









 本文介绍Peephole网络,一种基于LSTM与MLP的神经网络,用于预测图像识别网络的性能。通过编码神经网络结构并利用LSTM处理序列数据特性,Peephole能在训练前预测网络性能。文章探讨了LSTM的使用原因、神经网络结构的编码方法、训练数据来源及实验细节。
本文介绍Peephole网络,一种基于LSTM与MLP的神经网络,用于预测图像识别网络的性能。通过编码神经网络结构并利用LSTM处理序列数据特性,Peephole能在训练前预测网络性能。文章探讨了LSTM的使用原因、神经网络结构的编码方法、训练数据来源及实验细节。
文章目录
主要工作
NAS中,为了加速算法的运行,有许多方法,包括surrogate-based与early stop,这篇论文使用的是surrogate-based,具体工作即提出了一种可以在训练图像识别网络之前预测其性能(测试准确率)的神经网络,该神经网络基于LSTM与MLP,名为Peephole。
Peephole网络结构
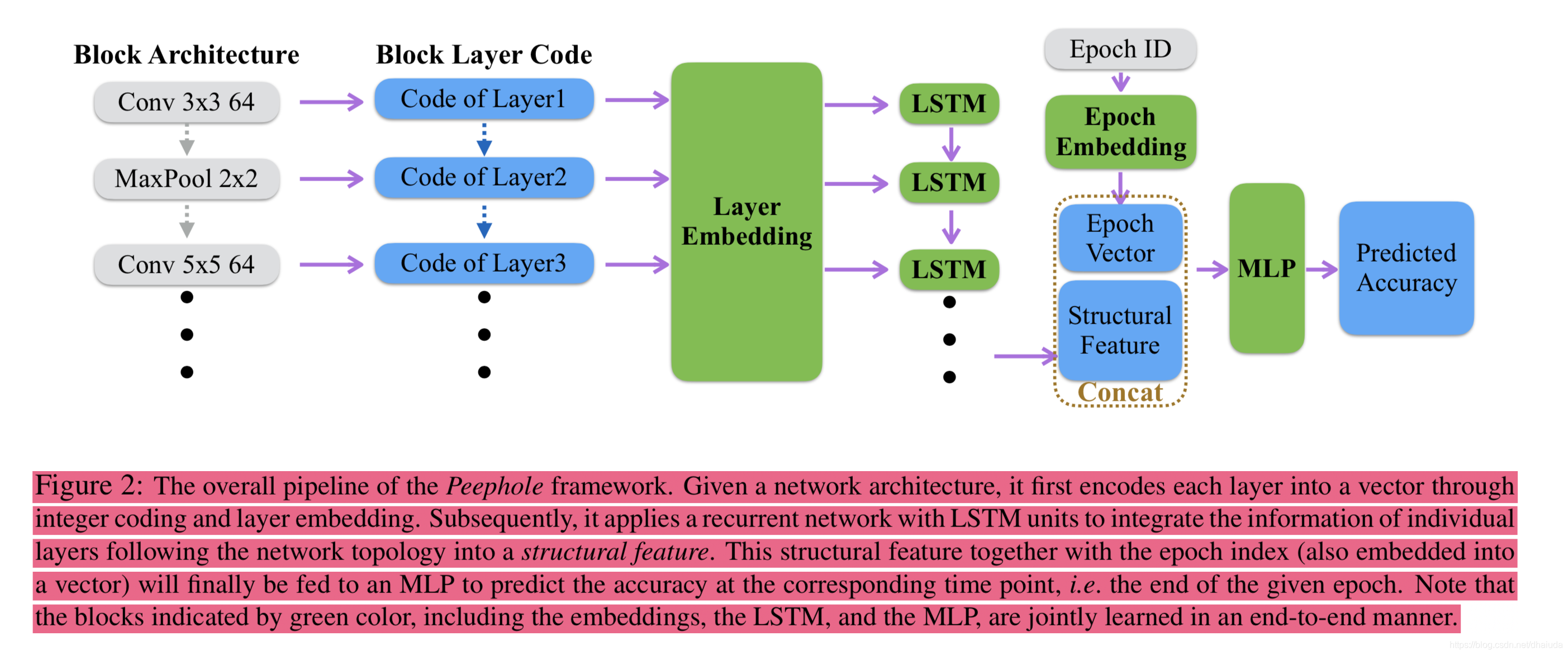
网络工作的流程如下:
- 对神经网络的每一层进行编码,获得层编码。
- 对层编码进行Embedded,输入到LSTM中,将LSTM的输出作为结构特征。
- 由于神经网络的性能与训练轮数有关,因此,对epoch(神经网络训练的轮数)也要进行Embedded,得到Epoch Vector。
- 将二、三步得到的向量concat,输入到MLP(前馈神经网络)中,预测最终的性能。
基于Peephole的工作流程,我们可以得出几个疑问
- 为什么要使用LSTM?
