




- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标
逐步实现YOLOv5模型的改进
具体实现
(一)环境
语言环境:Python 3.10
编 译 器: PyCharm
框 架: YoloV5
(二)具体步骤
1. 核心文件
上次学习已经知道了YOLOv5的核心文件,YOLOv5的模型结构主要由这些文件控制:
models/yolov5s.yaml- 模型配置文件(还有n、m、l、x版本),这是“设计图纸”models/common.py- 基础模块定义,网络的"零部件工厂"models/yolo.py- 主要的模型构建文件,模型的"总装车间"
2. 复制yolov5s.yaml配置文件成my_yolov5s.yaml
虽然先copy了但不进行任何改动,先验证一下,验证脚本:
# filename: test_my_model.py
import torch
from models.yolo import Model
model = Model('models/my_yolov5s.yaml')
print(model)
# 测试前向传播
x = torch.randn(1, 3, 640, 640)
y = model(x)
print(f"输出形状:{[yi.shape for yi in y]}")
输出形状:[torch.Size([1, 3, 80, 80, 85]), torch.Size([1, 3, 40, 40, 85]), torch.Size([1, 3, 20, 20, 85])]
这输出的3个数:[1, 3, 80, 80, 85],[1, 3, 40, 40, 85],[1, 3, 20, 20, 85]怎么来的呢?在第2天里说过了
1: batch_size,输入批次的大小
3:每个尺度(网格单元)3个Anchor.
Anchors:
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8 小目标:人脸、小动物
- [30, 61, 62, 45, 59, 119] # P4/16 中目标:人体、自行车
- [116, 90, 156, 198, 373, 326] # P5/32 大目标:汽车、卡车
输入640 x 640:
P3: 8倍下采样: 640 / 8 = 80 x 80
P4: 16倍下采样: 640 / 16 = 40 x 40
P5: 32倍下采样: 640 / 32 = 20 x 20
85怎么来的:每个Anchor包含85个数据[x, y, w, h, confidence, class1, class2, …, class80],
具体含义:
- x, y (2个): 边界框中心点坐标
- w, h (2个): 边界框宽度和高度
- confidence (1个): 该位置包含目标的置信度
- classes (80个): COCO数据集80个类别的概率 `nc: 80 # number of classes
3. 修改参数
方法一:修改第一层参数:
# 将通道数由64改成128
[-1, 1, Conv, [128, 6, 2, 2]], # 0-P1/2 64->128
执行test_my_model.py,发现:

