







 本文详细解析了SSD(Single Shot MultiBox Detector)的tensorflow实现,包括多尺度特征图检测网络结构、anchor boxes生成、ground truth预处理和目标函数。SSD结合了Faster R-CNN的准确性与YOLO的检测速度,实现实时高精度目标检测。关键点包括:1)多尺度特征图检测;2)不同尺度与长宽比的默认框生成;3)正负样本匹配;4)位置与类别损失函数设计。
本文详细解析了SSD(Single Shot MultiBox Detector)的tensorflow实现,包括多尺度特征图检测网络结构、anchor boxes生成、ground truth预处理和目标函数。SSD结合了Faster R-CNN的准确性与YOLO的检测速度,实现实时高精度目标检测。关键点包括:1)多尺度特征图检测;2)不同尺度与长宽比的默认框生成;3)正负样本匹配;4)位置与类别损失函数设计。
http://blog.csdn.net/mydear_11000/article/details/73867041
SSD(SSD: Single Shot MultiBox Detector)是采用单个深度神经网络模型实现目标检测和识别的方法。如图0-1所示,该方法是综合了Faster R-CNN的anchor box和YOLO单个神经网络检测思路(YOLOv2也采用了类似的思路,详见YOLO升级版:YOLOv2和YOLO9000解析),既有Faster R-CNN的准确率又有YOLO的检测速度,可以实现高准确率实时检测。在300*300分辨率,SSD在VOC2007数据集上准确率为74.3%mAP,59FPS;512*512分辨率,SSD获得了超过Fast R-CNN,获得了80%mAP/19fps的结果,如图0-2所示。SSD关键点分为两类:模型结构和训练方法。模型结构包括:多尺度特征图检测网络结构和anchor boxes生成;训练方法包括:ground truth预处理和损失函数。本文解析的是SSD的tensorflow实现源码,来源balancap/SSD-Tensorflow。本文结构如下:
1,多尺度特征图检测网络结构;
2,anchor boxes生成;
3,ground truth预处理;
4,目标函数;
5,总结
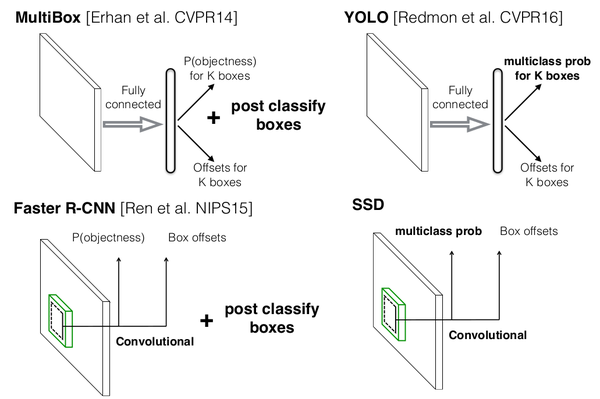
图0-1 SSD与MultiBox,Faster R-CNN,YOLO原理(此图来源于作者在eccv2016的PPT)
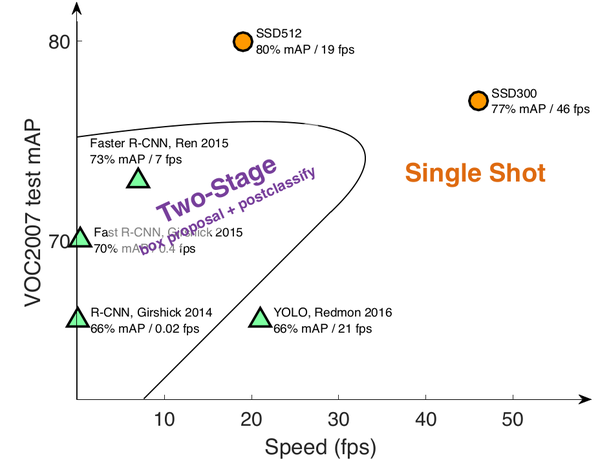
图0-2 SSD检测速度与精确度。(此图来源于作者在eccv2016的PPT)
1 多尺度特征图检测网络结构
SSD的网络模型如图1-1所示。
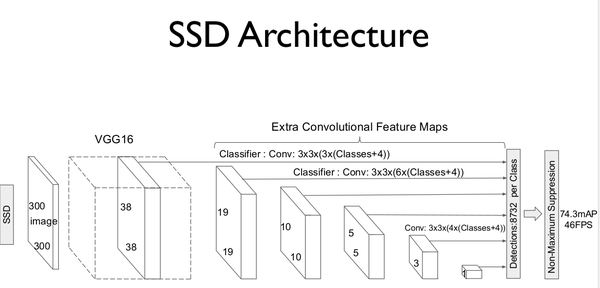
图1-1 SSD模型结构。(此图来源于原论文)
模型建立源代码包含于ssd_vgg_300.py中。模型多尺度特征图检测如图1-2所示。模型选择的特征图包括:38×38(block4),19×19(block7),10×10(block8),5×5(block9),3×3(block10),1×1(block11)。对于每张特征图,生成采用3×3卷积生成 默认框的四个偏移位置和21个类别的置信度。比如block7,默认框(def boxes)数目为6,每个默认框包含4个偏移位置和21个类别置信度(4+21)。因此,block7的最后输出为(19*19)*6*(4+21)。
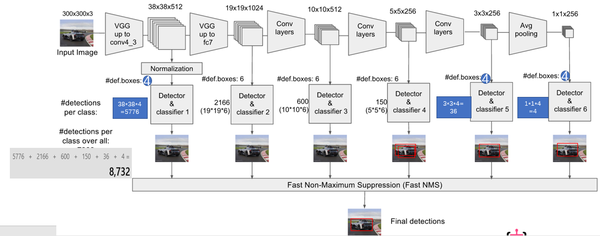
图1-2 多尺度特征采样(此图来源:知乎专栏)
其中,初始化参数如下:
"""
Implementation of the SSD VGG-based 300 network.
The default features layers with 300x300 image input are:
conv4 ==> 38 x 38
conv7 ==> 19 x 19
conv8 ==> 10 x 10
conv9 ==> 5 x 5
conv10 ==> 3 x 3
conv11 ==> 1 x 1
The default image size used to train this network is 300x300.
"""
default_params = SSDParams(
