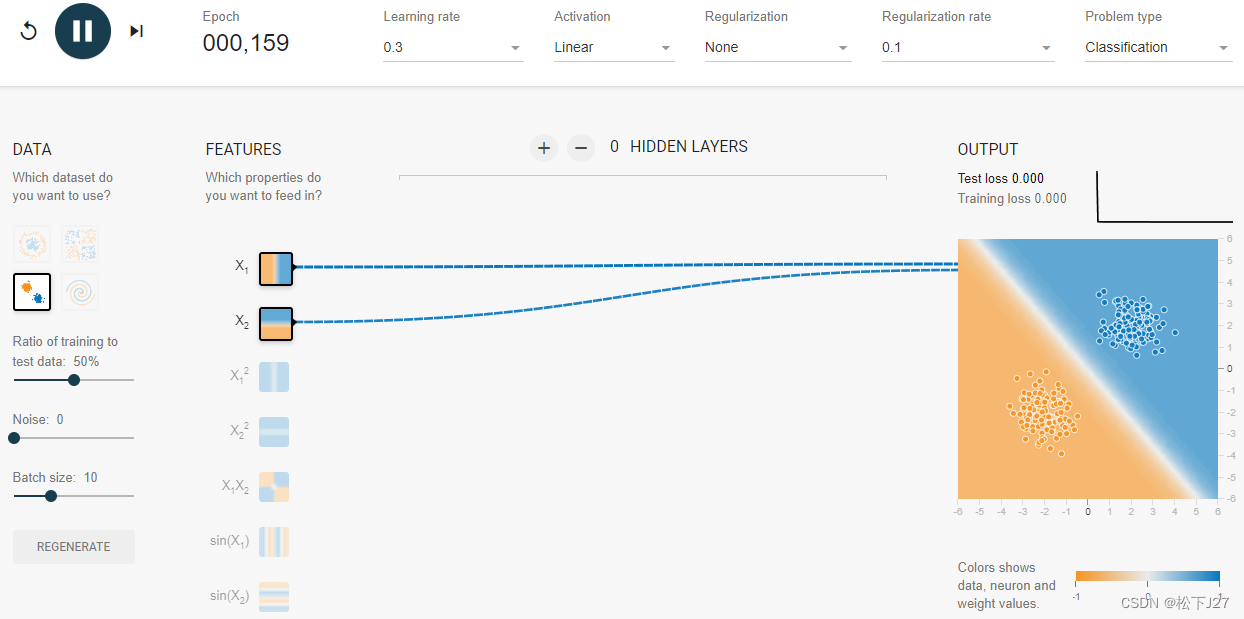
线性分类器只能用直线对数据进行划分。因此当原始数据分布的比较好的时候,如下图所示,用线性分类器就能够很好的把图中的黄点和蓝点分开。
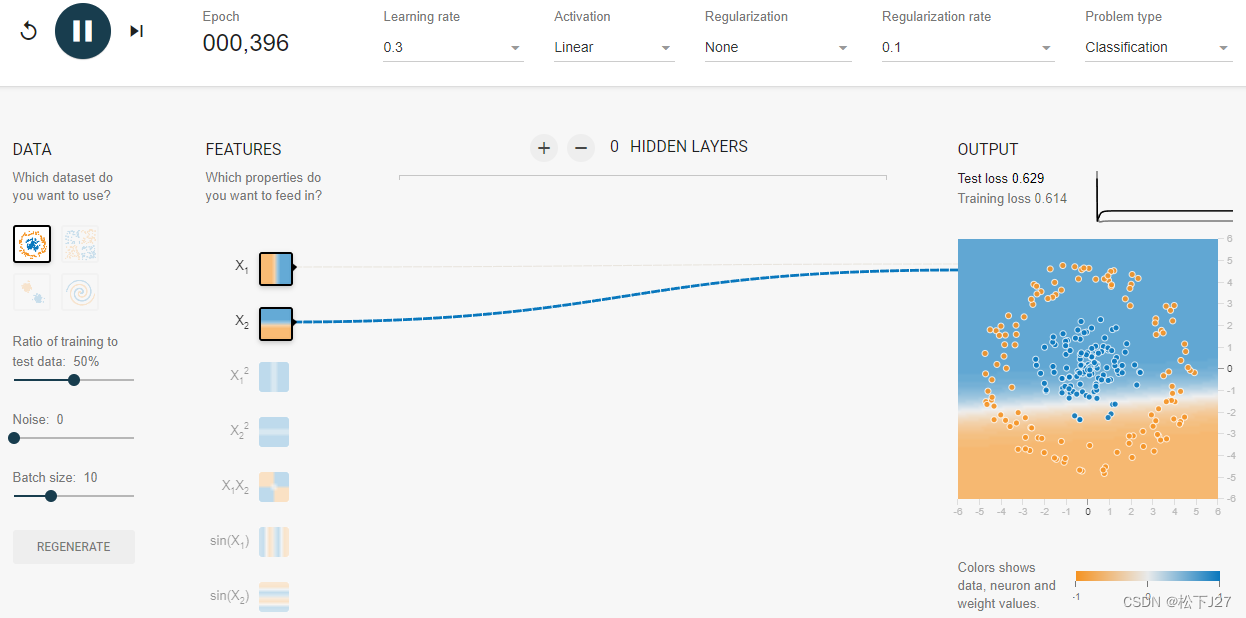
但如果不同种类的数据融合在一起时就不太好用直线去分割了,比如说下图。

或者说是下面这种数据分布

