







原创文章请勿随意转载,如有需要,请于作者联系。
前几天写了一个卷积神经网络(CNN)中,卷积和加法融合的文章。有同学问,希望写一个带代码版本的,方便更好的理解。
我的第一反应是,代码版本的咋写,有那么多细节。后来一想,其实那位同学想知道的并不是那些细节,而是一个大致的流程。
那我就简单写一个伪代码版的吧,把大致的代码思路写一下。
至于具体卷积算法怎么实现的,建议chatGPT一下,或者看下开源深度学习仓库就行。
如果没看之前的文章,可以看上一看:超简单的卷积和加法融合
还是以 resnet50 中的图为例,做一个卷积和加法的融合。
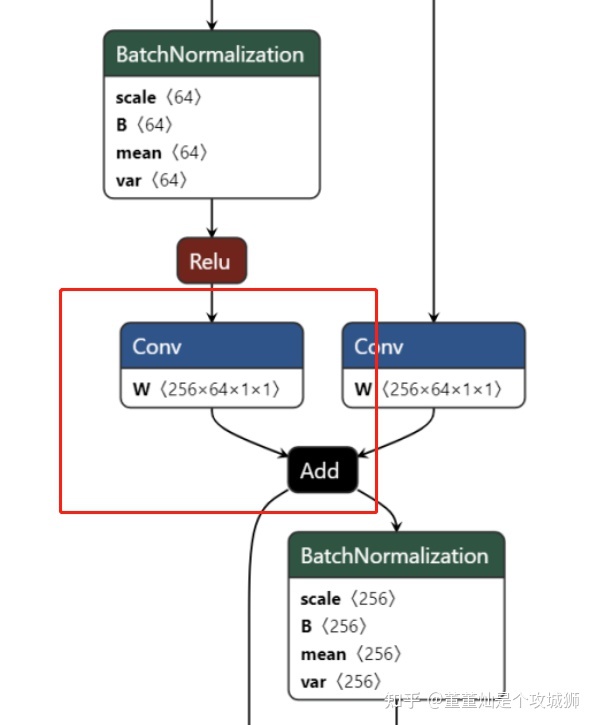
正常情况下,上述网络片段在执行的时候大概是这样的:
BatchNorm -> Relu -> Conv -| Add的左分支
| -> Add
-> Conv -| Add的右分支写出伪代码,实际上就是一种顺序调用逻辑,比如
bn_out = Batch_normal();
relu_out = Relu(bn_out);
conv_out_left = Conv2d(relu_out)
conv_out_right = Conv2d(...)
add_out = Add(conv_out_left, conv_out_right)而一旦融合完之后,上图红框中的Conv 和 Add 就变成了一个算子,这里暂且称这个融合之后的算子为 ConvAdd 算子。
于是,上述的图,就变成了如下的图:
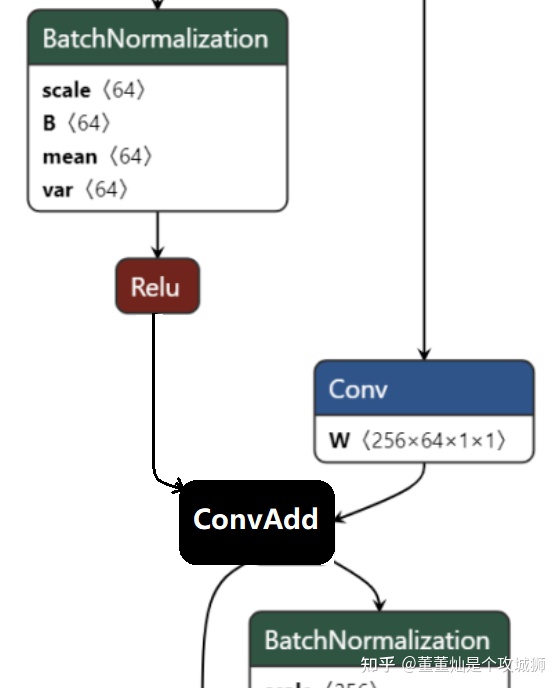
此时,整个网络片段的调用逻辑变成了:
bn_out = Batch_normal();
relu_out = Relu(bn_out);
conv_out_right = Conv2d(...)
add_out = ConvAdd(relu_out, conv_out_right)再把 ConvAdd 当做一个算子之后,便可以进行很多融合、拆图、流水并行操作。
假设现在这个网络运行在一个Asic芯片上,芯片上卷积计算模块和加法计算模块是互相独立的,没有任何依赖。
这里假设卷积输入的 Feature Map 的大小是 [n, hi, wi, ci],卷积核是[co, kh, kw, ci]。
其余参数简化一下,将卷积 pad 简化为0,stride 简化为1,dilation简化为1。
卷积的输出为[n, ho, wo, co]。
那么卷积后面的加法,执行的两个tensor相加,也就变成了 [n, ho, wo, co] + [n, ho, wo, co] = [n, ho, wo, co]。
那么,我们将卷积的输入(假设是下面的一张图),在H方向切成两份。

