







目录
3.2 Cross Stage Partial DenseNet
3.3 引入 partial dense block及partial transition layer的目的
3.3.2 partial transition layer

本文解决的是减少推理计算的问题。
一、论文摘要部分
神经网络已经使得在计算机视觉任务如目标检测方面实现了令人难以置信的成果。然而,这样的成功在很大程度上依赖于昂贵的计算资源,这使得拥有廉价设备的人们无法享受到这一先进技术的好处。在本文中,我们提出了交叉阶段部分网络(CSPNet),以从网络架构的角度缓解之前的工作需要进行大量推断计算的问题。我们将问题归因于网络优化中的重复梯度信息。所提出的网络通过在网络阶段的开始和结束集成特征图来注重梯度的变化,经过我们的实验证明,这样可以将计算量减少20%,并且在ImageNet数据集上达到了等效甚至更高的准确率,而在MS COCO目标检测数据集上,以AP50指标来衡量,显著优于最先进的方法。CSPNet易于实现,并且足够通用,可以处理基于ResNet、ResNeXt和DenseNet的架构。源代码位于https://github.com/WongKinYiu/CrossStagePartialNetworks。
二、提出背景
CSPNet的提出背景主要源自对现有计算机视觉模型的分析和挑战。在计算资源受限的情况下,轻量级神经网络模型越来越受到关注,但是在轻量化的同时,往往会牺牲模型的准确性。此外,现有的模型在推断过程中存在计算瓶颈和内存开销较大的问题,这导致了在嵌入式设备和边缘计算平台上的应用受到限制。
因此,CSPNet的提出旨在解决以下几个问题:
1. **模型准确性和轻量化之间的平衡:** 现有轻量级模型在准确性上往往表现不佳,CSPNet旨在提高轻量级模型的学习能力,以在保持较高准确性的同时实现轻量化。
2. **计算瓶颈和内存开销:** 现有模型在推断过程中存在计算瓶颈和大量的内存开销,影响了模型的推断速度和应用范围。CSPNet通过优化网络结构和计算流程,以降低计算和内存开销为目标。