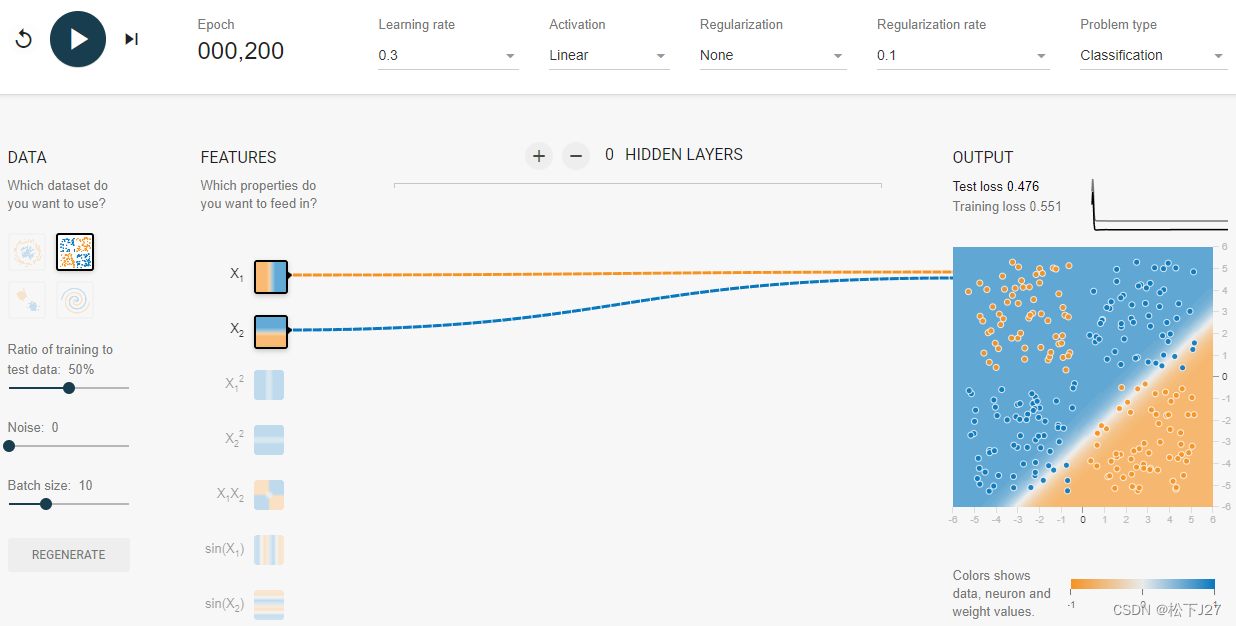
而神经网络的出现主要是引入了非线性计算,也就是这里的max()函数。神经网络中的非线性函数被称之为激活函数activation function用于决定神经元是否有被激活。

有了神经网络以后数据分布的比较复杂的情况就能够用“曲线”去很好的分类了。
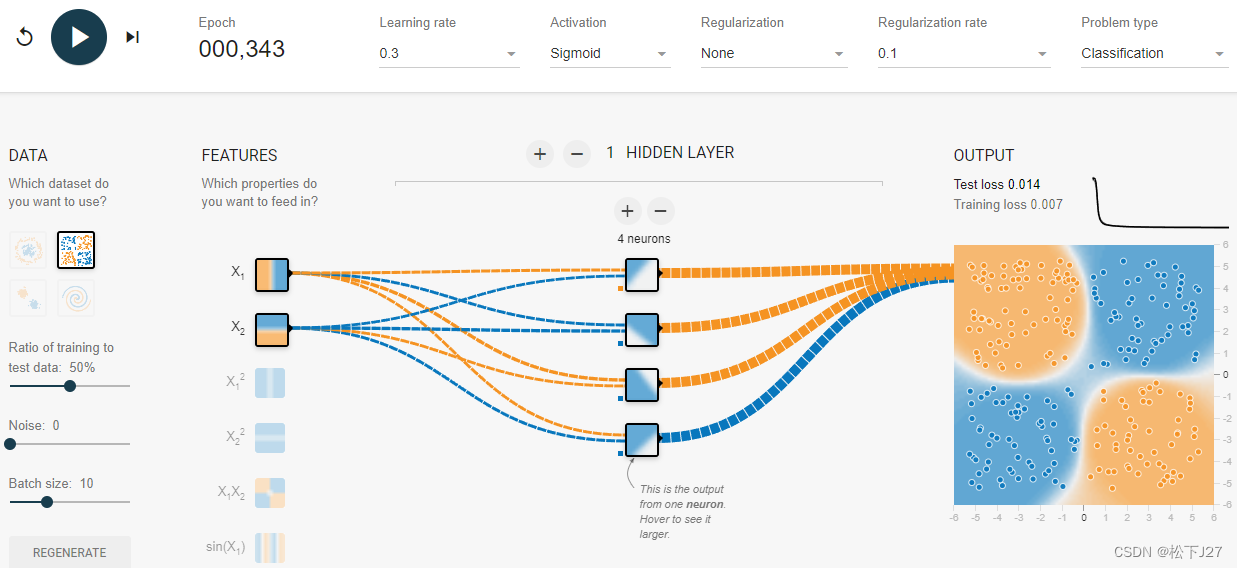