img_shape=(300, 300),#输入尺寸
num_classes=21,#预测类别20+1=21(20类加背景)
#获取feature map层
feat_layers=['block4', 'block7', 'block8', 'block9', 'block10', 'block11'],
feat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)],
# 每个特性层上的anchor大小都不一样, 越靠近输入的层其anchor越小。
# 确定第一个与最后一个feature层的anchor大小以后, 处于中间的层的anchor大小则通过线性插值计算而来。例如,假如anchor_size_bounds = [0.2, 0.7], 有6个feature layer,则每个layer对应的default anchor大小为:[0.2, 0.3, 0.4, 0.5, 0.6, 0.7].
anchor_size_bounds=[0.15, 0.90],
#anchor boxes的大小
anchor_sizes=[(21., 45.),
(45., 99.),
(99., 153.),
(153., 207.),
(207., 261.),
(261., 315.)],
#anchor boxes的aspect ratios
anchor_ratios=[[2, .5],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5, 3, 1./3],
[2, .5],
[2, .5]],
anchor_steps=[8, 16, 32, 64, 100, 300],#anchor的层
anchor_offset=0.5,#补偿阀值0.5
normalizations=[20, -1, -1, -1, -1, -1],#该特征层是否正则,大于零即正则;小于零则否
prior_scaling=[0.1, 0.1, 0.2, 0.2]
)
建立模型代码如下,作者采用了TensorFlow-Slim(类似于keras的高层库)来建立网络模型,详细内容可以参考TensorFlow-Slim网页。
#建立ssd网络函数
def ssd_net(inputs,
num_classes=21,
feat_layers=SSDNet.default_params.feat_layers,
anchor_sizes=SSDNet.default_params.anchor_sizes,
anchor_ratios=SSDNet.default_params.anchor_ratios,
normalizations=SSDNet.default_params.normalizations,
is_training=True,
dropout_keep_prob=0.5,
prediction_fn=slim.softmax,
reuse=None,
scope='ssd_300_vgg'):
"""SSD net definition.
"""
# End_points collect relevant activations for external use.
#用于收集每一层输出结果
end_points = {}
#采用slim建立vgg网络,网络结构参考文章内的结构图
with tf.variable_scope(scope, 'ssd_300_vgg', [inputs], reuse=reuse):
# Original VGG-16 blocks.
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
end_points['block1'] = net
net = slim.max_pool2d(net, [2, 2], scope='pool1')
# Block 2.
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
end_points['block2'] = net
net  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3773
3773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