3. **适应不同的硬件平台:** CSPNet被设计为通用的轻量级网络结构,可以适应不同的硬件平台,包括嵌入式设备和边缘计算平台,从而扩展了模型的应用范围。
总的来说,CSPNet的提出是为了在保持模型准确性的前提下,提高模型的计算效率和推断速度,以满足在计算资源受限的环境下对计算机视觉模型的需求。
CSPNet提出解决的问题:【论文中给出】
1) 增强CNN的学习能力
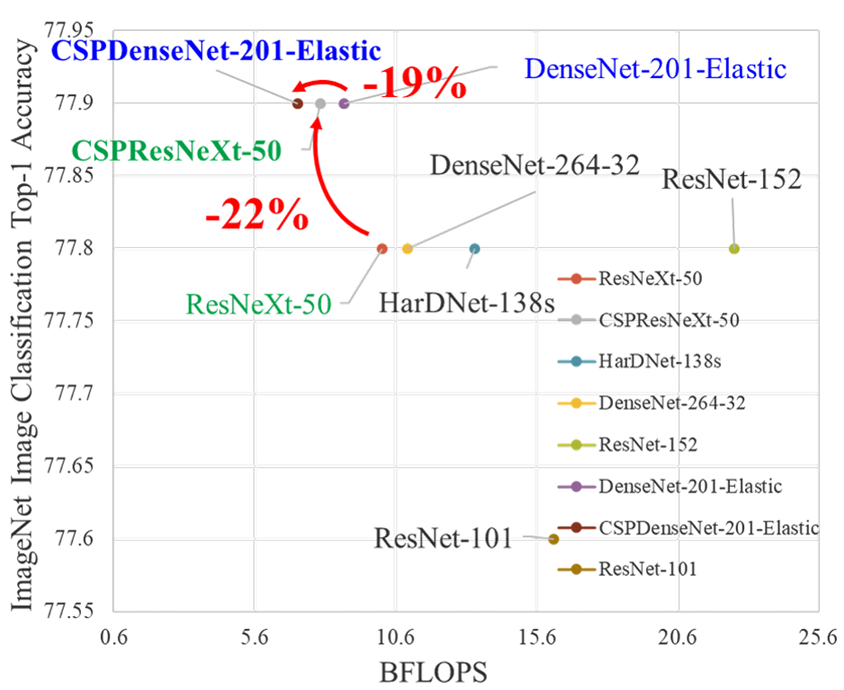
现有CNN在轻量化后的准确性大大降低,因此我们希望增强CNN的学习能力,使其在轻量化的同时能够保持足够的准确性。所提出的CSPNet可以轻松应用于ResNet、ResNeXt和DenseNet等网络。在将CSPNet应用于上述网络之后,计算量可以减少10%到20%,而且在ImageNet上进行图像分类任务时,CSPNet的准确性优于ResNet、ResNeXt、DenseNet、HarDNet、Elastic和Res2Net。
2) 移除计算瓶颈
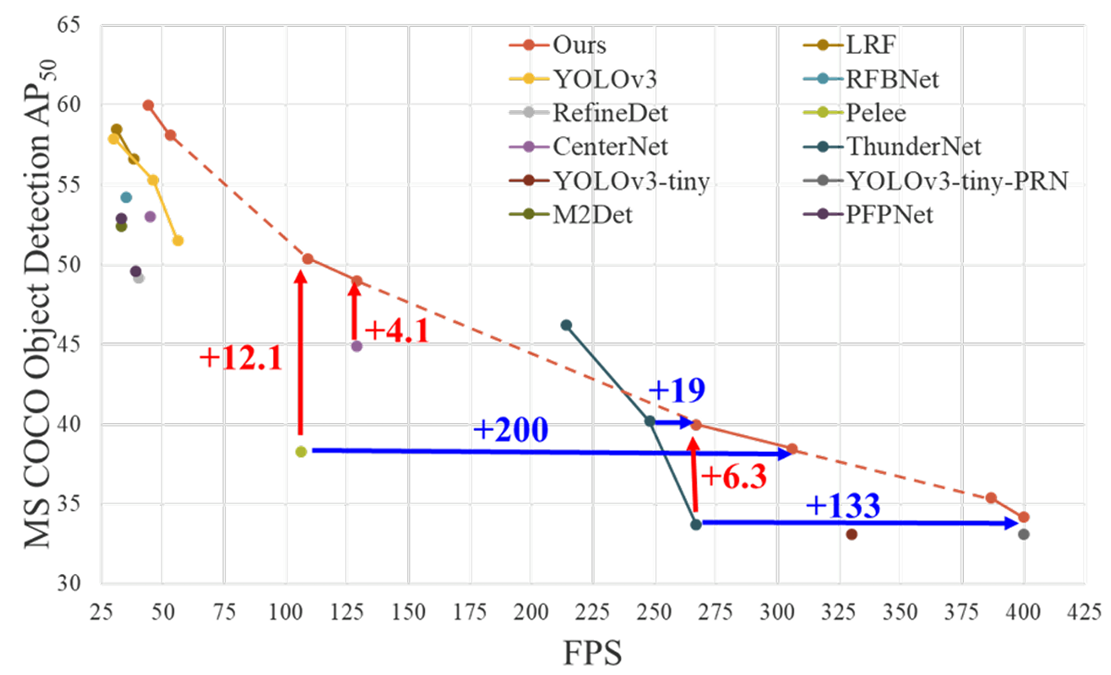
过高的计算瓶颈会导致完成推断过程需要更多的周期,或者一些算术单元会经常处于空闲状态。因此,我们希望能够在CNN的每一层中均匀分配计算量,以有效提升每个计算单元的利用率,从而减少不必要的能源消耗。值得注意的是,所提出的CSPNet将PeleeNet的计算瓶颈减少了一半。此外,在基于MS COCO数据集的目标检测实验中,我们提出的模型在基于YOLOv3模型的测试时,可以有效减少80%的计算瓶颈。
3) 降低内存成本
动态随机存取存储器(DRAM)的晶圆制造成本非常昂贵,而且它还占据了大量空间。如果能够有效降低内存成本,就能大大降低ASIC的成本。此外,一个小面积的晶圆可以用于各种边缘计算设备。为了减少内存使用,我们采用交叉通道池化来在特征金字塔生成过程中压缩特征图。通过这种方式,所提出的CSPNet结合所提出的目标检测器在生成特征金字塔时可以将PeleeNet的内存使用量减少75%。