2,神经网络中的非线性激活函数
2,1 非线性激活函数有哪些?

上图给出了几个常见的非线性激活函数,上面例子中所使用的非线性激活函数用的就是ReLU函数。
2,2 引入非线性激活函数的结果是增加了隐含层
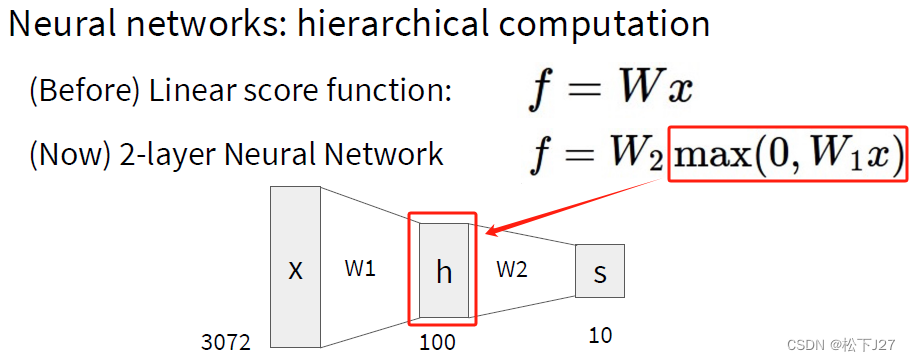
Wx的结果本该是score,但非线性函数的引入改变了分数的概念。


2,3 神经元里面装的是什么?