- 如何对神经网络结构进行编码?
- 训练数据从何而来?
为什么要使用LSTM?
论文中并没有解释为什么使用LSTM,以下为自己的理解:
神经网络的性能与神经网络的结构有一定的关系,深层(例如池化层)的表现受浅层(例如卷积层)的影响,类似于某一个单词的含义取决于上文,这和序列数据非常相似,而LSTM、RNN等序列模型则用于处理序列数据,直觉上来说,我们是否可以对神经网络的结构进行编码排序,并利用LSTM建立编码排序与神经网络性能之间的关系呢?
以上便是我认为的使用LSTM的灵感来源,事实上,目前预测网络性能的文献中,也能见到RNN、LSTM的身影。
如何对神经网络结构进行编码?
具体来说,分为两个步骤:
- Integer coding
- Layer embedding
Integer coding
神经网络中层与层之间的顺序可以通过编码后的先后顺序决定,问题是—如何让编码尽可能的反映该层的特征,例如卷积层的特征有卷积核大小、步伐数、卷积核个数等等,论文使用一个四元组
(
T
Y
,
K
W
,
K
H
,
C
H
)
(TY,KW,KH,CH)
(TY,KW,KH,CH)来描述某一层的特征,具体的含义及取值如下:
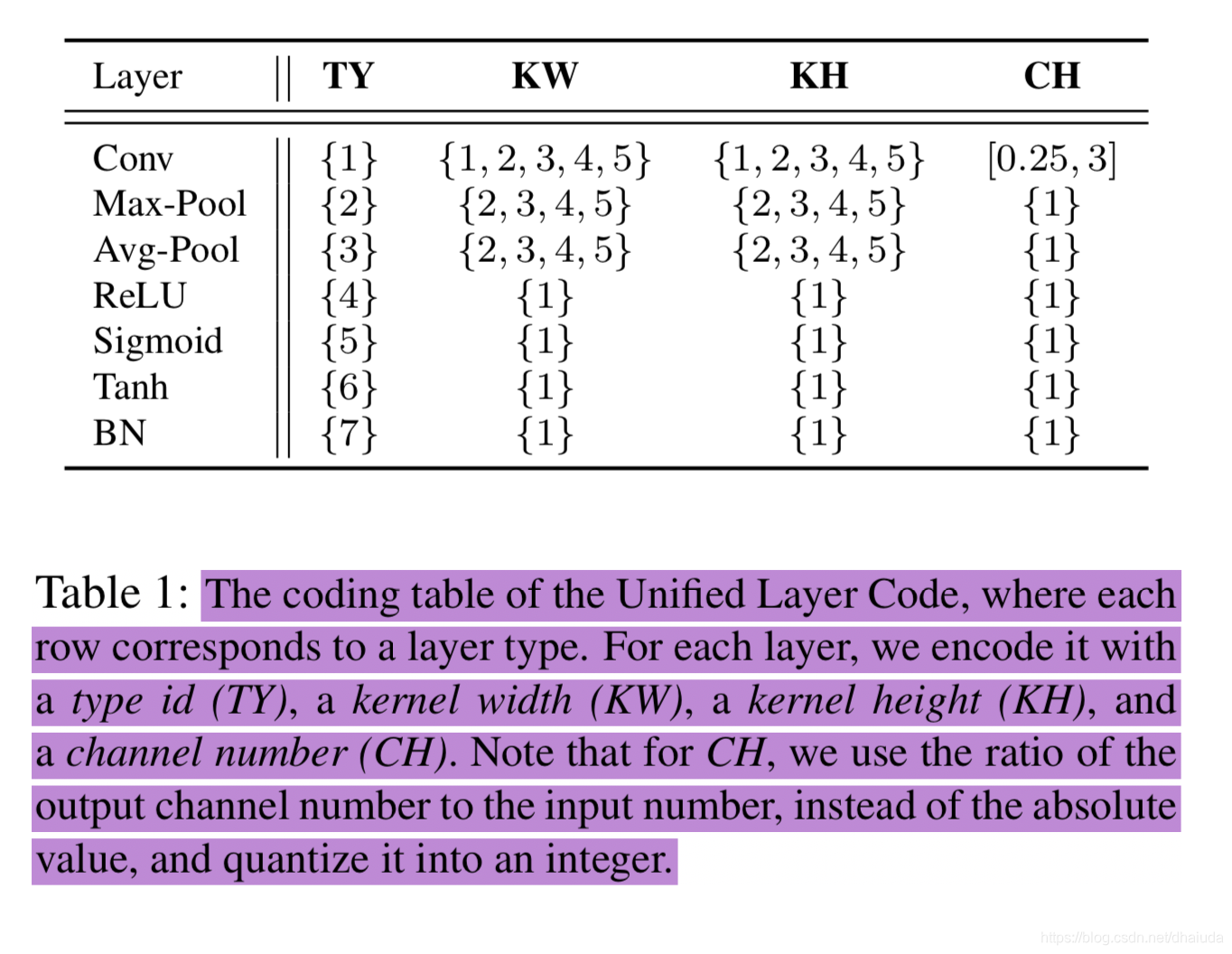
注意到论文都是使用卷积核、池化核来描述卷积层与池化层,对于激活函数与BN,我们也可以用"激活函数核"以及"BN核"来描述激活函数层与BN层,这两层都是element-wise的,因此"核"的大小为1*1。
