






代码展示:
import numpy as np
import pandas as pd
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense,Dropout,Activation,LSTM
from keras.layers import Embedding,GRU,Bidirectional
from keras.callbacks import EarlyStopping
from keras.datasets import imdb
n_words = 1000
(X_train,y_train),(X_test,y_test) = imdb.load_data(num_words=n_words)
print("train seq:{}".format(len(X_train)))
print("test seq:{}".format(len(X_test)))
print("train example:{}".format(X_train[0]))
print("test example:{}".format(X_test[0]))
max_len = 200
X_train = sequence.pad_sequences(X_train,maxlen=max_len)
X_test = sequence.pad_sequences(X_test,maxlen=max_len)
#model
model = Sequential()
model.add(Embedding(n_words ,50,input_length=max_len))
model.add(Dropout(0.2))
model.add(Bidirectional(LSTM(100,dropout = 0.2,recurrent_dropout= 0.2)))
model.add(Dense(250,activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['acc'])
model.summary()
callbacks = [EarlyStopping(monitor='val_acc',patience=3)]
batch_size = 1024
n_epochs = 10
model.fit(X_train,y_train,batch_size=batch_size,epochs=n_epochs,validation_split=0.2,callbacks=callbacks)
print('acc on test set :{}'.format(model.evaluate(X_test,y_test,batch_size=batch_size)[1]))
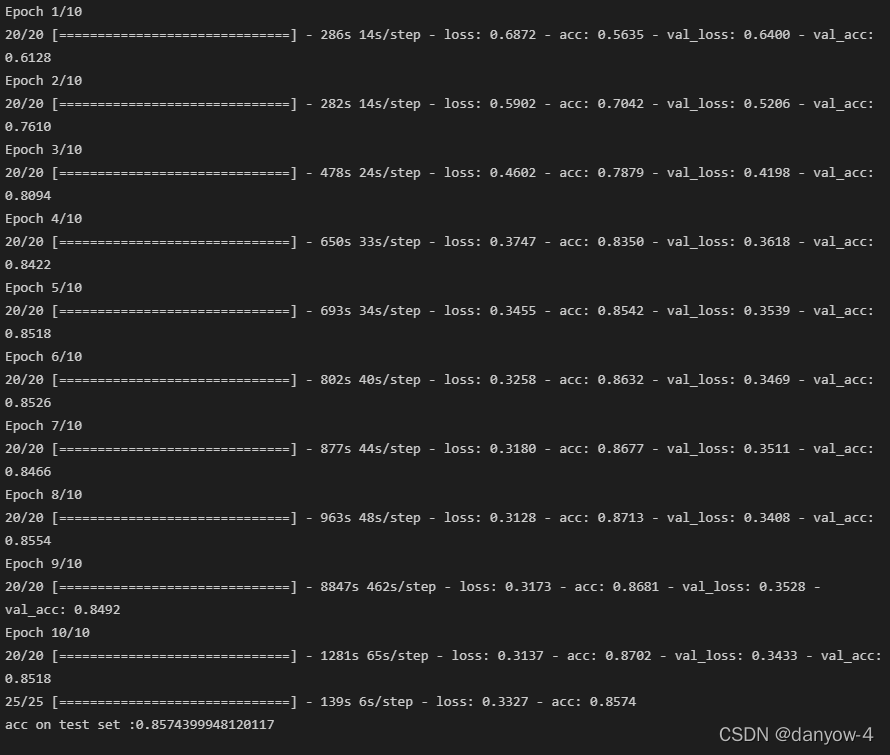
实现截图:

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