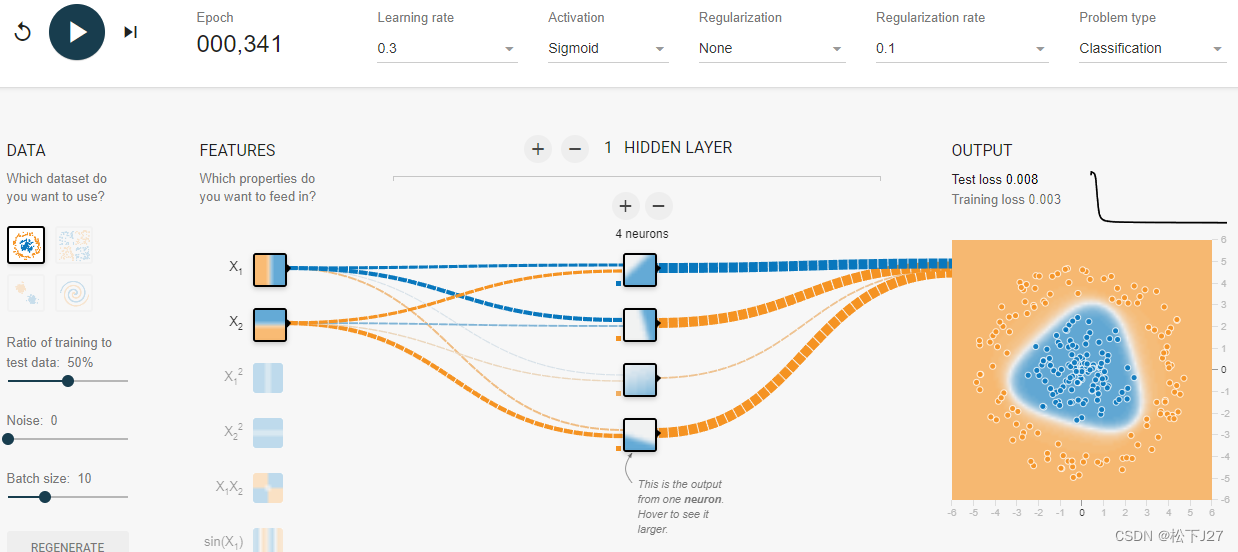
隐含层是由若干个神经元构成的,这些神经元的值就是以wx+b为输入经过激活函数后的输出。这些值随着W的变化而变化,而W又随着损失函数L的减少而不断地修正。最终,当L减少到很小以后,就找到了一组最优的神经元的值。在深度学习中,把这一组一组通过学习后得到的神经元的值称作提取到的“高级/复杂特征”。
比如说,当只有两个两个神经元的时候,通过学习只找到了两个特征,不足以代表数据的特征。

随着神经元的增加,系统所能表征的特征也越丰富。(4个神经元)
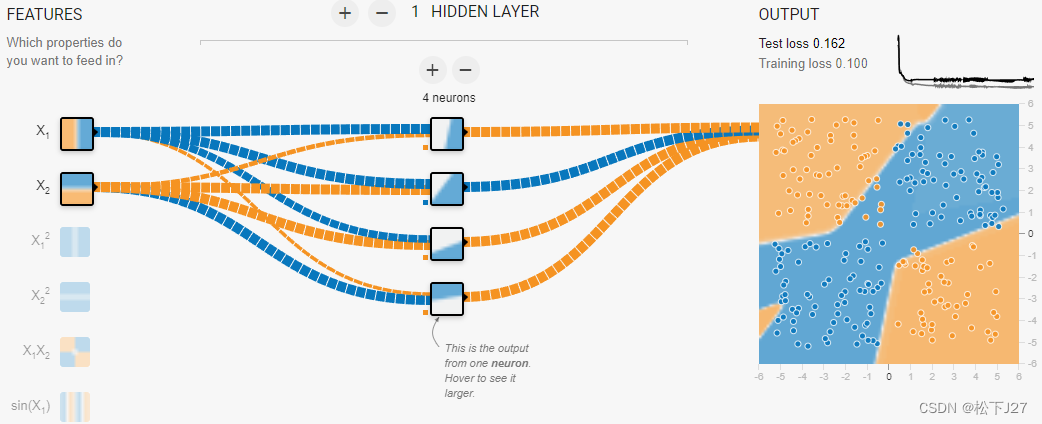
当神经元的数量增加到6个的时候,就足以表征所有的高级特征了。
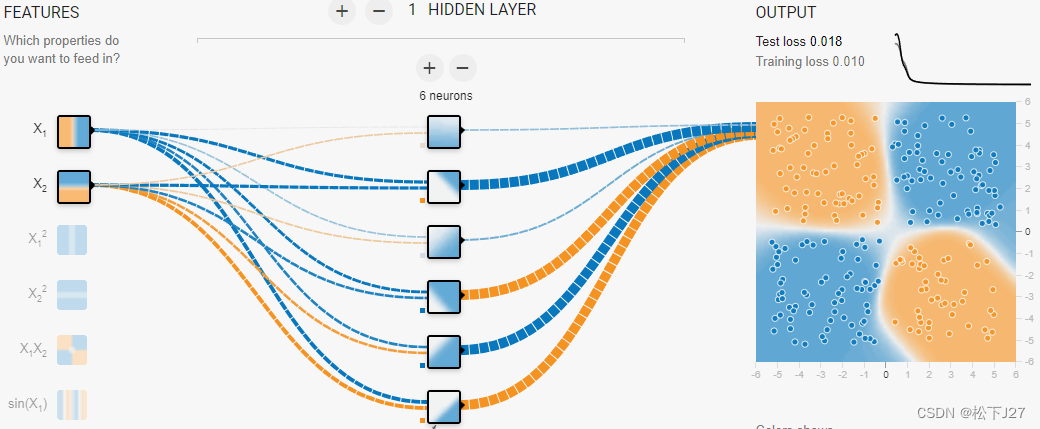
而且这也是深度学习要高于机器学习的地方,我们不再需要人为的去定义一些特征然后让机器去学习,取而代之的是让电脑自己去学习/去找一些他认为重要特征,而这些特征就是神经网络完成学习后的神经元。
3,神经网络的几个重要元素
