







DeepSeek最新发布的Janus-Pro、Janus、JanusFlow三大模型,分别瞄准理解、生成、动态推理三大战场,性能全面碾压Stable Diffusion、DALL-E 3!
Janus架构
作者介绍了一种名为Janus的自回归框架,它将多模态理解与生成统一起来。之前的研究通常依赖单一的视觉编码器来同时完成这两项任务,例如Chameleon。然而,由于多模态理解和生成对信息粒度的需求不同,这种方法可能会导致性能不够理想,尤其是在多模态理解任务中。为了解决这个问题,作者提出将视觉编码解耦为独立的路径,同时仍然利用单一的统一Transformer架构进行处理。这种解耦方式不仅缓解了视觉编码器在理解和生成任务中角色冲突的问题,还提升了框架的灵活性。比如,多模态理解和生成组件可以独立选择最适合自己的编码方式。实验结果表明,Janus不仅超越了之前的统一模型,还能够匹敌甚至超越任务特定模型的性能。Janus的简洁性、高灵活性和高效性让我认为,它有潜力成为下一代统一多模态模型的有力竞争者。
架构图
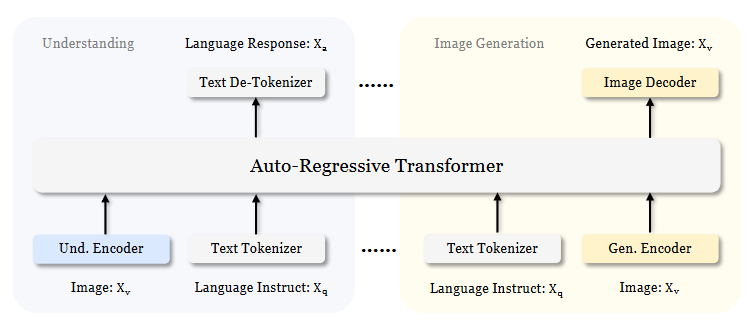
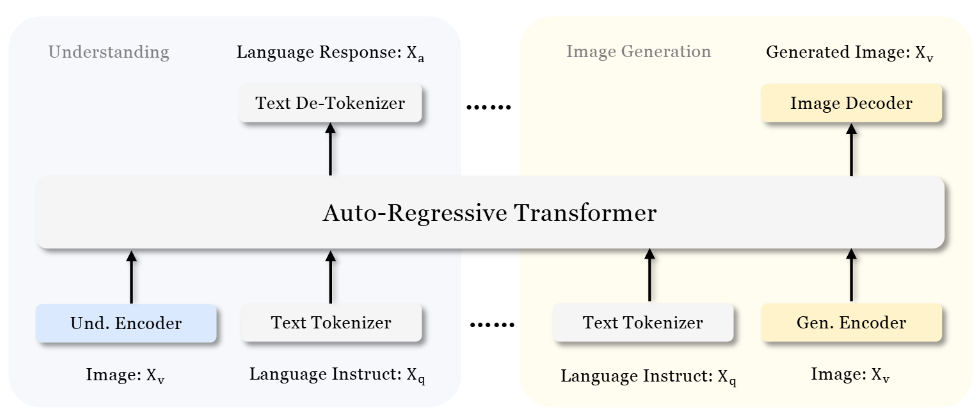
与之前的方法通常假设视觉理解和生成需要使用相同的视觉编码器不同,Janus 将视觉编码过程解耦,分别为视觉理解和视觉生成提供独立的编码器。“Und. Encoder” 和 “Gen. Encoder” 分别是 “Understanding Encoder” 和 “Generation Encoder” 的缩写。
训练策略
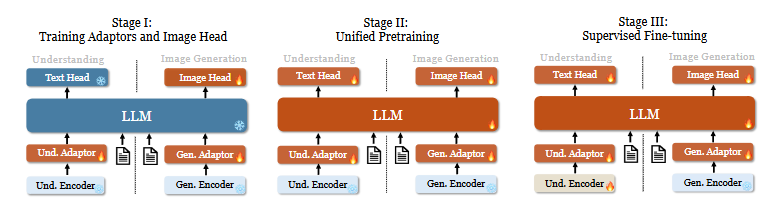
第一阶段:训练适配器和图像头部
在阅读这部分内容时,我了解到该阶段的主要目标是,在嵌入空间中建立视觉和语言元素之间的概念联系,使大语言模型(LLM)能够理解图像中展示的实体,并具备初步的视觉生成能力。在此阶段,视觉编码器和LLM保持冻结状态,仅更新理解适配器、生成适配器和图像头部中的可训练参数。
第二阶段:统一预训练
这一阶段的目的是通过多模态语料的统一预训练,让Janus同时学习多模态理解和生成能力。作者解冻了LLM,并使用了多种训练数据:纯文本数据、多模态理解数据以及视觉生成数据。受Pixart的启发,训练从简单的视觉生成任务开始,利用ImageNet-1k帮助模型掌握基本的像素依赖关系。随后,使用通用的文本到图像数据进一步增强模型在开放领域的视觉生成能力。
第三阶段:监督微调
在这一阶段,我注意到模型通过指令调优数据进行微调,以提升其指令执行和对话能力。除生成编码器外,所有参数都参与微调。微调时关注对答案的监督,同时屏蔽系统和用户提示信息。为了确保Janus在多模态理解和生成中的能力不偏向某一任务,作者并未针对特定任务单独微调模型,而是结合了纯文本对话数据、多模态理解数据以及视觉生成数据,确保模型在多种场景下的通用性。
Janus-Pro架构