Layer embedding
Integer coding是离散表示法,不适用于复杂的数值计算和深度模式识别,因此,作者引入了Layer Embedding,将Integer coding转换为向量表示,这和自然语言中处理很像。
整个流程如下:
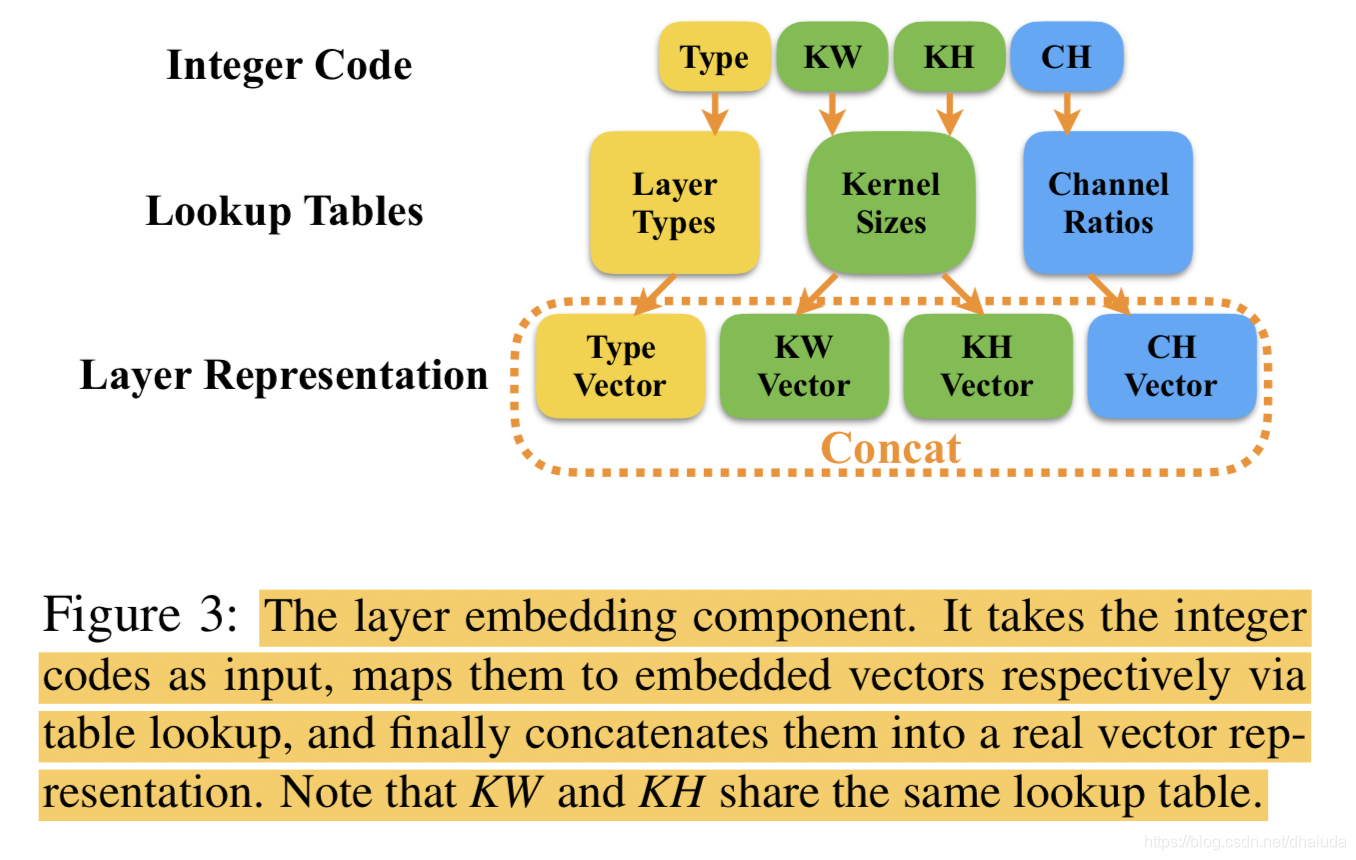
个人思考
上述的编码方式可以说是最简单直观的编码方式,无法考虑基本的残差结构,而合适的残差结构可以提高网络的测试准确率,这意味着上述编码只能针对于没有残差结构的网络,该论文对神经网络结构的编码方式决定了Peephole可以预测性能的神经网络结构,这类神经网络将不存在残差结构,这是一种损失。
训练数据从何而来?