3,1 神经网络的层数
神经网络可以是单层也可以是多层,它决定了网络的深度。深度神经网络通常具有更多的隐藏层,这意味着它们可以学习更复杂的函数关系。
两层或三层:
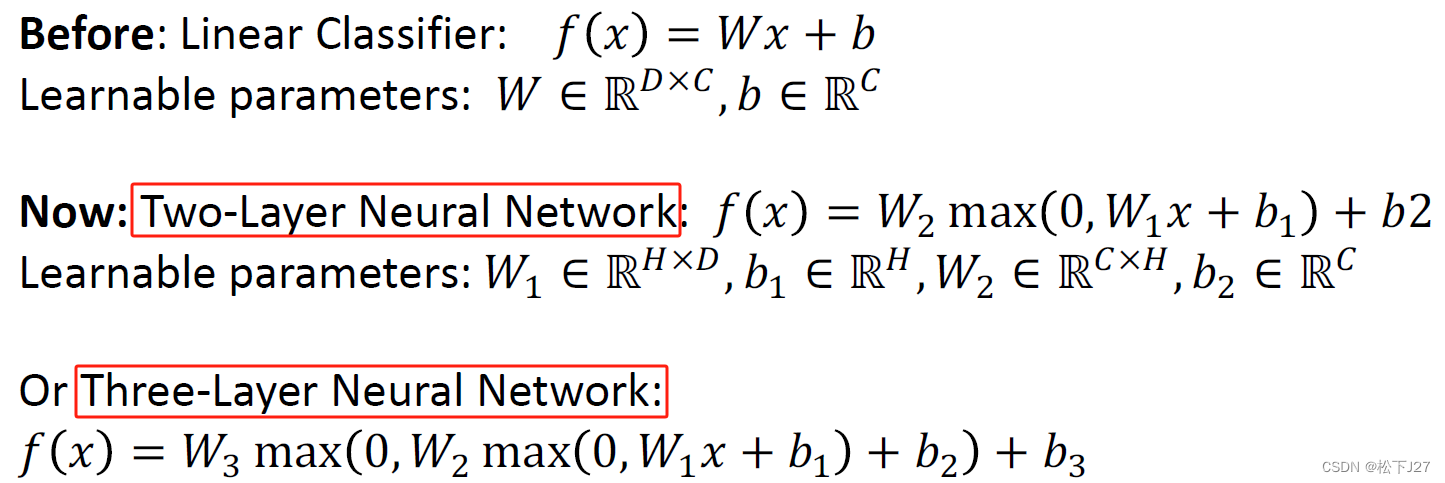
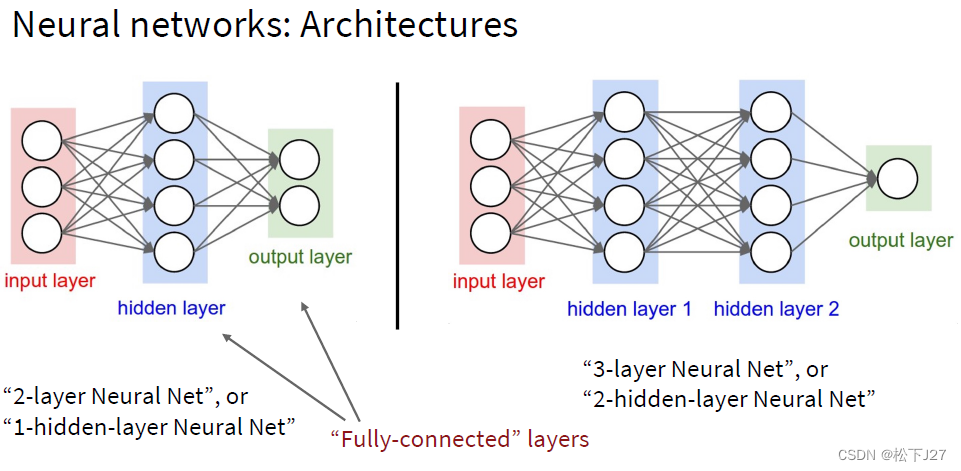
六层:

3,2 每个隐含层所含神经元的个数

3,2,1 对于每层神经元的个数而言
-
神经元个数的选择:
- 每层神经元的个数决定了该层的容量和复杂度。
- 较多的神经元可以增加模型的容量,捕捉更多的特征,但也可能导致过拟合。过拟合的结果就是模型在训练数据上表现很好,但在新数据上表现较差。
- 较少的神经元可能不足以捕捉复杂模式,导致欠拟合。欠拟合的结果是模型在训练数据上和新数据上都表现不好。
-
逐层减少神经元:
- 一种常见的策略是逐层减少神经元的数量,从输入层到输出层逐渐减少。
- 这种方法有助于模型逐步提取高级特征,同时减少计算复杂度。
3,2,2 对于隐含层的层数而言
-
浅层神经网络:
- 通常指只有一到两层隐含层的神经网络。