如下图1所示,CSPNet可以大大减少计算量,并提高推断速度和准确性。
图1:所提出的CSPNet可以应用于ResNet [7]、ResNeXt [39]、DenseNet [11]等网络。它不仅减少了这些网络的计算成本和内存使用量,还提高了推断速度和准确性。
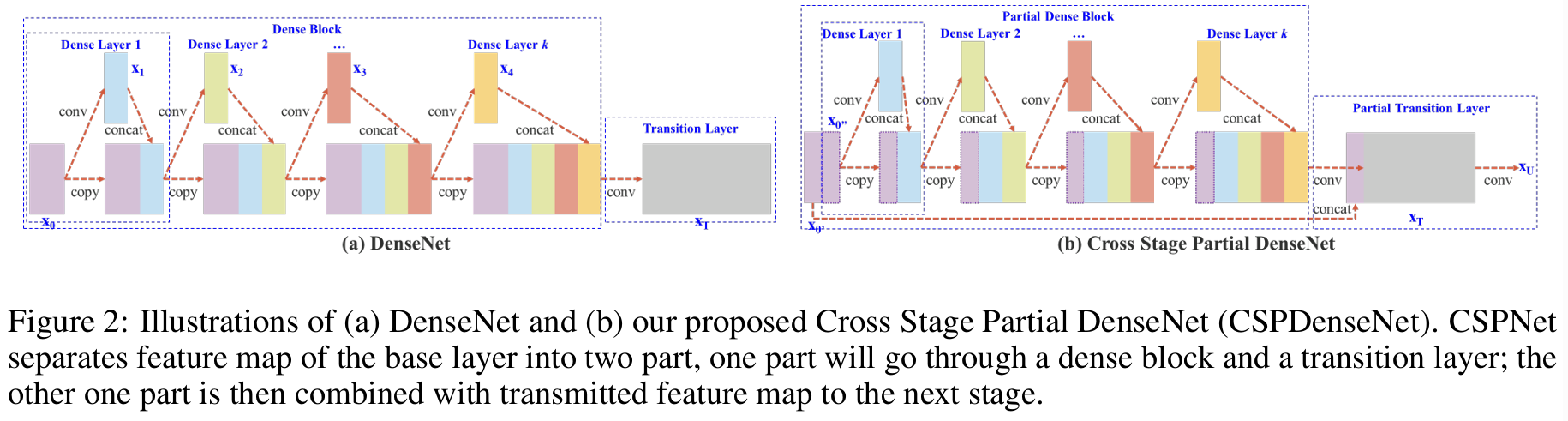
三、本文的方法
图2:(a)DenseNet的示意图和(b)我们提出的跨阶段部分DenseNet(CSPDenseNet)。CSPNet将基础层的特征图分为两部分,一部分经过密集块和过渡层;另一部分则与传递的特征图结合,传递到下一个阶段。
3.1 DenseNet
在介绍CSPNet之前,先看看DenseNet结构
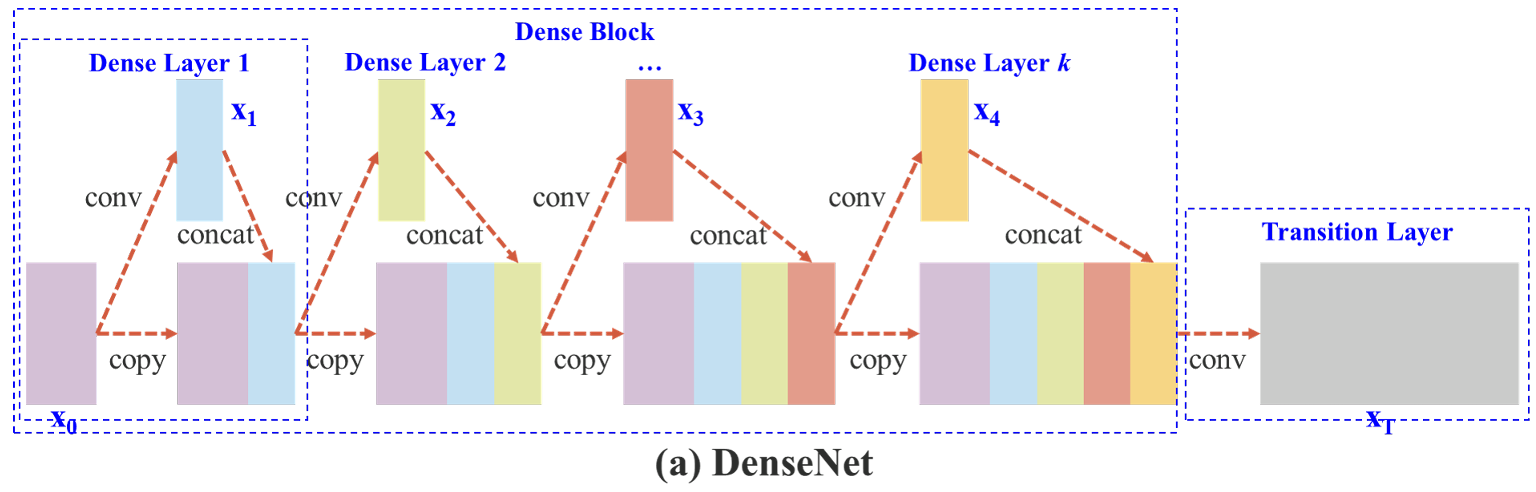
DenseNet的每个阶段包含一个dense block和一个transition layers(放在两个Dense Block中间,是因为每个Dense Block结束后的输出channel个数很多,需要用1×1的卷积核来降维),每个dense block由k个dense layer组成。第i个 dense layer 的输出将与第i个 dense layer 的输入串联,串联的结果将成为第(i+1)个dense layer的输入。
对上述段落的总结:
图 2a 展示了 DenseNet 的一个 stage 结构:
- 每个 stage 都包括一个 dense block + transition layer
- 每个 dense block 由 k 个 dense layer 组成
- 每个 dense layer 的输出会作为下一个 dense layer 的输入
- transition layer: BN+ 1x1 conv + 2x2 avg pooling