Peephole肯定是对具有某一类特点的神经网络进行预测的,一般来说,一个神经网络搜索空间中的神经网络都具有某一类特征,因此,我们需要构建一个神经网络搜索空间。
Block-based Generation搜索空间
从神经网络结构的编码方式来看,搜索空间中神经网络的结构必然比较简单,收到NASNet Search Space的影响,作者提出了Block-based Generation搜索空间,如下:
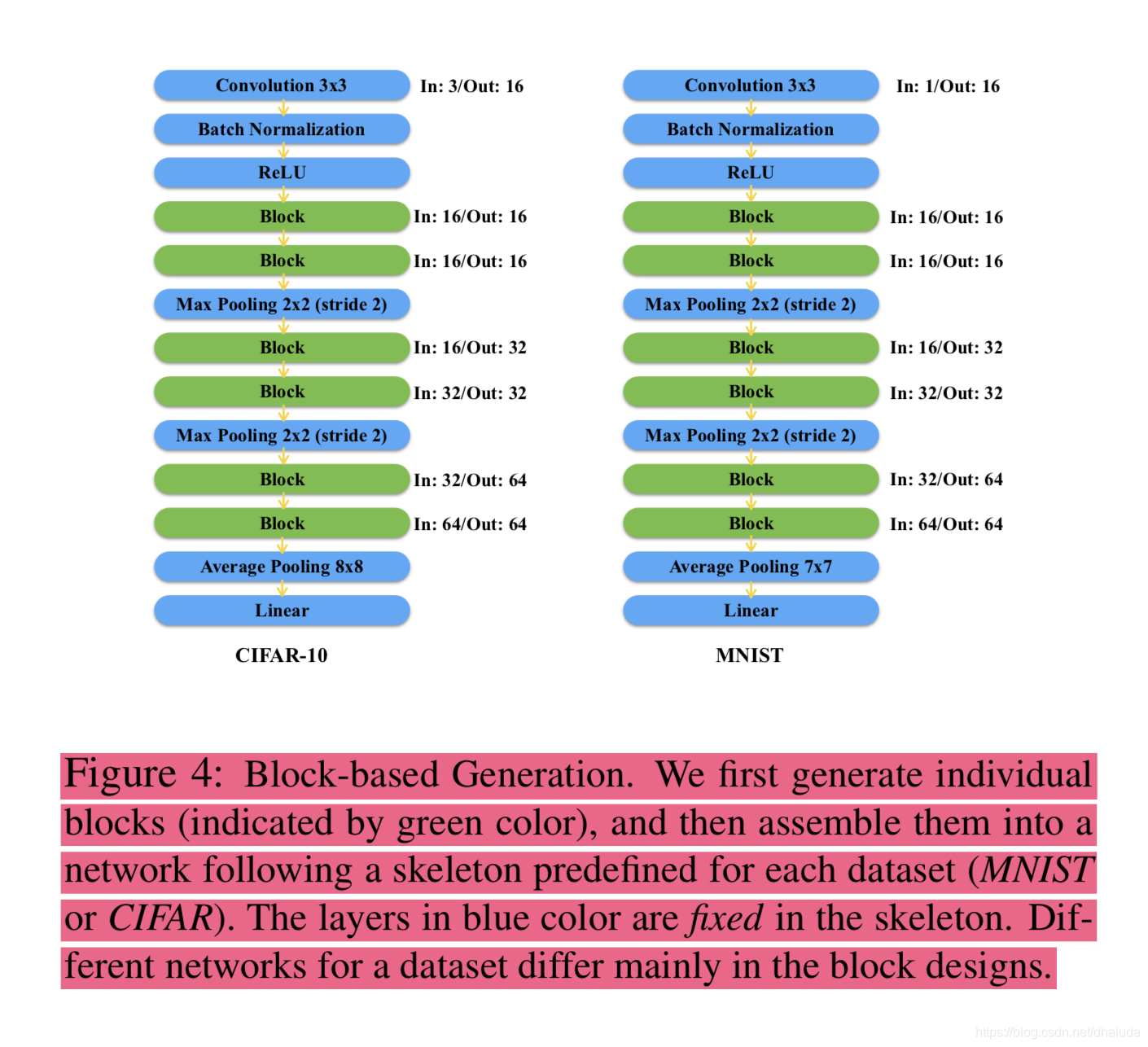
关于NASNet Search Space以及其设计灵感,可以查看我之前的博客NAS论文笔记(使用RL进行NAS):Learning Transferable Architectures for Scalable Image Recognition,接着就能大致理解Block-based Generation的想法了。
现在的问题是,Block长啥样?