- 适用于简单的任务,可以通过较少的计算量解决。
- 浅层网络较容易训练,但表达能力有限,难以捕捉复杂的模式。
-
深层神经网络:
- 通常指具有多层隐含层的神经网络(例如3层或更多)。
- 适用于复杂任务,如图像识别、语音识别和自然语言处理。
- 深层网络有更强的表达能力,可以捕捉数据的多层次特征,但训练较为困难,需要更多的计算资源和优化技巧(如正则化、批量归一化等)。
3,3 隐藏层的维度

每一层隐藏层的维度和矩阵W的维度息息相关,因为激活函数并不会影响输出的维度,因此,隐藏层的维度应该是由于Wx的维度决定的,而Wx的维度又是由W决定的。因此,隐藏层的维度,即,神经元的个数是由矩阵W的其中一维决定的。
4,反向传播
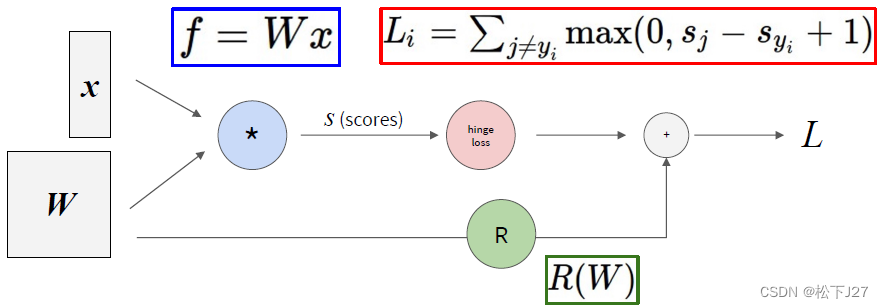
和线性分类器一样,神经网络也会用到Loss function,也要用梯度下降法去优化权重函数W。所不同的是,由于神经网络中的层数较多,且嵌套了很多非线性函数,因此损失函数L就变得很复杂,不太容易直接求出L关于W的梯度。