因此DenseNet的机制可以表示为: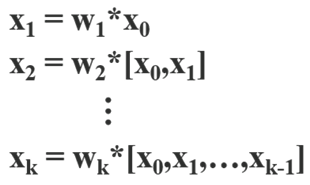
其中 * 表示卷积算子,而[x0,x1,…]表示将x0,x1,…,进行串联,Wi和Xi分别表示第i个dense layer 的权重和输出。
如果使用反向传播算法更新权重,则权重更新方程可以写成:
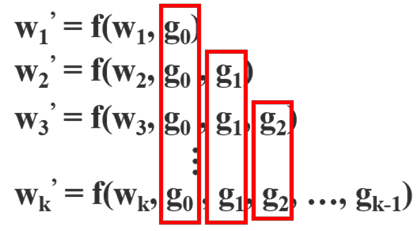
其中f是权重更新的函数,gi表示传播到第i个dense layer的梯度。我们可以发现大量的梯度信息被重复使用来更新不同dense layer 的权重。这将导致不同dense layer 反复学习重复的梯度信息。
引用自:【网络结构设计】6、CSPNet | 一种加强 CNN 模型学习能力的主干网络-CSDN博客
重点:
Concat 操作后,不同通道的梯度是如何传递的
- Concat 是将多个通道的特征图进行拼接,互相不影响
- 所以在梯度反向传播的时候,多个通道拼接的特征,只会找对应通道的特征图进行梯度回传
DenseNet 为什么有大量的梯度重用:
- 每个 layer 会接收前面所有 layer 的输出,也就是 layer i 的输入是 [layer 1 , layer 2 , layer i-1] concat 起来的
- 在梯度回传的时候,layer 1 会接收到 layer 2 ~ layer i 层的梯度回传,相当于回传了很多遍
CSPNet 怎么解决这种梯度重用:
- 将每个 block 的输入分成两部分,一部分经过和 DenseNet 相同的密集连接,然后再经过 transition layer,另一部分经过 transition layer,然后将部分 concat 再经过最后的 transition layer 然后输出
