







前言
轮询优先仲裁常用于valid—ready握手的mux或者记录模块中选出或者写入的entry,工作中以前经常使用,但是没有深入学习理解其原理,最近刚好有时间,所以详细学习一下其算法原理,在这里进行记录,并贴出verilog代码;
基本原理:
round robin(rr)轮询优先级仲裁,根本原理是考虑公平性,区别于固定优先仲裁【对每个master分配固定的优先级,低优先级的master只有在高优先级的master被处理后,或者高优先级的master没有访问需求的时候才会被响应】轮询优先仲裁对各个master的响应随各个master的请求轮询变化,当一个master得到响应后,其优先级在接下来的仲裁中就会变为最低,其余master的响应优先级会进行相应的调整,通过这种方式,可以均匀的将master的访问分配下去;
首先举一个例子理解round_robin,假设时钟周期为T,有四个输入源(req),下面这个表格Req[3:0]列表示实际的request,为1表示产生了request;RR Priority这一列为当前的优先级,为0表示优先级最高,为3表示优先级最低;RR Grant这一列表示根据当前Round Robin的优先级和request给出的许可;Fixed Grant表示如果是固定优先级,即按照3210,给出grant的值。
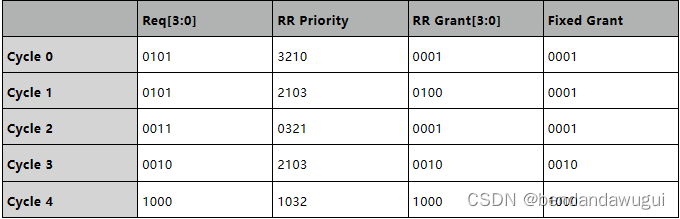
第一个周期,初始状态,我们假设req[0]的优先级最高,req[1]其次,req[3]最低,当req[2]和req[1]同时为1的时候,根据优先级,req[0]优先级高于req[2],grant=0001;
第二个周期,因为req[2]在前面一个周期并没有获得grant,那么它继续为1,而这个时候req[0]又来了一个新的request,这个时候就能看出round robin和fixed priority的差别了,对于fixed priority,grant依然给0,即0001,但是round robin算法的要求是:因为上一个周期req[0]已经被grant了,那么它的优先级变为最低的3,相应的req[1]的优先级变为最高,因为它本来就是第二高的优先级,那么当req[0]优先级变为最低了之后它自然递补到最高,那么这个时候产生的许可frant就不能给到req[0],而是要给到req[2]。
同理,第三个周期,req[2]因为在前一个周期grant过,它的优先级变为3最低,req[3]的优先级变为最高,后面的周期大家可以自己顺着分析下来。
换句话说,因为被grant的那一路优先级在下一个周期变为最低,这样让其他路request都会依次被grant到,而不会出现其中一路在其他路有request的情况下连续被grant的情况,所以round robin在中文中也被翻译3为“轮询调度”。
好,下面我们来讲round robin的RTL实现。
下面这种设计思路应用范围较广,核心是多个req的优先级不变,从多个request入手,当某一路req已经被grant之后,下一周期再req时我们会人为的把上一拍进入fixed priority arbiter的这一路req给屏蔽掉,这样相当于只允许之前没有被grant的那些路去参与仲裁,grant一路之后就屏蔽一路,等到剩余的request都依次处理完了再把屏蔽放开,重新来过,这就是利用屏蔽mask的办法来实现round robin的思路。
这个思路还是会用到前面一讲里面的Fixed priority arbiter的写法,如何来产生屏蔽信号mask呢,回看下面这一段RTL:
module prior_arb #(
parameter REQ_WIDTH = 16
)(
input [REQ_WIDTH-1:0] req,
output [REQ_WIDTH-1:0] gnt
);
logic [REQ_WIDTH-1:0] pre_req;
assign pre_req[0] = 1'b0;
assign pre_req[REQ_WIDTH-1:1] = req[REQ_WIDTH-2:0] | pre_req[REQ_WIDTH-2:0];
assign gnt = req & ~pre_req;
endmodule这段代码其实本质和前面一篇中利用for 循环实现fixed priority仲裁实现的功能一样,pre_req的意义是:如果req的第i位为1,那么pre_req从i+1位开始每一位都是1,而第0位到第i位都是0;这个pre_req其实就是我们要找的mask!为啥它能作为mask?我们只需要把当前的req和上一拍的pre_req AND起来,得到的结果就是新的req,这个req就是被mask之后的req,这个req里之前被grant的位被mask掉了,被允许通过的是之前优先级更低的那些位,如果那些位上之前有request但是没有被grant,现在就可以轮到他们了。
每次新的grant之后mask里0的位数会变多,从而mask掉更多的位,直到所有的低优先级的req都被grant了一次之后,req AND mask的结果变为全0了(即新的req全变为0了),这个时候就说明我们已经轮询完毕,要重新来过了。
硬件实现上我们需要两个并行的Fixed Priority Aribter,他们一个的输入是request AND mask之后的masked request,另一个就是原本的request,然后我们在他们两个arbiter的output中选择一个grant,如下图所示:
