






参考链接:
Transformer 修炼之道(一)、Input Embedding
1、Input embedding
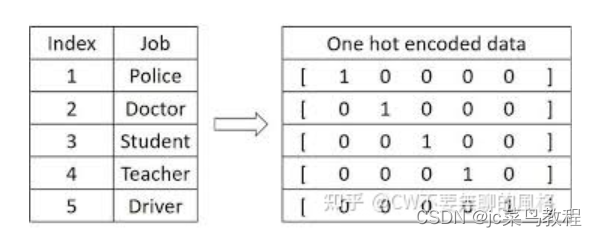
Ⅰ. One-hot Encoding
在 CV 中,我们通常将输入图片转换为4维(batch, channel, height, weight)张量来表示;而在 NLP 中,可以将输入单词用 One-Hot 形式编码成序列向量。
向量长度是预定义的词汇表中拥有的单词量,向量在这一维中的值只有一个位置是1,其余都是0,1对应的位置就是词汇表中表示这个单词的地方。
eg:词的对应位置为1,其余为0
代码实现:
def one_hot(token_start,length):
# 创建张量|需要编码几个词,词汇表中的单词量
one_hot_encode =torch.zeros(token_start.shape[0],length).int()
for i in range(token_start[0]):
# 词所在词汇表中对应位置为1
one_hot_encode[i,token_start[i].item()] = 1
return one_hot_encode
优点:简洁
缺点:1、稀疏且长,易造成浪费;2、没有体现词与词之间的关系
Ⅱ.Word Embedding
出发点:需要另一种词的表示方法,能够体现词与词之间的关系,使得意思相近的词有相近的表示结果,这种方法即 Word Embedding。
设计方法:设计一个可学习的权重矩阵 W。