- 其实这里经过 DenseNet 的密集连接的特征图,还是存在梯度重用,真正实现了“梯度不重用”的是这两个分支(经过密集连接和不经过密集连接的这两个分支),因为这两个分支的梯度是不会被重用的(concat 后各自通道负责各自的梯度回传,没有重复计算梯度)
- 所以 CSPNet 并没有完全解决了梯度重用,可以看做只解决了一半通道的梯度重用
3.2 Cross Stage Partial DenseNet
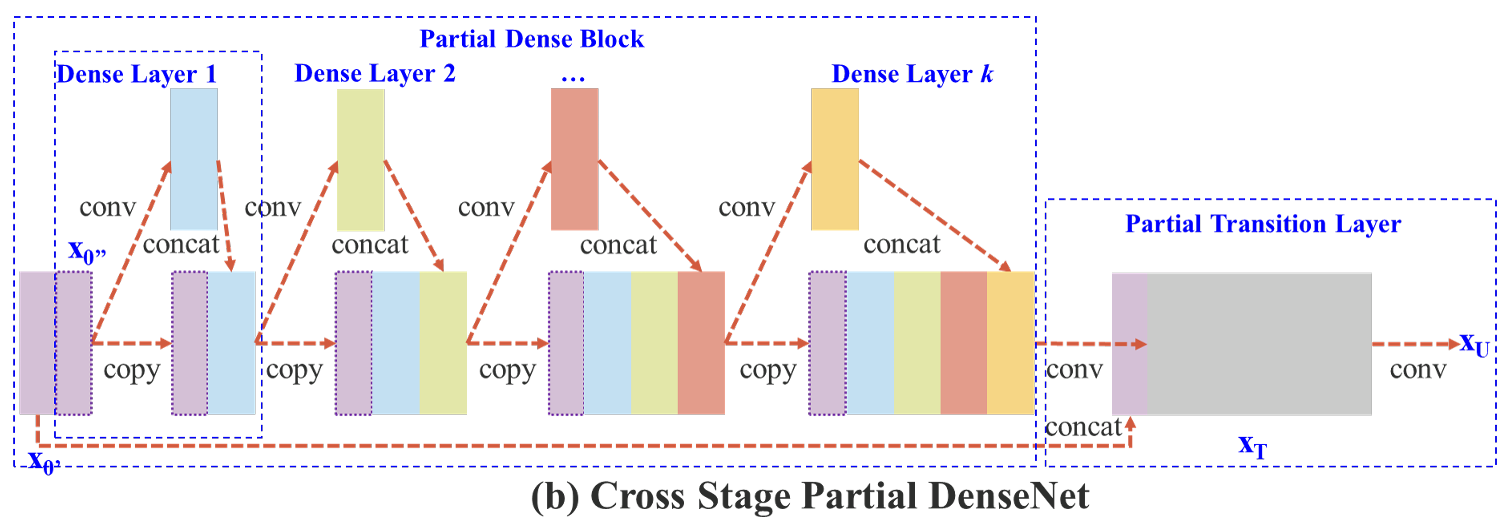
图2(b)展示了所提出的CSPDenseNet的一个阶段的架构。CSPDenseNet的一个阶段由一个partial dense block和一个partial transition layer 组成。在partial dense block中,一个阶段中基础层的特征图被分成两部分通过通道![]() 。在
。在 ![]() 和
和![]() 之间,前者直接连接到阶段的末尾,而后者将经过一个dense block。
之间,前者直接连接到阶段的末尾,而后者将经过一个dense block。
partial transition layer涉及的所有步骤如下:首先,密集层的输出![]() 将经过一个过渡层。其次,这个过渡层的输出
将经过一个过渡层。其次,这个过渡层的输出![]() 将与
将与![]() 串联,并经过另一个过渡层,然后生成输出
串联,并经过另一个过渡层,然后生成输出![]() 。
。
CSPDenseNet的前向传递和权重更新方程式分别如下所示:
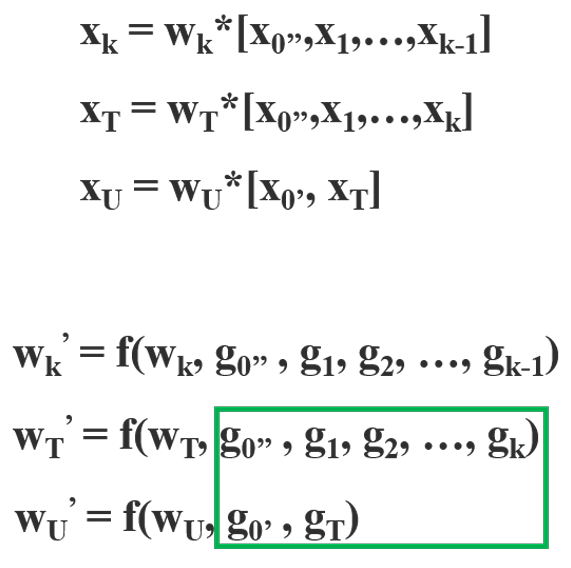
我们可以看到,来自dense layer的梯度是分开整合的。另一方面,未穿过dense layer的特征图![]() 也单独集成。对于用于更新权重的梯度信息,两边不包含属于另一边的重复梯度信息。
也单独集成。对于用于更新权重的梯度信息,两边不包含属于另一边的重复梯度信息。
总体而言,本文提出的CSP-DenseNet保留了DenseNet特征重复使用的优点,同时通过截断梯度流防止了过多的重复梯度信息。该思想通过设计层次化特征融合策略实现,并应用于部分过渡层。