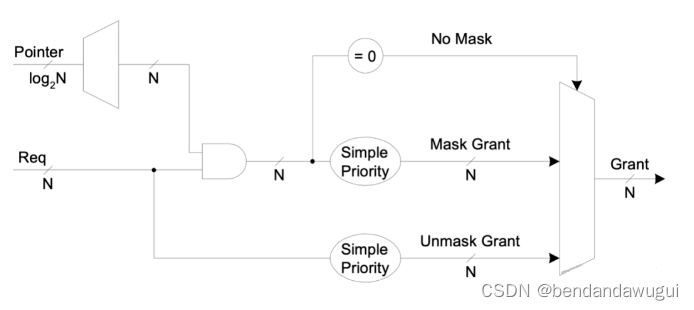
当masked_request 不是全0,即存在没有被mask掉的request时,我们选择上面的这一路Mask Grant,否则我们选择下面这一路Unmasked Grant。
而又因为对于上面的这一路来说,当masked request为全0的时候,Mask Grant也是全0,这个时候可以把Mask Grant和Unmask Grant直接按位OR起来就行,所以其实图上最后显示的Mux可以用下面简单的AND门和OR门实现。
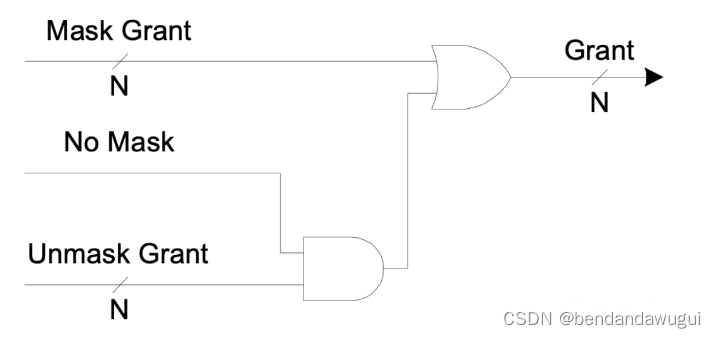
下面是这个设计的代码,依然是参数化的表达,可以满足任意数目的request:
module round_robin_arbiter #(
parameter N = 16
)(
input clk,
input rst,
input [N-1:0] req,
output[N-1:0] grant
);
logic [N-1:0] req_masked;
logic [N-1:0] mask_higher_pri_reqs;
logic [N-1:0] grant_masked;
logic [N-1:0] unmask_higher_pri_reqs;
logic [N-1:0] grant_unmasked;
logic no_req_masked;
logic [N-1:0] pointer_reg;
// Simple priority arbitration for masked portion
assign req_masked = req & pointer_reg;
assign mask_higher_pri_reqs[N-1:1] = mask_higher_pri_reqs[N-2: 0] | req_masked[N-2:0];
assign mask_higher_pri_reqs[0] = 1'b0;
assign grant_masked[N-1:0] = req_masked[N-1:0] & ~mask_higher_pri_reqs[N-1:0];
// Simple priority arbitration for unmasked portion
assign unmask_higher_pri_reqs[N-1:1] = unmask_higher_pri_reqs[N-2:0] | req[N-2:0];
assign unmask_higher_pri_reqs[0] = 1'b0;
assign grant_unmasked[N-1:0] = req[N-1:0] & ~unmask_higher_pri_reqs[N-1:0];
// Use grant_masked if there is any there, otherwise use grant_unmasked.
assign no_req_masked = ~(|req_masked);
assign grant = ({N{no_req_masked}} & grant_unmasked) | grant_masked;
// Pointer update
always @ (posedge clk) begin
if (rst)
pointer_reg <= {N{1'b1}};
end else begin
if (|req_masked) // Which arbiter was used?
pointer_reg <= mask_higher_pri_reqs;
else begin
if (|req) // Only update if there's a req
pointer_reg <= unmask_higher_pri_reqs;
else
pointer_reg <= pointer_reg;
end
end
end
endmodule这里稍微多讲几句,当no_req_masked之后,pointer_reg并不是要更新到1111或者是1110,而是要根据这个时候的request来,比如说这个时候request是0010,那么新的mask就要调整为1100,重新把bit[0],bit[1]都mask掉。
关于round-robin还有其他的思路,比如将request进行rotate,从而达到改换优先级的目的,然后再根据history来rotate 回来。还有比如并行放N个fixed priority arbiter,把所有的priority order都实现了,然后再在N个grant中选择一个,这些设计在面积和时序上都各有牺牲,而且参数化设计不是很容易写,这里就不细讲了。感兴趣的同学可以点击原文链接,看一篇论文里的详细讲解,上述设计也来自于这篇论文:Arbiters_Design Ideas and Coding Styles.fm (psu.edu),里面还有不同设计的面积时序比较。

















 4403
4403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









