









美国国家健康与营养调查( NHANES, National Health and Nutrition Examination Survey)是一项基于人群的横断面调查,旨在收集有关美国家庭人口健康和营养的信息。
地址为:https://wwwn.cdc.gov/nchs/nhanes/Default.aspx
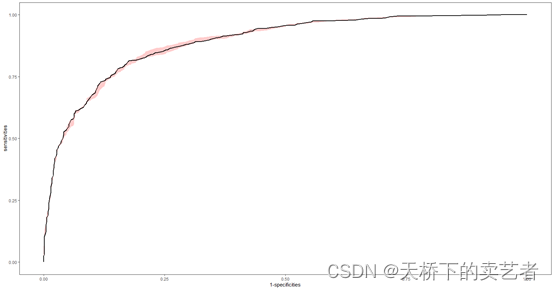
既往咱们已经多篇文章对nhanes数据进行了分析介绍,粉丝私信问:如何行ROC分析,并重抽样获取可信区间。今天来介绍一下。和普通数据还是有点区别的。
导入个我自己下载的NAHNES数据
library(survey)
library(pROC)
library(ggplot2)
bc<-read.csv("E:/r/test/subtext.csv",sep=',',header=TRUE)
bc <- na.omit(bc)
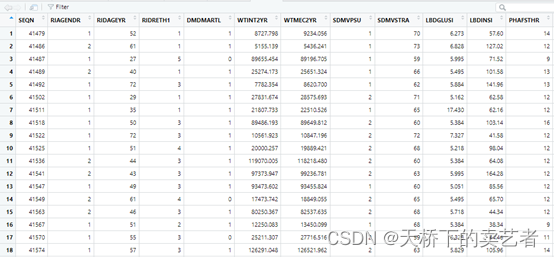
我介绍一下数据,SEQN:序列号,RIAGENDR, # 性别, RIDAGEYR, # 年龄,RIDRETH1, # 种族,DMDMARTL, # 婚姻状况,WTINT2YR,WTMEC2YR, # 权重,SDMVPSU, # psu,SDMVSTRA,# strata,LBDGLUSI, #血糖mmol表示,LBDINSI, #胰岛素( pmmol/L),PHAFSTHR #餐后血糖,LBXGH #糖化血红蛋白,SPXNFEV1, #FEV1:第一秒用力呼气量,SPXNFVC #FVC:用力肺活量,ml(估计肺容量),LBDGLTSI #餐后2小时血糖,factor.FVC是我把肺活量分为了2分类,方便用于测试
先建立一个调查函数,
bcSvy2<- svydesign(ids = ~ SDMVPSU, strata = ~ SDMVSTRA, weights = ~ WTMEC2YR,
nest=TRUE,data = bc)
建立模型,我这里以逻辑回归为例子,其他模型也是一样的
本文为转载文章:原文地址如下:https://mp.weixin.qq.com/s?__biz=MzI1NjM3NTE1NQ==&mid=2247491045&idx=1&sn=241db59550358af7d20294a108f0b589&chksm=ea26fdf9dd5174ef3bbcf087fb9d7d40ad3c922ddcfb5c9bc2631701eb06be28845a80073f76#rd

















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









