






前言
MeshCNN是2019年提出的直接在3D Mesh上进行分类和分割的网络,MeshCNN在3D网格上定义了定义了卷积和池化层,依据三维模型边的连通关系进行研究。最终能够在来自SHREC 11数据集的30个类上达到98.6%的精度,并且在部件和人体数据集上有很好的分割性能。
一、网络结构
其网络结构大体如下所示,其结构采用编码器(Encoder)-解码器(Decoder)形式,输入的是每条边的几何特征,论文中是5维,输出是每条边的类别信息,注意这里面的Conv、Pooling、UnPooling操作是在Mesh上进行的,具体细节见后续分析。
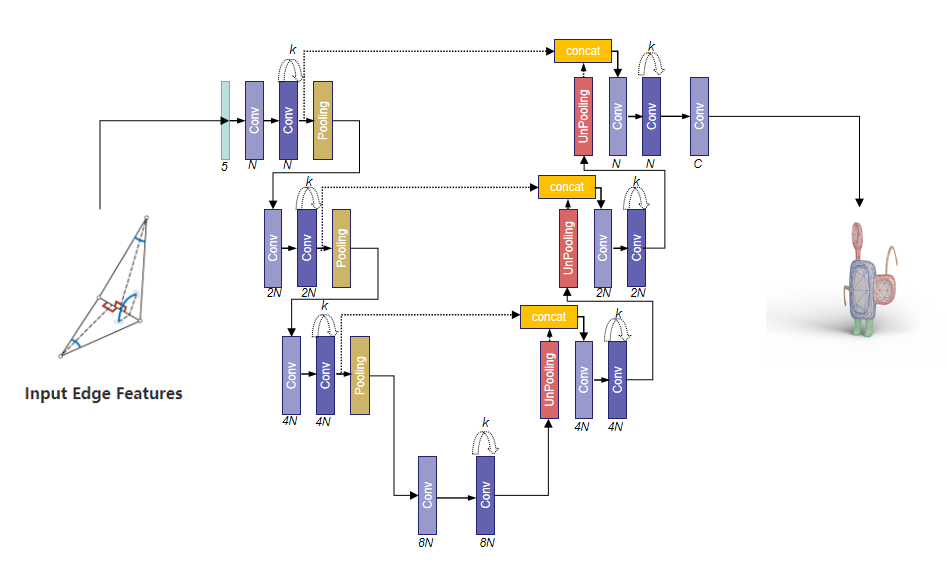
实现上可以参考:network.py
二、关键点
2.1 输入特征
考虑每条边相邻的两个面,也就是考虑该边的一邻域,共提取以下5个几何特征,这些几何特征不会随着模型的旋转平移而改变。
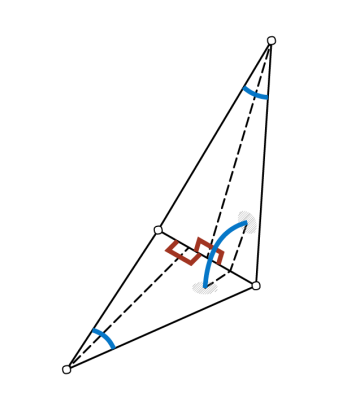
- 两个面组成的二面角 * 1
- 两个面和该边分别对应的内角 * 2
- 该边边长与相邻面垂线(图中虚线)长度的比率 * 2
2.2 边卷积
考虑边的一邻域,如下图所示,对于当前边e,按逆时针方向考虑其相邻边的特征 a,b,c,d。
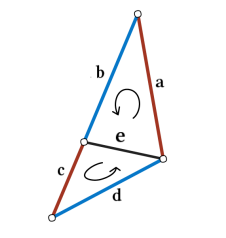
定义边的卷积为:
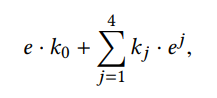
即取当前边以及相邻边的特征加权和,ej表示第j条相邻边的特征。
存在问题
按照先前提到的逆时针选取相邻边的顺序,则依赖于先选择哪个面,所以会有(a,b,c,d)和(c,d,a,b)两种情形,这对于同一条边来讲其实是一样的,但是直接进行边卷积顺序不同则会产生不同点值。
解决方法
为了消除顺序不同带来的影响,对四条相邻边的特征进行了如下变换。
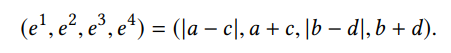
具体实现
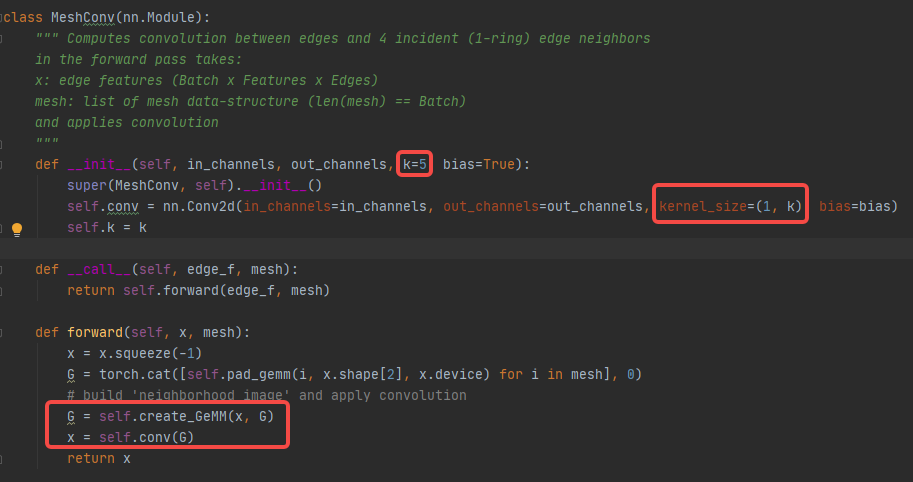