3.3 引入 partial dense block及partial transition layer的目的
3.3.1 partial dense block
设计部分密集块的目的是为了:
1.) 增加梯度路径:通过分割和合并策略,梯度路径的数量可以加倍。由于跨阶段策略,可以减轻使用显式特征图复制进行串联所带来的缺点;
2.) 平衡每层的计算量:通常,DenseNet中基础层的通道数远远大于增长率。由于部分密集块中密集层操作涉及的基础层通道数量仅占原始数量的一半,因此可以有效解决近一半的计算瓶颈;
3.) 减少内存流量:假设DenseNet中密集块的基础特征图大小为w×h×c,增长率为d,总共有m个密集层。那么,该密集块的CIO【CIO指的是“Convolutional Input/Output”,是一种近似于动态随机存取存储器(DRAM)流量的度量,与实际DRAM流量成正比。】为![]() ,部分密集块的CIO为
,部分密集块的CIO为![]() 。由于m和d通常远小于c,部分密集块能够最多节省网络内存流量的一半。
。由于m和d通常远小于c,部分密集块能够最多节省网络内存流量的一半。
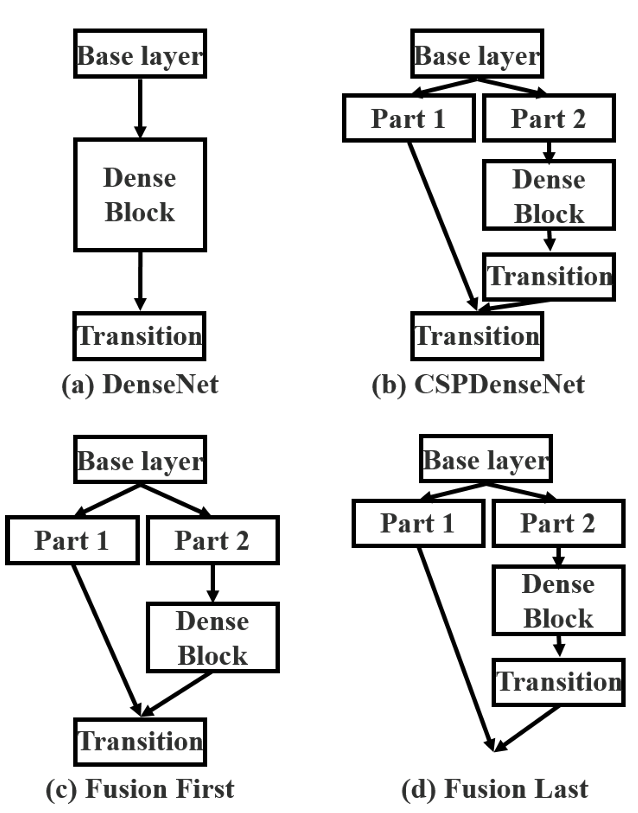
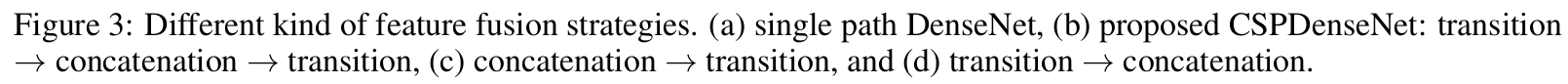 图3:不同类型的特征融合策略。
图3:不同类型的特征融合策略。
(a) 单路径DenseNet,
(b) 提出的CSPDenseNet:过渡串联过渡,
(c) fusion first:经过 dense block 的特征直接和 part1 的特征进行 concat,然后再输入 Transition,这样梯度是可以重复利用的
(d) fusion last:经过 dense block 的特征先自己做 transition,然后和 part1 特征 concat,这样梯度是会被截断的,不会重复利用(因为没有融合所以两部分梯度无法共享,造成梯度截断)