Block的结构
具有几个要点
- 每个Block的层数小于等于10
- 卷积核的大小从 { 1 , 2 , 3 , 4 , 5 } \{1,2,3,4,5\} {1,2,3,4,5}中随机选择,卷积核的CH从 { 0.25 , 0.5 , 0.75 , 1 , 1.5 , 2 , 2.5 , 3 } \{0.25,0.5,0.75,1,1.5,2,2.5,3\} {0.25,0.5,0.75,1,1.5,2,2.5,3}中随机选择
- 池化层的大小从 { 1 , 2 , 3 , 4 , 5 } \{1,2,3,4,5\} {1,2,3,4,5}中随机选择
- 必要时,插入1*1卷积用来调整特征图大小
Block的构建流程如下:
- 依据实际经验,计算某种类型的层,后接其它层的概率,例如卷积层后接激活函数层或是BN层的概率。
- 依据当前层的类型以及步骤一中的概率,选择下一层,例如当前层为卷积层,那么就有较大概率选择激活函数层或是BN层作为下一层。
实验
Peephole的训练细节
数据来源
在数据集上先训练一匹神经网络,获得有监督数据,如下图:
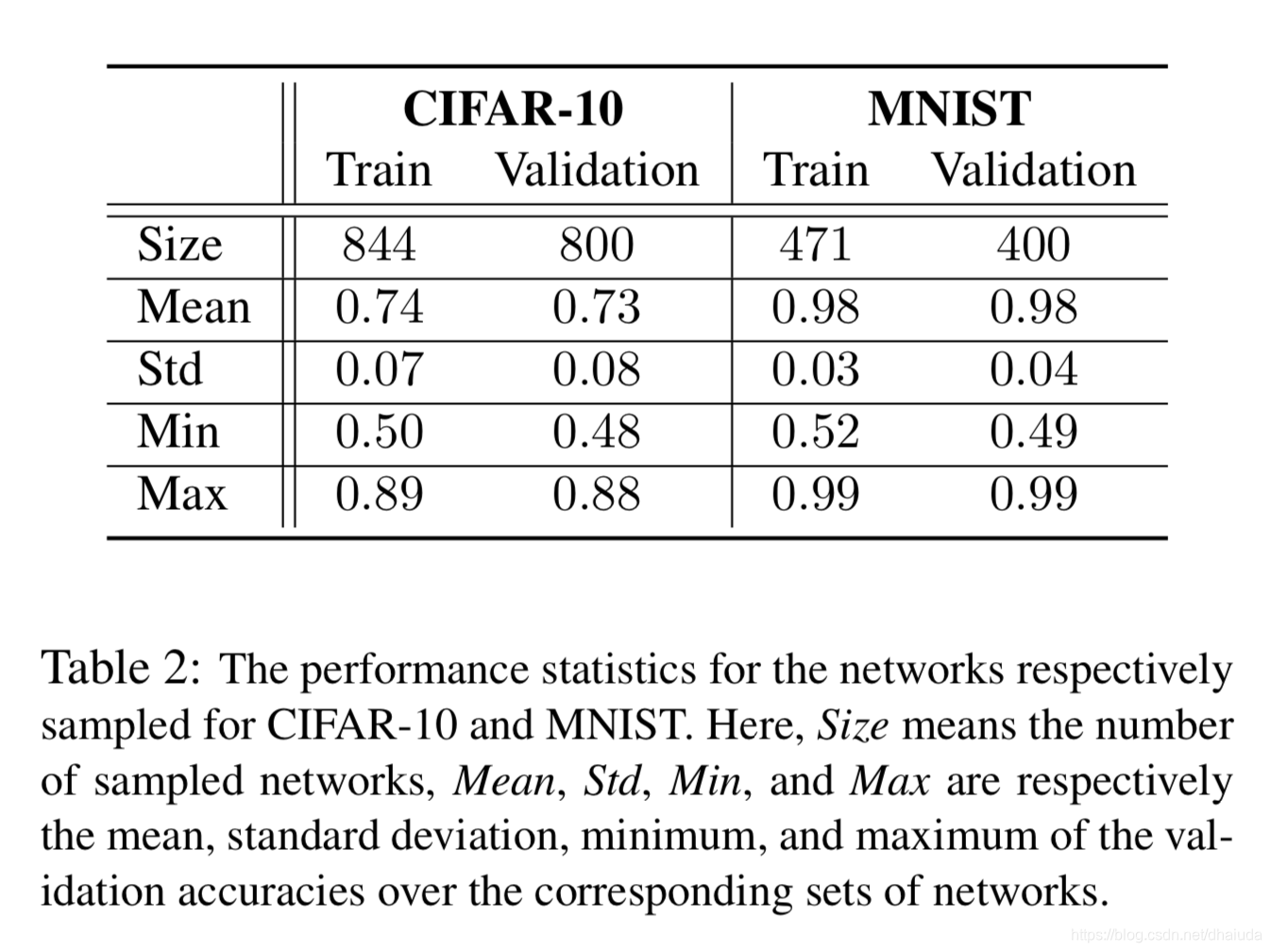
论文没有解释train与validation是什么,应该就是训练数据和测试数据吧,可以看到,数据量还是比较少的。
损失函数
使用带L1正则化的MSE
其他训练细节
- 每个神经网络训练 T T T轮,虽然可以将每一轮训练的结果都作为训练数据,但作者发现,只需要最后一轮的结过作为训练数据即可较好的训练Peephole。
- 所有的神经网络都采用统一配置进行训练,例如初始化方法(MSRA)、优化算法、学习率等
- layer Embedding与epoch Embedding为40维的向量,LSTM隐藏层(hidden state)的输出为160维
- MLP有三层,每层有200个神经元
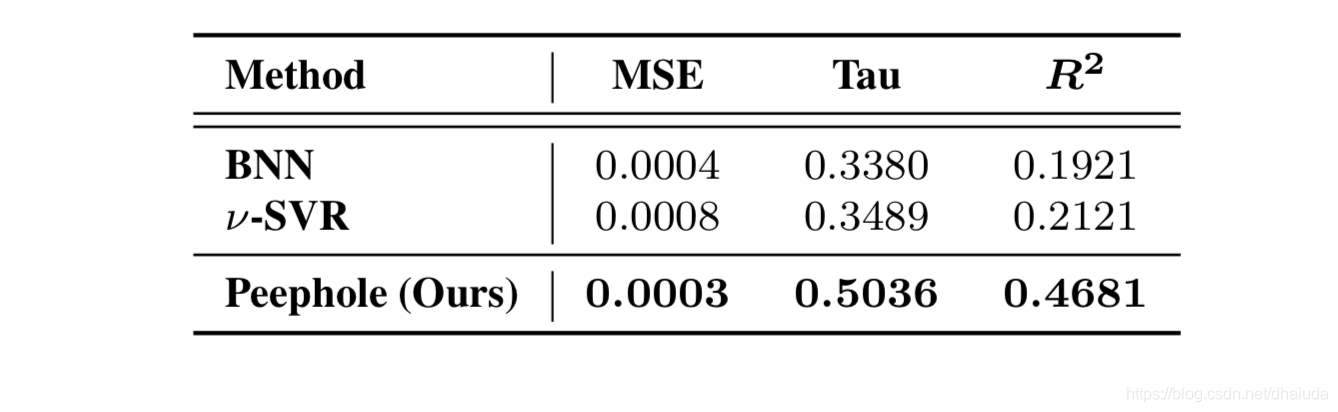
与其他预测方法的比较
论文比对了其他两类预测网络性能的模型