这里自定义的边卷积和普通卷积不一样,所以在实现上进行了处理,即把边特征创建成虚拟的图,在采用卷积核为(1, 5)普通卷积,这里的图的大小为Batch x Channels x Edges x 5,Batch指批处理大小,Channels指特征的维度,Edges表示边的个数,5表示一领域4条边以及本身,代码可以参考create_GeMM函数。
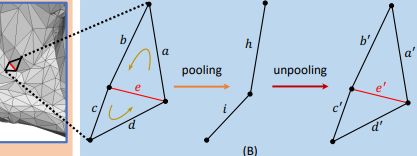
2.3 边池化
边的池化操作包括Pooling和UnPooling两个操作
-
Pooling
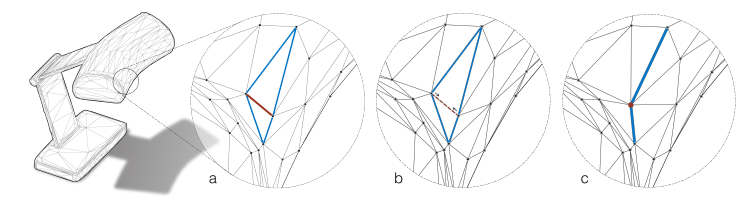
如上图所示边的池化操作有点类似于边塌缩的减面算法(采用QEM方法,可参考参考链接中给出的参考文献),这里操作比较简单,直接对邻面边进行求平均即:
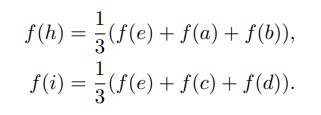
-
UnPooling
UnPooling与Pooling操作相反,需要恢复出两个面,先计算出边长,再指定两个面的其他边。
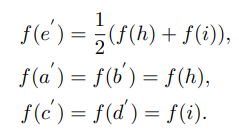
细节点
Q: 那池化过程中具体如何确定哪一条边进行坍缩呢?
A: 具体坍缩哪一条边由网络自动进行学习,会依据任务的不同选择保留不同的边(如下图所示)
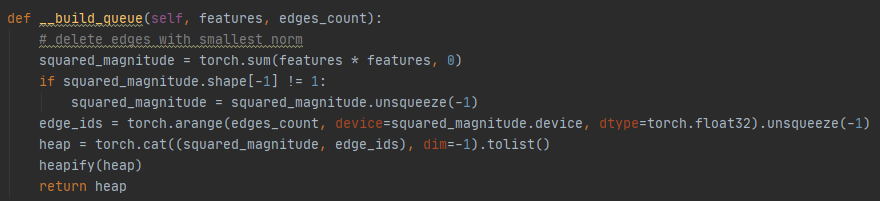
在具体实现上,简单的按照特征的平方和大小进行排序,直到达到指定的边数为止,代码可以参考mesh_pooling.py
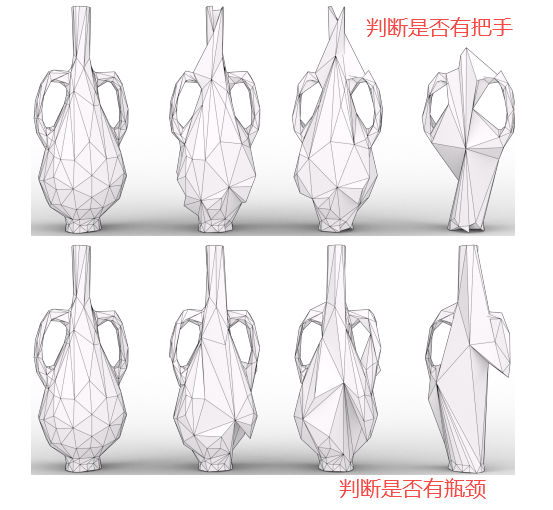
三、实现效果
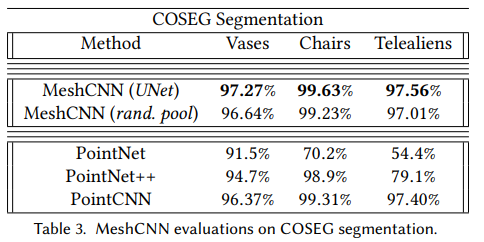
MeshCNN在分类和分割上都取得了较好的效果
-
分类
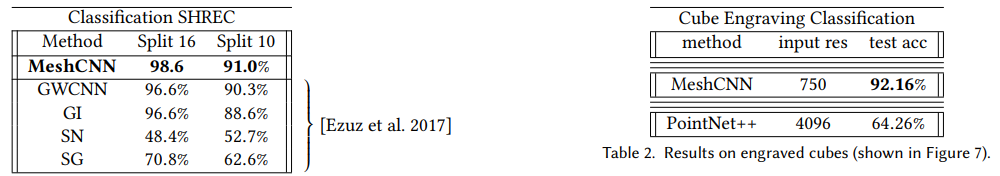
-
分割

四、数据处理
4.1 处理步骤
参考:https://github.com/ranahanocka/MeshCNN/wiki/Data-Processing
主要分为以下三步
- 将Mesh模型以obj格式存储
