









CHARLS 是一项具备中国大陆 45 岁及以上人群代表性的追踪调查,旨在建设一个高质量的公共微观数据库,采集的信息涵盖社会经济状况和健康状况等多维度的信息,以满足老龄科学研究的需要。
为利用国际上最佳的数据采集方式,并确保研究结果的国际可比性CHARLS 参照包括美国的健康与退休研究(HRS)在内的系列国际老龄调查研究开展调查设计。其全国基线调查于 2011-12 年进行,于 2013 年、2015 年、2018 年和 2020 年分别开展了 4 轮常规问卷的追踪调查,并于 2014 年完成了中国中老年人生命历程调查。为确保样本的代表性,CHARLS 基线调查覆盖了全国 150 个国家/地区、450 个村庄/城市社区,涉及 10,257户家庭的 17,708 人,反映了中国中老年人群的总体情况。2019 年底到 2020 年初,新冠疫情在中国爆发,为及时记录新冠疫情对中国中老年人生活和健康的影响,在 2020 年的第 5 轮调查中增加采集了疫情相关的信息。

在文章《Development and validation of a risk prediction model for frailty in patients with diabetes》作者定义了一个虚弱的变量

文章指出:糖尿病可以导致虚弱

作者指出,虚弱Frailty由5个指标定义,

5个指标中存在3个或者3个以上就可以诊断虚弱,我们这里通过使用2013年的数据演示把这个指标提取出来。
先把相关数据导入
setwd("E:/公众号文章2024年/charls数据库/class2") #设置你放数据文件的地址
library(haven)
library(tidyverse)
Health_Status_and_Functioning2013<-read_dta('2013/Health_Status_and_Functioning.dta')
Demographic_Background <- read_dta('2013/Demographic_Background.dta')
biomarker<- read_dta('2013/Biomarker.dta')
Health_Care_and_Insurance <- read_dta('2013/Health_Care_and_Insurance.dta')
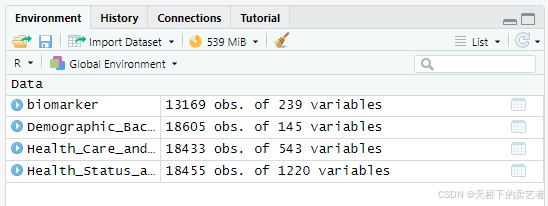
导入后把数据进行合并
data<- left_join(Health_Status_and_Functioning2013, Health_Care_and_Insurance, by='ID')%>%
left_join(biomarker, by='ID')%>%left_join(Health_Care_and_Insurance, by='ID')
咱们先对第一个项目:使用自我报告的项目“难以举起或搬运超过 5 公斤的重量”来衡量虚弱的变量进行提取
这个变量来自:db008和db009,我们可以看到除了1以外都是有困难的
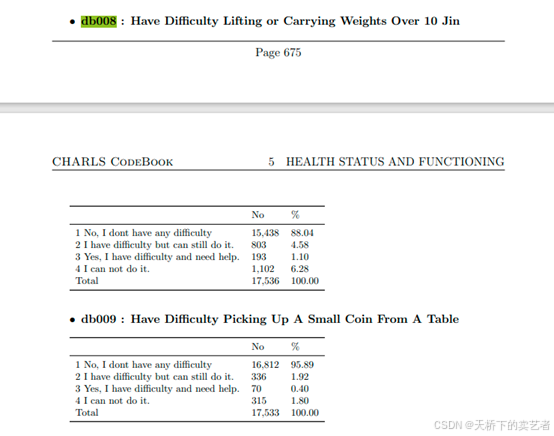
data$Weak1<-ifelse(data$db008==1,0,1)
data$Weak2<-ifelse(data$db009==1,0,1)
data$Weak<-ifelse(data$Weak1==1 | data$Weak2==1,1,0)
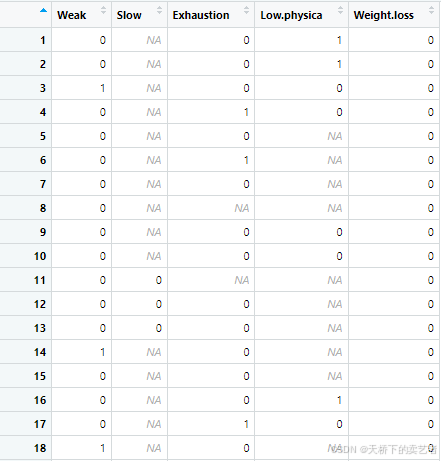
然后依次把其他4个指标提取
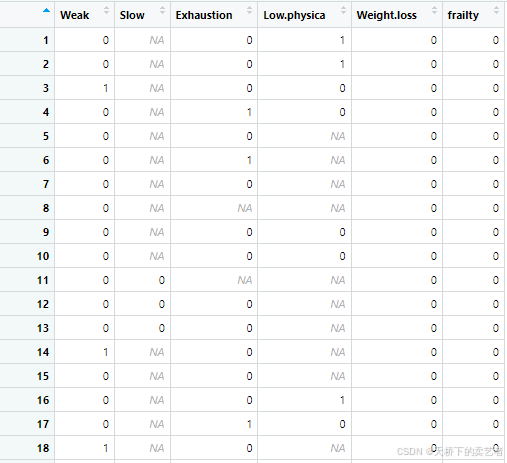
最后把评分大于等于3的默认为1就行了
原创不易,需要全套代码的粉丝,把公众号的本篇文章转发朋友圈,集10个赞后,截图发给我,嫌麻烦的话直接给我打赏5元,截图发给我也可以。


















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