Janus-Pro基于 DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base 构建,超越了之前的统一模型,并且达到或超过了特定任务模型的性能。Janus-Pro 的简单性、高灵活性和有效性使其成为下一代统一多模态模型的有力候选者。
架构图
训练策略
第一阶段的训练时间被延长:作者增加了第一阶段的训练步数,以便在ImageNet数据集上进行充分训练。研究表明,即使大语言模型(LLM)的参数保持不变,模型依然能够有效建模像素之间的依赖关系,并根据类别名称生成合理的图像。
在第二阶段,我注意到训练变得更加聚焦:作者不再使用ImageNet数据,而是直接利用常规的文本到图像数据,训练模型根据更详细的描述生成图像。这种重新设计的方式使得第二阶段能够更高效地利用文本到图像数据,从而提高了训练效率和整体性能。
生成效果对比

JanusFlow架构
作者提出了JanusFlow,这是一个强大的框架,能够在单一模型中统一图像理解与生成任务。JanusFlow采用了一种极简架构,将自回归语言模型与Rectified Flow(生成建模中的一种先进方法)相结合。作者的核心发现表明,Rectified Flow可以直接在大型语言模型框架内进行训练,无需复杂的架构修改。为了进一步提升统一模型的性能,作者采用了两种关键策略:
- 解耦理解与生成编码器;
- 在统一训练过程中对齐它们的表示。
大量实验表明,JanusFlow在各自领域内与专用模型性能相当甚至更优,同时在标准基准测试中显著优于现有的统一方法。这项工作代表了向更高效、多功能的视觉语言模型迈出的一步。
架构图
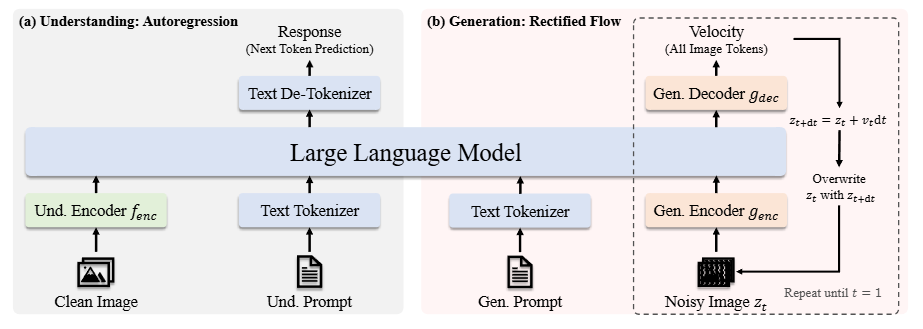
训练策略图
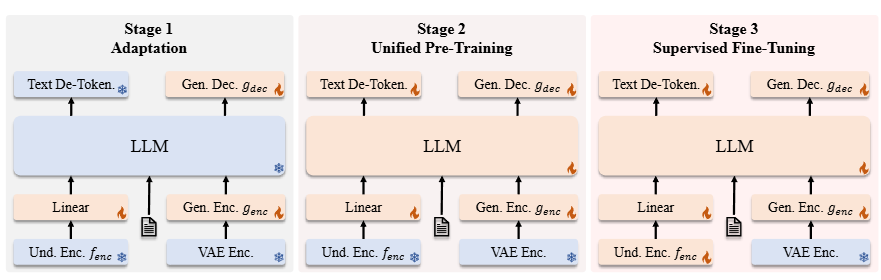
第一阶段:随机初始化组件的适配
在阅读这部分内容时,我了解到第一阶段的重点是训练随机初始化的组件,包括线性层、生成编码器和生成解码器。这一阶段旨在使这些新模块能够与预训练的大语言模型(LLM)和SigLIP编码器有效协作,主要起到为新引入组件初始化的作用。
第二阶段:统一预训练
适配阶段完成后,作者开始对整个模型进行训练,视觉编码器除外,这与之前的方法一致。在这一阶段,训练数据包括三种类型:多模态理解数据、图像生成数据和纯文本数据。训练初期会分配更多的多模态理解数据,以建立模型的理解能力。随后逐步增加图像生成数据的比例,以满足基于扩散模型的收敛需求。
第三阶段:监督微调(SFT)
在最后阶段,作者通过指令调优数据对预训练模型进行微调。这些数据包括对话、特定任务的交互以及高质量的文本条件图像生成示例。在此阶段,SigLIP编码器的参数也被解冻。这一微调过程让我看到,模型能够在多模态理解和图像生成任务中,有效地响应用户的指令。
链接:https://github.com/deepseek-ai/Janus
总结
Janus架构与DeepSeek低成本策略的技术革新
1. 降低多模态模型开发门槛,推动技术普惠
- 低成本架构设计:
Janus系列通过视觉编码器解耦与分阶段训练策略,显著降低训练资源需求。例如:- 冻结参数策略:第一阶段仅训练适配器和图像头部,避免全模型微调的高算力消耗;