- Bayesian Neural Network (BNN)
- ν -Support Vector Regression (ν -SVR)
上述两个方法都是early stop,而Peephole是surrogate-based,使用的性能衡量指标包括
- M S E MSE MSE(均方误差)
- R 2 R^2 R2
- K e n d a l l R a n k Kendall Rank KendallRank(肯德尔等级)相关系数
在CIFAR-10与MNIST的比对结果如下:
CIFAR-10

MNIST
在CIFAR-10上测试准确率与预测准确率的散点图
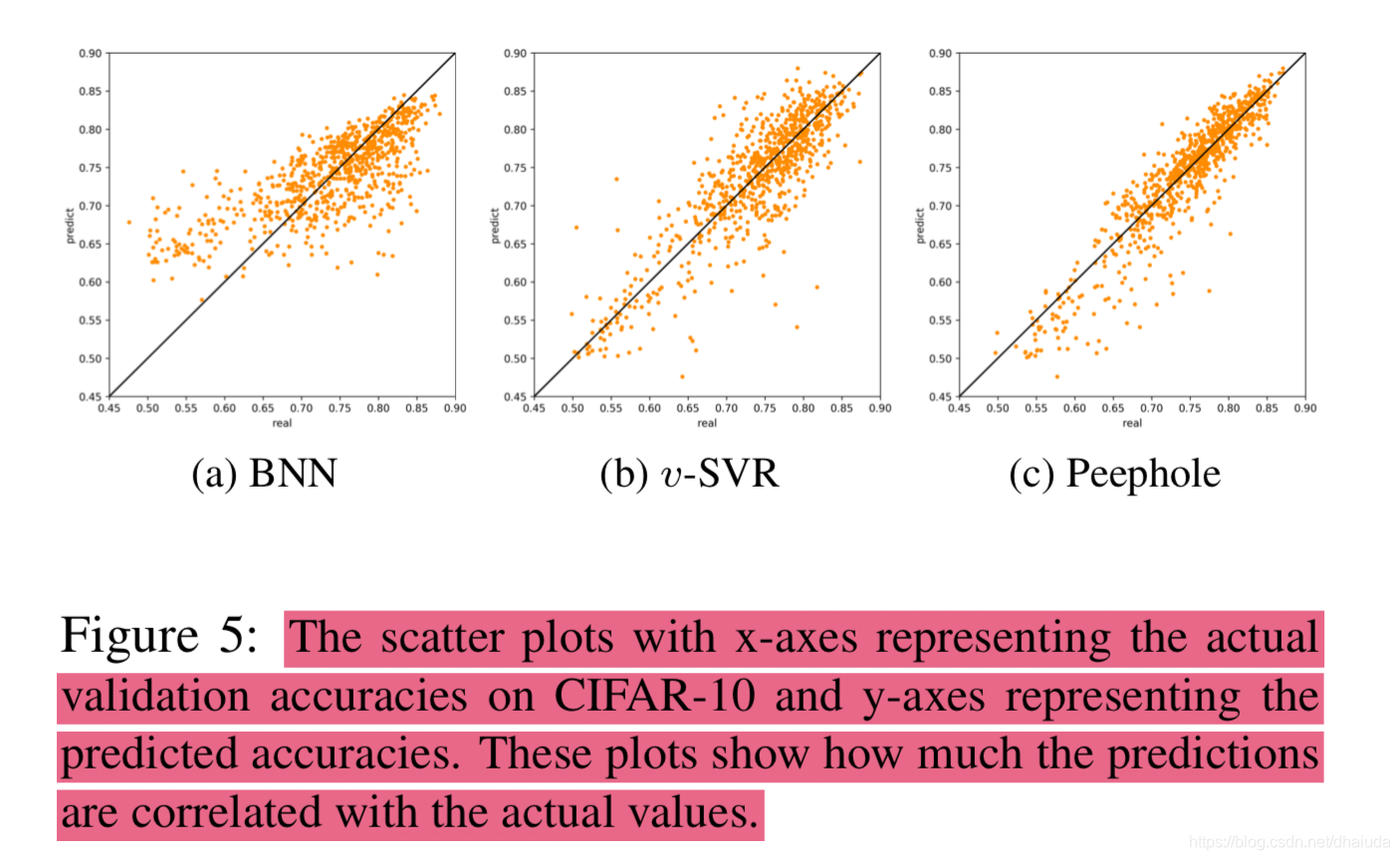
可以看到,表现是非常优异的。

















 3481
3481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