3.3.2 partial transition layer
Partial Transition Layer的设计目的是最大化梯度组合的差异。Partial Transition Layer是一种分层特征融合机制,采用截断梯度流的策略,防止不同层学习重复的梯度信息。在这里,我们设计了两种CSPDenseNet的变体,以展示这种梯度流截断对网络学习能力的影响。图3(c)和3(d)展示了两种不同的融合策略。
CSP(Fusion First)意味着将由两部分生成的特征图连接起来,然后进行过渡操作。如果采用这种策略,将会重复使用大量的梯度信息。
至于CSP(Fusion Last)策略,来自密集块的输出将经过过渡层,然后与来自第一部分的特征图进行连接。如果采用CSP(Fusion Last)策略,梯度信息将不会被重复使用,因为梯度流被截断了。如果我们使用图3中展示的四种架构进行图像分类,相应的结果如图4所示。
可以看出,如果采用CSP(Fusion Last)策略进行图像分类,计算成本会显著降低,但top-1准确率仅下降了0.1%。另一方面,CSP(Fusion First)策略确实有助于显著降低计算成本,但top-1准确率显著下降了1.5%。通过跨阶段使用分裂和合并策略,我们能够有效地减少信息整合过程中的重复可能性。从图4中的结果可以明显看出,如果能有效减少重复的梯度信息,网络的学习能力将得到极大的改善。
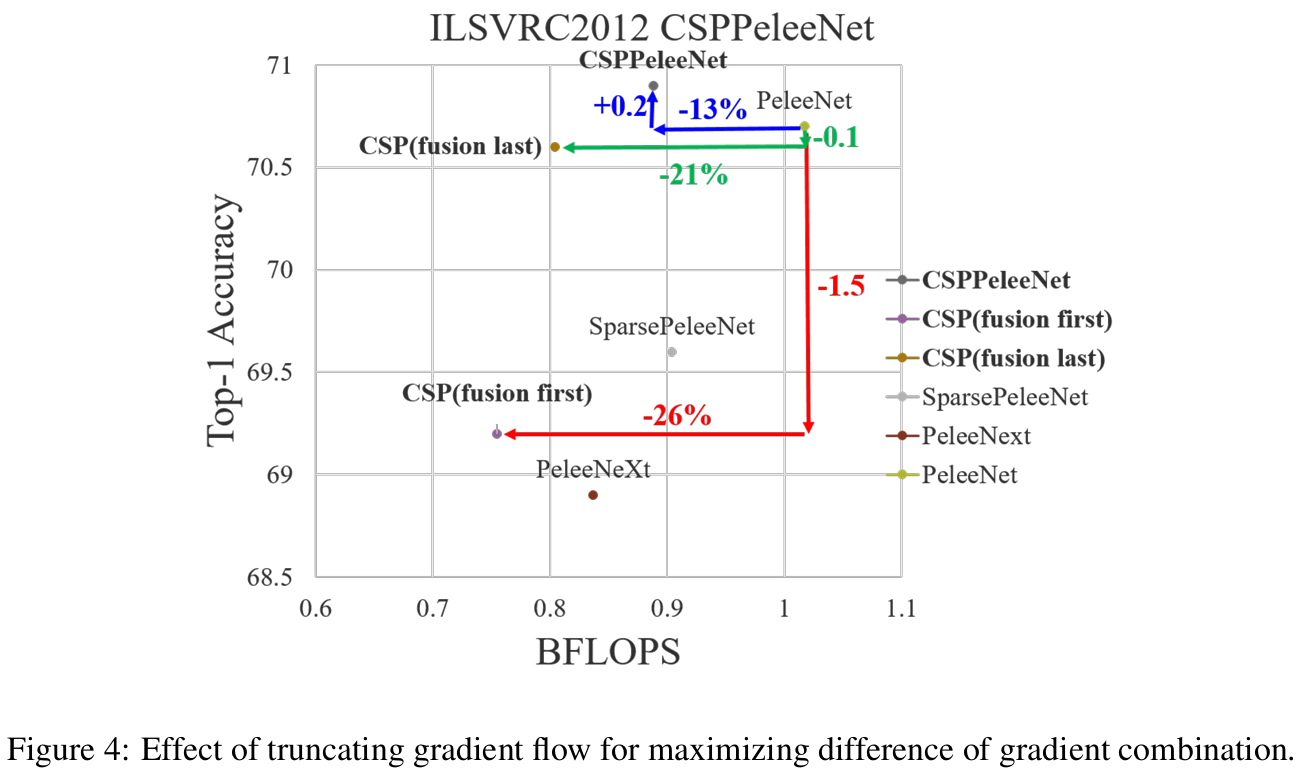
3.4 将CSPNet应用到其他结构中
CSPNet也可以轻松地应用于ResNet和ResNeXt,其架构如图5所示。由于只有一半的特征通道通过Res(X)块,因此不再需要引入瓶颈层。这使得在固定浮点操作(FLOPs)时,内存访问成本(MAC)的理论下限更低。
3.5 Exact Fusion Model
