







TOOD: Task-aligned One-stage Object Detection
论文地址: https://arxiv.org/abs/2108.07755
论文代码: https://github.com/fcjian/TOOD
摘要
提出背景:一阶目标检测通常通过优化分类和回归任务,使用两个平行分支的头部进行,但是该方式可能会存在一定程度的空间偏差(两个任务不对齐),因此提出可TOOD。(这一点YOLOX提出的解耦头部也是这个原因)
1.介绍
分类任务旨在学习集中在对象的关键或显著部分的区别特征,而定位任务致力于精确定位整个对象及其边界。由于用于分类和定位的学习机制的差异,两个任务所学习的特征的空间分布可能不同,当使用两个单独的分支进行预测时,会导致一定程度的未对准。
最近的单级物体检测器试图通过聚焦物体的中心来预测两个独立任务的一致输出。他们假设位于物体中心的锚(即,用于无锚探测器的锚点,或用于基于锚的探测器的锚盒)可能对分类和定位给出更准确的预测。例如,最近的FCOS和ATSS都使用相邻分支来提高从对象中心附近的锚点预测的分类分数,并且给对应的anchor的定位 loss 更多的权重。但这些方法大都有两个问题:
问题一:分类和定位是被独立对待的
现有的单阶段检测器通过并行使用两个独立的分支,完成分类和定位两个任务,导致预测结果不一致。
问题二:Task-agnostic 的样本分配(对任务无差别的样本分配)
大多数anchor-free检测器使用基于几何的分配方式来选择靠近物体中心的锚点;
但 anchor-based 方法通常计算anchor box 和 gt box 的 IoU 来确定 anchor
但是用于分类和定位的锚通常是不一致的,且可能根据对象的形状和特征而有很大不同。
总结下:
主要是讲了单阶段模型通常是将分类和定位分开的,但是这种方式带来很多问题。1.分开会出现任务不对齐问题2.两个的锚通常是不一致的,使得任务难以准确
提出TOOD
基于上述问题,提出了TOOD的T-head。
用来增强两个任务之间的交互,使得两个任务可以更好的协同工作。
T-head在概念上很简单:它计算任务交互特征,并通过一个新颖的任务对齐预测器(TAP)进行预测。然后它根据任务对齐学习提供的学习信号对齐两个预测的空间分布。
Task alignment learning.
为了进一步克服错位问题,我们提出了任务对齐学习(TAL)来明确地拉近两个任务的最优锚。它是通过设计一个样本分配方案和一个任务对齐损失来实现的。样本分配通过计算每个锚点的任务对齐度来收集训练样本(即,阳性或阴性),而任务对齐损失逐渐统一了最佳锚点,用于在训练期间预测分类和定位。因此,在推断时,可以保留具有最高分类分数并且共同具有最精确定位的边界框。所提出的T-head和学习策略可以协同工作,以在分类和本地化方面做出高质量的预测。这项工作的主要贡献可以总结如下:(1)我们设计了一个新的T-head来增强分类和定位之间的相互作用,同时保持它们的特性,并在预测时进一步对齐这两个任务;(2)我们提出TAL在识别的任务对齐锚处显式对齐两个任务,以及为提出的预测器提供学习信号;(3)我们在MSCOCO上进行了广泛的实验[16],其中我们的TOOD达到了51.1 AP,大大超过了最近的单级探测器,如ATSS 、GFL和PAA 。定性结果进一步验证了我们的任务协调方法的有效性。
2. Related Work
略过,
3.Task-aligned One-stage Object Detection
整体上采用了backbone-FPN-head的结构。
TOOD的每个位置使用一个锚(跟ATSS相同),使用一个设计好的任务对齐头和一个新的任务对齐学习来更明确地对齐这两个任务。
具体来说,T型头首先对FPN特征的分类和定位进行预测。然后,TAL基于新的任务对齐度量来计算任务对齐信号,该度量测量两个预测之间的偏差程度。最后,T-head使用反向传播期间从TAL计算的学习信号自动调整其分类概率和定位预测。
3.1. Task-aligned Head
该头部结构主要依据两个方面:
1.增加两个任务之间的交互
2.增强检测器学习对齐能力

图3(b)显示了建议的T形头,其中它有一个简单的特征提取器,带有两个任务对齐预测器(TAP)。
左面(a)是通常采用的头部,(b)是本文提出的T-head,(c)是TAP结构,用在了(b)中。
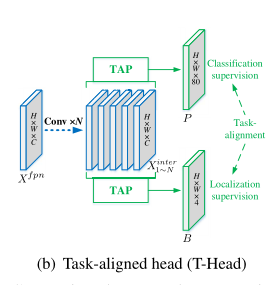
该结构采用了一个特征提取器,这样的设计不仅仅可以加强任务的交互,而且可以给这两个任务提供多尺度感受野的多级特征。因此,可以使用单个分支从 FPN 特征中获得丰富的多尺度特征。
然后将该特征提取器得到的task-interactive feature给TAP结构,用来对齐分类和定位。
此时可跳转至该博主
3.2. Task Alignment Learning
3.2.1 Task-aligned Sample Assignment
3.2.2 Task-aligned Loss
4. Experiments and Results
4.1. Ablation Study
4.2. Comparison with the State-of-the-Art
4.3. Quantitative Analysis for Task-alignment
5. Conclusion
参考:
https://blog.csdn.net/jiaoyangwm/article/details/119837303
https://mp.weixin.qq.com/s/A6RNmRb_l4FWoiBuxWCwtg















 2303
2303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