obj格式以点坐标和面来存储Mesh,具体可以参考:https://all3dp.com/1/obj-file-format-3d-printing-cad/

如果输入是其他格式模型,可以借助Meshlab对其进行格式转换
meshlabserver -i /path/to/model.off -o /path/to/model.obj
- 模型简化
由于有些模型面片数量相差较大,所以先将其简化成相同面片数的Mesh,会更加便于训练。
减面可以参考:blender_process.py
/opt/blender/blender --background --python blender_process.py /path/to/input_mesh.obj num_faces /path/to/outputmesh.obj
-
非流形输入数据
MeshCNN支持流形网格(简单可以理解成一条边对于两个面),对于有些非流形数据,额可以借助Manifold进行处理。 -
数据集
经过处理后得到的数据集如下所示

seg: 保存每条边的类别信息
sseg: 保存每条边及邻边得到的类别信息(概率值)
train: 保存训练的obj模型
val: 保存验证的obj模型
4.2 数据流
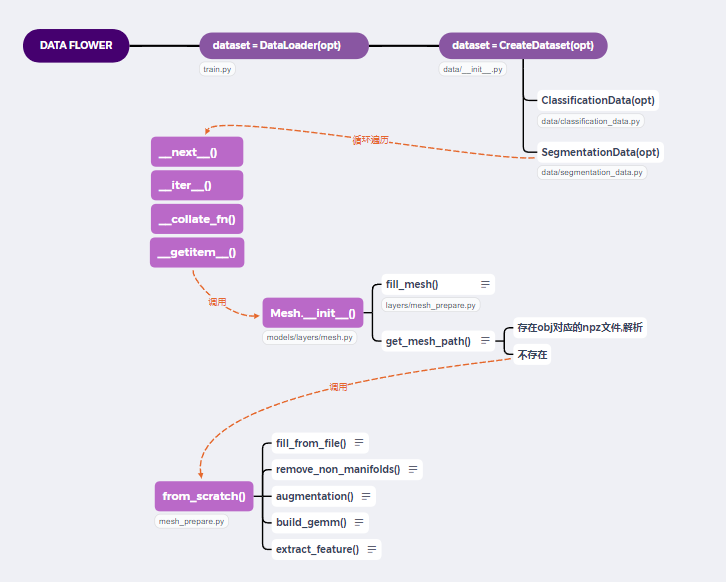
中间主要有以下方法
-
fill_mesh()
给mesh赋值 包括vs,edges,gemm_edges,features等 -
get_mesh_path()
获取对应obj文件对应的npz文件
存在obj对应的npz文件则直接解析
不存在则执行from_scratch() -
from_scratch()
-
fill_from_file()
解析obj文件获取vs,faces -
remove_non_manifolds()
移除非正常的faces -
augmentation()
数据增强 -
build_gemm()
获取相邻边 -
extract_feature()
提取特征
-
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