解决这一计算梯度的难题的方式就叫反向传播,其实,我觉得反向传播只不过是个“新词”。只不过多了个链式法则+computational graphs。
4,1 计算图(computational graph)
这是computational graph他有助于计算局部导数local gradiant。
4,2 链式法则(the chain rule)
把复合函数的导数拆分成一连串偏导数的乘法,每个乘法的乘数分别来自于上游导数和局部导数。
以下图为例:
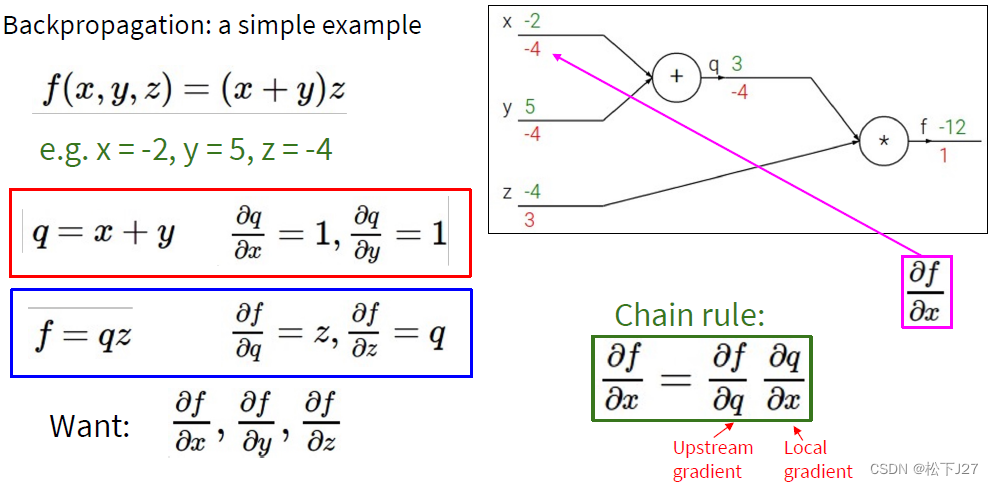
函数f(x,y,z)的梯度是:
用复合函数表示后函数改写为:
对于其中x方向和y方向的梯度是复合函数需要使用链式法则计算复合函数的偏导:
z方向的梯度可以直接计算:
使用计算图去计算每一个节点上的local grad。
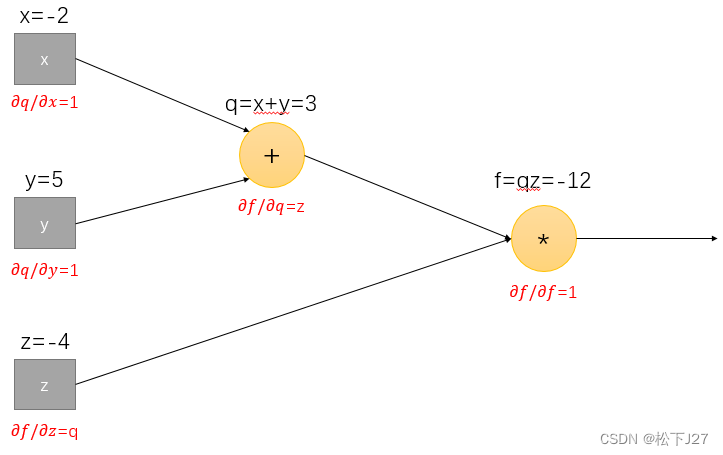
使用链式法则,逐一代入图中的local grad和upstream grad,得到:
在一般的深度学习中,我们所求的梯度一般都是损失函数L关于权重矩阵W的梯度。因为,求梯度的目的就是要通过最小化L去调整权重矩阵W 。