EFM提出了一种准确地预测的方法,通过捕获每个anchor的适当视野(Field of View, FoV),增强了一阶段目标检测器的准确性。对于分割任务,由于像素级标签通常不包含全局信息,通常更倾向于考虑更大的区域以获得更好的信息检索。然而,对于诸如图像分类和目标检测之类的任务,当从图像级别和边界框级别的标签进行观察时,一些关键信息可能会变得模糊。李等人发现,当CNN从图像级别标签学习时,往往会分散注意力,并得出这是两阶段目标检测器优于一阶段目标检测器的主要原因之一。
聚合特征金字塔。提出的EFM能够更好地聚合初始特征金字塔。EFM基于YOLOv3 [29],它为每个真实对象分配了一个先验边界框。每个标注框对应一个超过IoU阈值的anchor框。如果一个anchor框的大小等于网格单元的视野范围,那么对于第s个尺度的网格单元,相应的边界框将被第(s-1)个尺度下界和第(s+1)个尺度上界所限制。因此,EFM会从这三个尺度中汇聚特征。
平衡计算。由于特征金字塔中的拼接特征图非常庞大,会引入大量的内存和计算成本。为了缓解这个问题,我们采用了Maxout技术【类似于droupout】来压缩特征图。
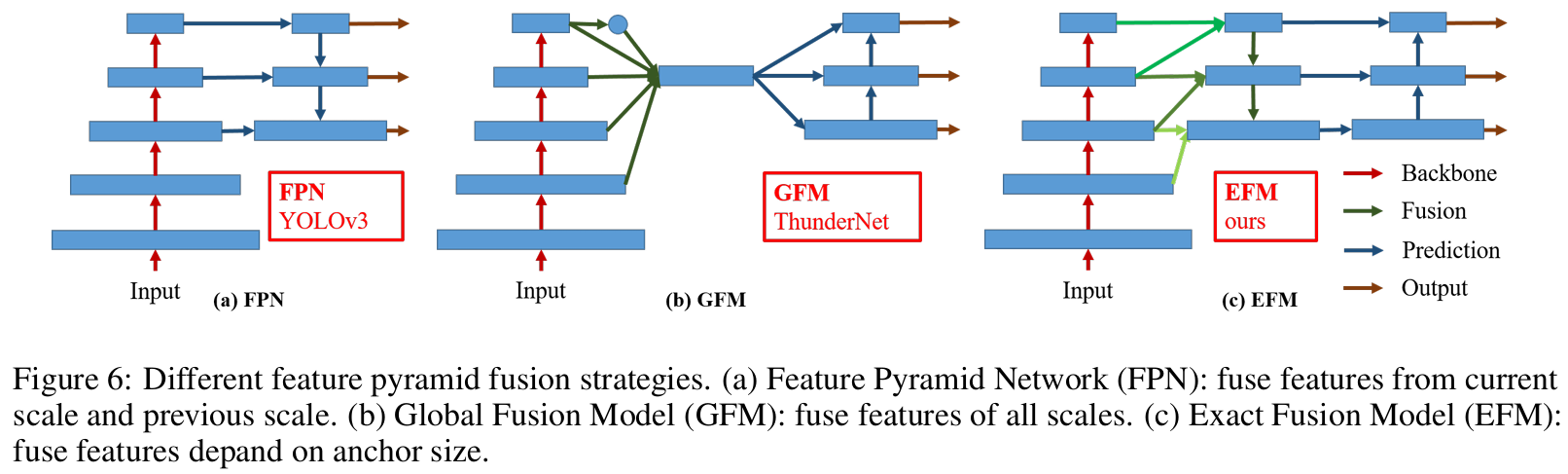
图6:不同的特征金字塔融合策略。
(a)特征金字塔网络(FPN):融合当前尺度和前一尺度的特征。
(b)全局融合模型(GFM):融合所有尺度的特征。
(c)精确融合模型(EFM):根据锚点尺寸融合特征。
部分参考自:
https://blog.csdn.net/haha0825/article/details/106102762
https://blog.csdn.net/jiaoyangwm/article/details/126766270
深度学习之CSPNet分析_cspnet结构-CSDN博客

















 3808
3808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