可以将这种方式看作是一个 lookup table:对于每个 word,进行 word embedding 就相当于一个lookup操作,在表中查出一个对应结果。
在pytorch框架下,可使用torch.nn.Embedding来实现 word embedding:
class Embeddings(nn.Module):
def __init__(self,d_model,vocab):
super(Embeddings,self).__init__()
self.1ut = nn.Embedding(vocab,d_model)
self.d_model = d_model
def forward(self,x):
return self.1ut(x) * math.sqrt(self.d_model)
其中,vocab 代表词汇表中的单词量,one-hot 编码后词向量的长度就是这个值;d_model代表权重矩阵的列数,通常为512,就是要将词向量的维度从 vocab 编码到 d_model。
优点:获得了词与词之间关系的表达形式
缺点:词在句子中的位置关系还无法体现。
Ⅲ. Position Embedding
由于 Transformer 是并行地处理句子中的所有词,因此需要加入词在句子中的位置信息,结合了这种方式的词嵌入就是 Position Embedding 了。
实现的两种方式:
1、通过网络学习
2、预定义一个函数,通过函数计算位置信息
Transformer 的作者对以上两种方式都做了探究,发现最终效果相当,于是采用了第2种方式,从而减少模型参数量,同时还能适应即使在训练集中没有出现过的句子长度。
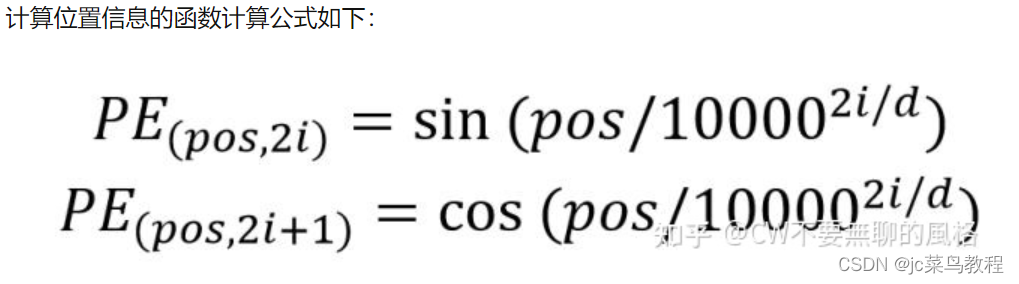
pos:代表词在句子中的位置
d:词向量的维度(经过word embedding后是512)
2i 代表的是 d 中的偶数维度,(2i + 1) 则代表的是奇数维度,这种计算方式使得每一维都对应一个正弦曲线。
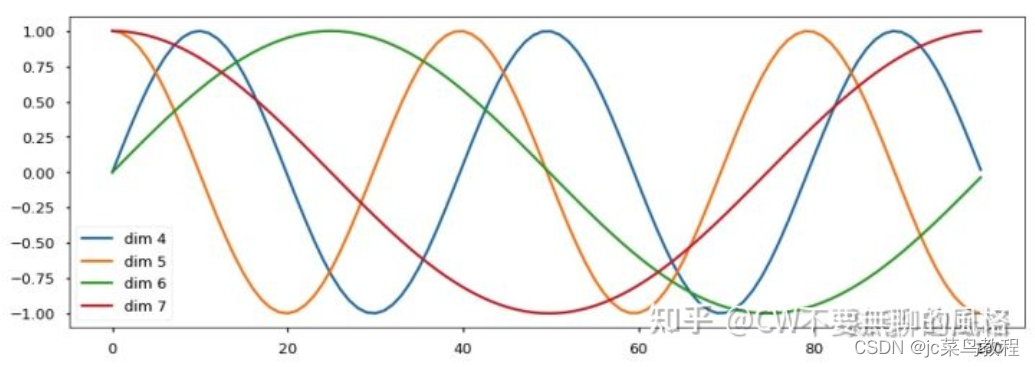
原因:
这种编码方式保证了不同位置在所有维度上不会被编码到完全一样的值,从而使每个位置都获得独一无二的编码。
Pytorch代码实现:
import math
import torch
from torch import nn
class PositionalEncoding(nn.Module):
def __init__(self,d_model,dropout,max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# max_len代表句子中最多有几个词
pe = torch.zeros(max_len,d_model)
position = torch.arange(0,max_len).unsqueeze(1)
# d_model即公式中的d
div_term = torch.exp(torch.arange(0,d_model,2) * -(math.log(1000.0) / d_model))
# 偶数项,0,2,4,6
pe[:,0::2] = torch.sin(position * div_term)
# 奇数项,1,3,5,7
pe[:,1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe',pe)
def forward(self,x):
# 原向量加上计算出的位置信息才是最终的embedding
x = x + self.pe[:,:x.size(1)]
return self.dropout(x)
注意:
实现过程中需要注意的一个细节是 —— self.register_buffer(‘pe’, pe) 这句,它的作用是将pe 变量注册到模型的 buffers() 属性中,这代表该变量对应的是一个“持久态”,不会有梯度传播给它,但是能被模型的 state_dict 记录下来。
!!注意,没有保存到模型的 buffers() 或 parameters() 属性中的参数是不会被记录到state_dict 中的,在 buffers() 中的参数默认不会有梯度,parameters() 中的则相反。
通过代码可以看到,position encoding 是直接加在输入 x 上的,那么**为何是相加而非拼接(concat)**呢?拼接不是更能独立体现出位置信息吗?而相加的话都把位置信息混入到原输入中了,貌似“摸不着也看不清”…
这是因为 Transformer 通常会对原始输入做一个嵌入(embedding),从而映射到需要的维度,可采用一个变换矩阵做矩阵乘积的方式来实现,上述代码中的输入 x 其实就是已经变换后的表示,而非原输入。
在原输入上 concat 一个代表位置信息的向量在经过线性变换后 等同于 将原输入经线性变换后直接加上位置编码信息。
2、注意力机制 attention mechanism
在机器学习模型中嵌入的一种特殊结构,用来自动学习和计算输入数据对输出数据的贡献大小。
Attention 机制听起来高大上,其关键就是学出一个权重分布,然后作用在特征上。
- 这个权重可以保留所有的分量,叫加权(Soft Attention),也可以按某种采样策略选取部分分量(Hard Attention)。
- 这个权重可以作用在原图上,如目标物体检测;也可以作用在特征图上,如 Image-Caption
- 这个权重可以作用在空间尺度上,也可以作用于 Channel 尺度上,给不同通道的特征加权
- 这个权重可以作用在不同时刻上,如机器翻译
参考链接:https://zhuanlan.zhihu.com/p/105335191 - 【基本思想】
尝试让模型自己学习如何分配自己的注意力,即为输入信号加权。他们用注意力机制的直接目的,就是为输入的各个维度打分,然后按照得分对特征加权,以突出重要特征对下游模型或模块的影响
比较规范的文章里,一般会采用”key-quer y-value”理论来描述注意力机制的机理。
注意力机制的设计
注意力机制本质上就是嵌入到原有模型的一个小模型,具体结构是可以灵活设计的。














 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