- 渐进式训练:从简单生成任务(ImageNet-1k)逐步过渡到复杂场景,减少早期训练成本;
- 复用LLM能力:基于DeepSeek-LLM的预训练知识,无需从头构建多模态对齐。
行业价值:中小企业可基于开源代码快速部署多模态模型,无需依赖超算集群,推动AI技术下沉至中小企业和学术机构。
2. 统一模型终结“碎片化”任务场景
- 多任务一体化突破:
Janus在单一模型中实现理解-生成双优性能(如生成效果对比图所示),其核心创新包括:- 双编码器解耦:独立优化理解(Und. Encoder)与生成(Gen. Encoder),避免传统单编码器的任务冲突;
- Rectified Flow集成(JanusFlow):将生成建模直接嵌入LLM框架,无需额外扩散模型架构;
- 动态数据配比:预训练阶段逐步增加生成数据比例,平衡多任务学习效率。
行业价值:企业可减少部署多个专用模型(如CLIP+DALL·E+GPT)的运维成本,适用于客服、教育、设计等需多模态交互的场景。
3. 生成质量与效率的平衡
- 对标专用模型的性能:
Janus-Pro在生成效果对比中展现与Stable Diffusion匹敌的细节刻画能力,关键策略包括:- LLM驱动生成:利用DeepSeek-LLM的语义理解生成合理像素依赖关系;
- 两阶段生成训练:先通过ImageNet学习基础结构,再用开放域数据提升泛化性;
- 监督微调聚焦对齐:屏蔽无关提示信息,强化答案生成精准度。
行业价值:内容创作行业(如广告、影视)可直接用统一模型完成从文案理解到高质量图像生成的端到端流程,缩短创作周期。
4. 开源生态与行业标准重构
- 代码开源与模块化设计:
GitHub开放的Janus实现允许企业:- 灵活替换组件:例如替换SigLIP为其他视觉编码器,适配私有数据格式;
- 定制训练策略:根据业务需求调整三阶段训练的数据比例(如电商场景增加商品描述生成权重);
- 快速迭代能力:社区贡献可加速修复生成偏差等问题。
行业影响:可能催生多模态开发框架的“Janus化”趋势,挤压封闭式API(如Midjourney企业版)的市场空间。
5. 潜在挑战与应对
- 推理效率优化:
双编码器设计可能增加推理延迟,需通过模型蒸馏或编码器轻量化(如MobileViT)解决。 - 数据安全合规:
开源模型需企业加强私有数据训练管控,避免敏感信息泄露。 - 领域适配成本:
医疗、工业等垂直领域仍需领域数据微调,但Janus分阶段训练可降低微调算力需求。
结论
DeepSeek的Janus架构通过解耦设计与低成本训练策略,重新定义了多模态模型的开发范式。其技术路径将加速行业从“专用模型堆砌”向“统一智能体”转型,预计在3-5年内推动以下变革:
- 成本下降:多模态模型训练成本降低50%以上;
- 场景扩展:催生XR交互、实时跨模态搜索等新应用;
- 生态重构:开源社区主导多模态标准制定,打破巨头技术垄断。
企业需重点关注Janus生态的工具链完善(如部署优化工具),以抢占下一代人机交互入口。

















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