那么计算完一整张图,需要调用两次卷积运算,第一次计算上半部分,第二次计算下半部分。
两次计算中,大部分像素之间是没有关系的,仅仅在两部分交界的地方会有可能存在依赖。(存在依赖的条件为 kernel 大于1,或者 stride 大于1,这些情况先不考虑,暂时认为两部分像素没有关系)。
那么第一次卷积计算,计算的输入是 [n, hi/2, wi, ci],计算输出结果是 [n, ho/2, wo, co]。此时计算的是前半部分的 hi。用加黑表示。
那么第二次卷积计算,计算的输入是 [n, hi/2, wi, ci],计算输出结果是 [n, ho/2, wo, co]。此时计算的是后半部分的 hi。用斜体表示。
同理,加法也会被分成两次计算,分别对应计算卷积的两次输出:
第一次加法,计算的是第一次卷积的输出,即 [n, ho/2, wo, co]。
第二次加法,计算的是第二次卷积的输出,即 [n, ho/2, wo, co]。
那么,在两次计算的情况下,ConvAdd 这一个算子中,内部的实现逻辑大致应该是:
conv_out_part1 = Conv2d(part1)
conv_out_part2 = Conv2d(part2)
add_out_part1 = Add(conv_out_part1)
add_out_part2 = Add(conv_out_part2)但是这样显然是不行的,因为这样写还是串行执行:执行完第一次卷积执行第二次卷积,执行完第二次卷积执行第一次加法...那怎么让 Conv 和 Add 并行起来呢?
通过观察可以发现,第一次的Add并不依赖第二次的Conv,并且我们已经假设了Asic芯片上Conv运算模块和Add模块完全独立。
那么让第二次Conv和第一次Add并行起来的方法就是:第一次Conv计算完之后,直接计算第一次Add,然后同时并行第二次Conv,这个时候,代码的实现大致是这样:
conv1 = Conv2d(part1)
-----------------------
add1 = Add(conv1)
conv2 = Conv2d(part2)
-----------------------
add2 = Add(conv2)这个时候,Add 和 conv 在中间的一个流水级中并行起来了。
所谓的一个流水级,指的是上面代码段中两个“ ------ ” 之间的代码,称之为在一个流水级中。
那如果将图片拆成更多份,那可以并行的流水级就会更多。
比如拆成4份,那可以有3个流水级中的Conv和Add并行起来。
conv1 = Conv2d(part1)
-----------------------
add1 = Add(conv1)
conv2 = Conv2d(part2)
-----------------------
add2 = Add(conv2)
conv3 = Conv2d(part3)
-----------------------
add3 = Add(conv3)
conv4 = Conv2d(part4)
-----------------------
add4 = Add(conv4)
-----------------------需要说明一点的是,上面伪代码中,每一个 “-----” 其实都代表了一个同步点。在实际部署到硬件上运行时,需要在这些同步点上设置同步操作,用来使上一个流水级中的所有计算操作全部完成即可。
常用的同步操作有一些同步指令或者barrier指令。假设我们使用barrier指令来进行同步,那么上述完整的伪代码便是:
conv1 = Conv2d(part1)
barrier()
add1 = Add(conv1)
conv2 = Conv2d(part2)
barrier()
add2 = Add(conv2)
conv3 = Conv2d(part3)
barrier()
add3 = Add(conv3)
conv4 = Conv2d(part4)
barrier()
add4 = Add(conv4)
barrier()当然上述代码看起来太长了,可以写成循环的形式,还是以将H方向拆分 4 份为例:
conv1 = Conv2d(part1);
barrier();
for i in range(1, 4):
add_i = Add(convi)
Conv_i+1 = Conv2d(part_i+1)
barrier()
add4 = Add(conv4)
barrier()伪代码的逻辑还是很简单的,关键是需要理解Conv和Add并行流水的思想。
这种方法可以用到的融合场景很多,并不仅仅局限于Conv和Add这两个算子,也不局限于某一个神经网络。
只要是在硬件上计算单元可以并行执行,并且在神经网络结构图上前后有依赖的层,几乎都可以这么进行融合来提升整体性能。
v v v v v v
本文为作者原创,请勿转载,转载请联系作者。
点击下方卡片,关注我的公众号,有最新的文章和项目动态。
v v v v v v
















 552
552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











