






模型预训练步骤:(预训练模型有神经网络的记忆功能,后续可以通过loss分辨clean和noisy数据)
初始化dataset,dataloader,A/B模型
对模型进行warmup:打乱后的train数据经过一次模型,计算ContrastiveLoss,训练一轮网络(cost_s_mean.sum() + cost_im_mean.sum())
validate:所有val数据经过一次网络A/B,计算平均相似度sims_mean
通过相似度计算输出caption retrieval和image retrieval的召回情况(即匹配情况,pair的相似度是否在前n)
模型训练步骤,一共40epoch:
调整A/B模型学习率
eval_train:Compute per-sample loss and prob
分批给所有noisy_trainloader数据计算per-sample loss(cost_s_mean + cost_im_mean)
从model_A/B.train输出loss,不训练网络
将loss变为0~1之间,变大小为(num,1)
进行fit 2 components GMM
使用EM算法+loss数据估算模型参数
预测loss数据的每个组件的后验概率(包含两个高斯分布)
选两个高斯分布中均值小的作为后验概率prob_A
split_prob:返回pred_A(w) = prob_A>p_threshold, p_threshold可变
pred_A(T/F)和prob_A(0~1)大小(data_set, )
B同样
分别训练A/B模型,以A为例:
根据pred构造labeled_trainloader, unlabeled_trainloader
用train的数据和B网络预测出来的pred和prob,来训练A网络(会用到B网络进行求p)
train
以labeled_trainloader的一批数据为一轮,每轮
拿一批labeled数据和一批unlabled数据
给以上数据预测新的y label refinement
对于labeled数据
通过net_A.predict预测p(以前10%大的p为margin)
通过yci-hat = wi*yci + (1-wi)Pk(Ici,Tci)公式算新y(targets_l)
对于unlabeled数据
通过net_A.predict和net_B.predict预测p
通过yni-hat =(PA(Ini,Tni)+PB(Ini,Tni))/2公式算新y(targets_u)
train
对于labeled数据:用targets_l作为y,用soft_margin计算loss
label(y)越大,margin越大,分布为指数
理解:对判断为正例的要求更严格,被判断为负例的要求不严格
当epoch过半时,对unlabele数据进行train
Validattion:
分别用A/B模型:
对所有val_loader的img,cap进行emb(还有cap_len)
img_emb和cap_emb求sim
计算两个模型的sim_mean,求平均值
按sim大小计算召回率
保存总召回最大的A/B模型
A/B模型是什么:
A/B模型包含了三个网络img_encoder, caption_encoder, similarity_encoder和一个loss函数ContrastiveLoss
img_encoder输入(batch_size,36,2048)的pre_computed的image,输出(batch_size,36,1024)的img_emb
caption_encoder输入(batch_size,?)的文字版原caption,经过voc编码后,输出(batch_size,max_L,1024)的cap_emb,其中max_L是最长的caption长度
similarity_encoder输入以上经过编码的img和caption,输出(batch_size,batch_size)的相似度矩阵
A/B模型区别:
A/B模型的区别是学习率等参数不一样
A/B模型作用:输入image和caption,输出相似度矩阵sim,用ContrastiveLoss进行训练
ContrastiveLoss:
输入:相似度矩阵sim,是否进行模型训练,是否使用soft_margin(是的话还需要输入预测的label,即y)
输出分情况讨论:
在warmup时,margin(α)取定值0.2,需要进行模型训练(模型反向传播,参数会更新),loss为per_sample loss,loss计算方法为
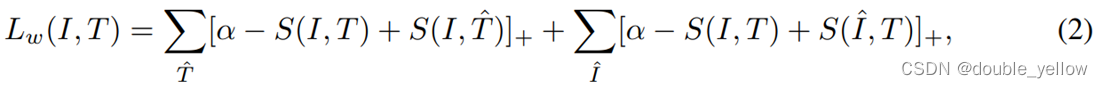
对于左边式子进行解读,其中α为margin取定值0.2,S(I,T)为该对img-caption pair的相似度,S(I,T_hat)为该img与其他不匹配的caption的相似度,求和下标是所有与img不匹配的caption,所以含义是,(0.2的margin+img与不匹配的caption的相似度-img与匹配caption的相似度)以遍历所有不匹配的caption为求和条件。右边式子同理。
per_sample loss作用:使原数据对img-caption的相似度与所有和img或caption相关但不匹配的数据对的相似度拉开差距尽可能到margin(0.2)以上
在fit GMM时,
输出和以上原理一样的loss,margin(α)取定值0.2,不需要进行模型训练(只要拿到loss就行)。输出的loss进行标准化后用来fit GMM模型,并且估计loss数据对应的后验概率,作为对应数据的prob
在最后train中用label/unlabel数据进行模型训练时
输出:有最大相似度的负例的soft loss的和
soft loss中margin随预测的标签改变

式中原固定margin(α)取0.2,现soft margin的值在0~0.2之间,随预测标签y_hat的增长而指数增长。

式中左边括号不匹配对取相似度最大的原img与非原配caption的数据对。
soft margin搭配loss的好处是:label(y)越大,margin越大,分布为指数,对判断为正对的要求更严格,相似度与负对拉得更开,而对被判断为负对的要求不严格。















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