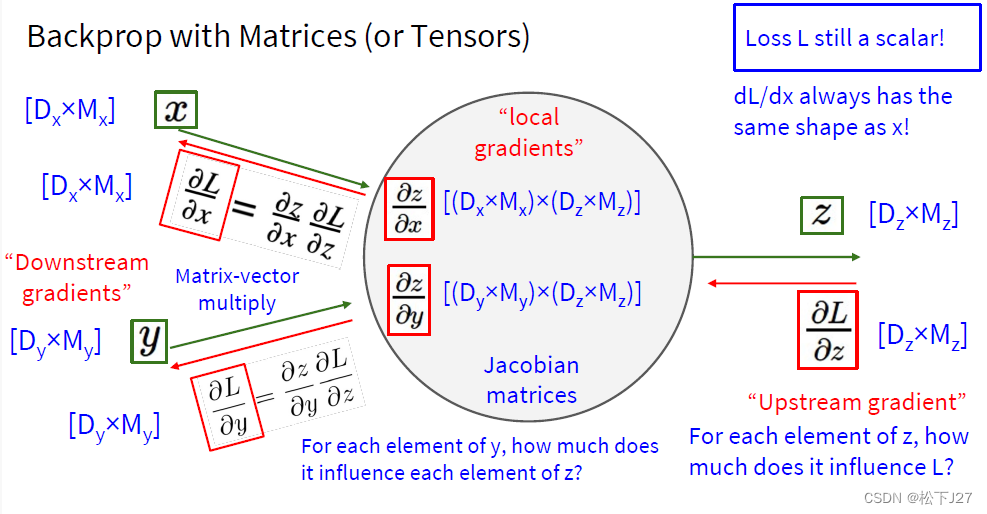
4,3 如果函数L的自变量是一个向量,则需要用到雅可比矩阵去计算偏导。
(全文完)
--- 作者,松下J27
参考文献(鸣谢):
1,Stanford University CS231n: Deep Learning for Computer Vision
2,https://zh.wikipedia.org/wiki/%E6%A2%AF%E5%BA%A6%E4%B8%8B%E9%99%8D%E6%B3%95

(配图与本文无关)
版权声明:所有的笔记,可能来自很多不同的网站和说明,在此没法一一列出,如有侵权,请告知,立即删除。欢迎大家转载,但是,如果有人引用或者COPY我的文章,必须在你的文章中注明你所使用的图片或者文字来自于我的文章,否则,侵权必究。 ----松下J27
















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