第1、2层参数量翻倍,后续没有变化。说明前两层获得的图像特征多了,但是只影响了局部。
方法二:修改C3层重复次数
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 6, C3, [128]], # 修改C3模块,将3->6
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
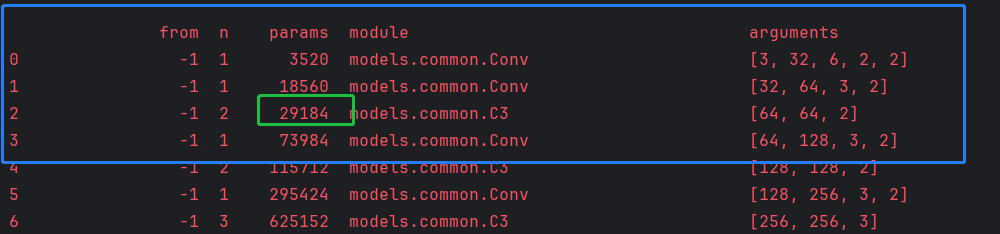
参数量由18816增加到29184,增加了大约55%。
方法三:增加网络层
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]], # C3模块
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, Conv, [1024, 3, 1]], # 人为增加一层
[-1, 1, SPPF, [1024, 5]], # 9
]
同样的计算量和参数量都增加了。
现在开始根据下图进行调整:
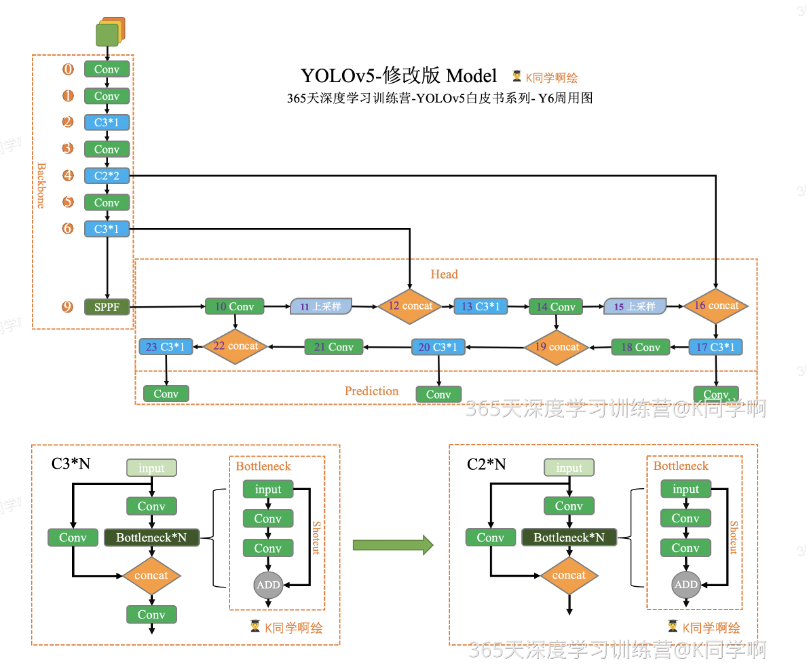
理解一下这张图:
- Backbone(特征提取)
- 通过卷积层(Conv)、C3 模块、C2 模块和 SPPF 逐层提取特征。
- C3 和 C2 是核心的残差结构,区别在于内部是否用 Bottleneck 进行堆叠,以及 shortcut 设计。
- SPPF(Spatial Pyramid Pooling - Fast)用于扩大感受野,增强模型对多尺度目标的感知。
- Head(特征融合)
- 使用上采样(Upsample)、卷积(Conv)、C3 模块和 concat 来进行 FPN+PAN 融合。
- 通过逐层拼接不同尺度的特征,确保小、中、大目标都能被检测到。
- Prediction(输出检测层)
- 在最后输出 3 个尺度的检测头(小目标、中目标、大目标)。
- 每个检测头都会输出 类别预测 + 位置回归 + 置信度。
查了一下common.py代码,并没有实现C2模块,这意味着需要自己实现。
# 新增加一个C2模块
class C2(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
self.cv2 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
y1 = self.cv1(x)
y2 = self.m(y1)
return self.cv2(torch.cat((y1, y2), 1))
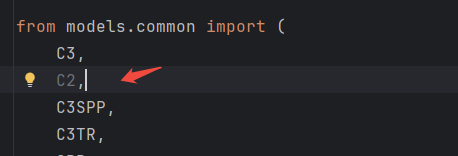
定义好后,注意在要yolo.py中注册一下,否则找不到C2模块:
最后修改yaml文件:
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 1, C3, [128]], # 3 C3模块 ,根据图片C3*1
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 2, C2, [128, 128]], # 4 C2模块,根据图片C2*2
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 1, C3, [512]], # 6 C3模块,根据图片C3*1
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, C3, [1024]], # 8 C3模块,根据图片C3*1
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, "nearest"]], # 11
[[-1, 6], 1, Concat, [1]], # 12 cat backbone P4
[-1, 1, C3, [512, False]], # 13 C3模块,根据图片C3*1
[-1, 1, Conv, [256, 1, 1]], # 14
[-1, 1, nn.Upsample, [None, 2, "nearest"]], # 15
[[-1, 4], 1, Concat, [1]], # 16 cat backbone P3
[-1, 1, C3, [256, False]], # 17 (P3/8-small) C3模块,根据图片C3*1
[-1, 1, Conv, [256, 3, 2]], # 18
[[-1, 14], 1, Concat, [1]], # 19 cat head P4
[-1, 1, C3, [512, False]], # 20 (P4/16-medium)C3模块,根据图片C3*1
[-1, 1, Conv, [512, 3, 2]], # 21
[[-1, 10], 1, Concat, [1]], # 22 cat head P5
[-1, 1, C3, [1024, False]], # 23 (P5/32-large)C3模块,根据图片C3*1
[[17, 20, 23], 1, Detect, [nc, anchors]], # 24Detect(P3, P4, P5)
]
注意backbone的第5行C2模块的使用。
最后测试:
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 1 66176 models.common.C2 [128, 128]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 1 296448 models.common.C3 [256, 256, 1]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 229245 models.yolo.Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
my_YOLOv5s summary: 190 layers, 6857149 parameters, 6857149 gradients, 14.9 GFLOPs
和标准模块对比:
- layers减少了214-190=24层
- 总参数量减少了:7235389-6857149=378240(减少约15%)
- GLOPS从16.6->14.9.
**(三)训练
使用第1天的数据集,训练命令如下:
>python .\train.py --img 640 --batch 16 --epochs 300 --data .\mydata\first.yaml --cfg .\models\my_yolov5s.yaml --weights .\yolov5s.pt --project .\runs\train\ --name c2_640 --cache --workers 0 --device 0 --hyp .\data\hyps\hyp.scratch-low.yaml
验证
> python .\val.py --weights .\runs\train\c2_640\weights\best.pt --data .\mydata\first.yaml --img 640 --task val

预测
python .\detect.py --weights .\runs\train\c2_640\weights\best.pt --source .\mydata\images\fruit0.png --img 640 --conf-thres 0.25 --save-txt --save


注:本次主要是跑通自定义模型,至于精确度的问题,后续再学习。


















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









