









原文链接:https://dreamhomes.github.io/posts/202101181459.html
TL;DR
目前图表示学习方法主要是学习图中节点或者子图的隐含向量,但现实中很多任务例如图分类或者聚类都需要将整个图编码成固定长度的向量;此外,以前基于图核的方法由于使用自定义特征因此通用性较差。本文中提出的一种无监督学习的图编码框架 graph2vec 可以编码任意大小的图,可以应用在downstream 的图分类或者聚类任务中;
Problem Statement
给定图集合 G = { G 1 , G 2 , ⋯ } \mathbf{G} = \{G_1, G_2, \cdots \} G={G1,G2,⋯} 和向量编码维度 δ \delta δ,目标是学习到每个图 G i G_i Gi 的 δ \delta δ 维表示向量;
给定一个图 G = ( N , E , λ ) G=(N, E, \lambda) G=(N,E,λ) 和子图 s g = ( N s g , E s g , λ s g ) sg = (N_{sg}, E_{sg}, \lambda_{sg}) sg=(Nsg,Esg,λsg),其中 λ \lambda λ 表示 λ : N → ℓ \lambda : N \rightarrow \ell λ:N→ℓ 节点对应的标签, s g sg sg是 G G G 的子图如果存在单射函数 μ : N s g → N \mu : N_{sg} \rightarrow N μ:Nsg→N ,满足 ( n 1 , n 2 ) ∈ E s g (n_1, n_2) \in E_{sg} (n1,n2)∈Esg 如果 ( μ ( n 1 ) , μ ( n 2 ) ) ∈ E (\mu(n_1), \mu(n_2)) \in E (μ(n1),μ(n2))∈E。论文中用到的是 rooted subgraph : 节点 n n n 且深度为 d d d 的子图为节点 n n n d-hop 之内所有的节点和边。
Model / Algorithm
文章的主要思路是受 doc2vec 启发的,因此首先简单介绍下 doc2vec 的思路,再介绍 graph2vec;
doc2vec
给定文档
D
=
{
d
1
,
d
2
,
.
.
.
,
d
N
}
D=\{d_1, d_2, ..., d_N\}
D={d1,d2,...,dN} 及其对应文档
d
i
∈
D
d_i \in D
di∈D 采样的单词
c
(
d
i
)
=
{
w
1
,
w
2
,
.
.
.
,
w
l
i
}
c(d_i) = \{w_1, w_2, ..., w_{li}\}
c(di)={w1,w2,...,wli},doc2vec 优化的目标似然函数为
∑
j
=
1
l
i
log
Pr
(
w
j
∣
d
i
)
\sum_{j=1}^{l_{i}} \log \operatorname{Pr}\left(w_{j} \mid d_{i}\right)
j=1∑lilogPr(wj∣di)
其中
Pr
(
w
j
∣
d
i
)
\operatorname{Pr}\left(w_{j} \mid d_{i}\right)
Pr(wj∣di) 定义为
exp
(
d
⃗
⋅
w
⃗
j
)
∑
w
∈
V
exp
(
d
⃗
⋅
w
⃗
)
\frac{\exp \left(\vec{d} \cdot \vec{w}_{j}\right)}{\sum_{w \in \mathcal{V}} \exp (\vec{d} \cdot \vec{w})}
∑w∈Vexp(d⋅w)exp(d⋅wj)
然后训练过程中使用了负采样方法优化。
graph2vec
按照 doc2vec 的思路用到图结构上,论文中提出的模型采样思路为:
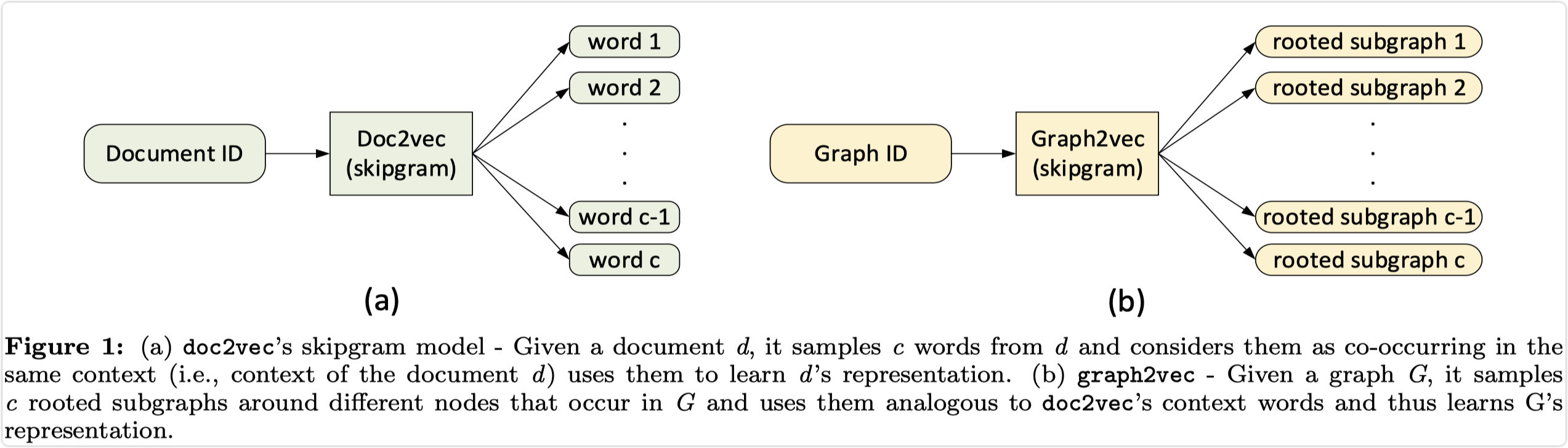
以 graph 代替 document,以 rooted subgraph 代替 work,整体的算法流程如下:

算法主要包括两部分:生成 rooted subgraphs,图编码训练过程;下面简单说明下 rooted graph 生成过程。
Extracting Rooted Subgraphs
生成 rooted subgraph 的主要过程为 WL relabeliing process,详情可参考文章 Weisfeiler-lehman graph kernels,主要思路是把当前节点
n
n
n 及其
d
−
h
o
p
d-hop
d−hop 映射到一个子图节点集合中国;下面👇 直接看看论文中的生成 subgraph 算法流程:

负采样和优化
由于训练过程中整个子图词汇表规模较大,因此论文中采用负采样的方法提高效率,即在训练图 G 1 G_1 G1 时,选择不属于 G i G_i Gi 子图集的 k k k 个子图样本 c ′ ⊂ S G vocab , k < < ∣ S G vocab ∣ , c ∩ c ′ = { } c^{\prime} \subset S G_{\text {vocab }}, k<<\left|S G_{\text {vocab }}\right| \text { , } c \cap c^{\prime}=\{\} c′⊂SGvocab ,k<<∣SGvocab ∣ , c∩c′={} 。
最后使用 SGD 优化器来训练模型参数。
Experiments
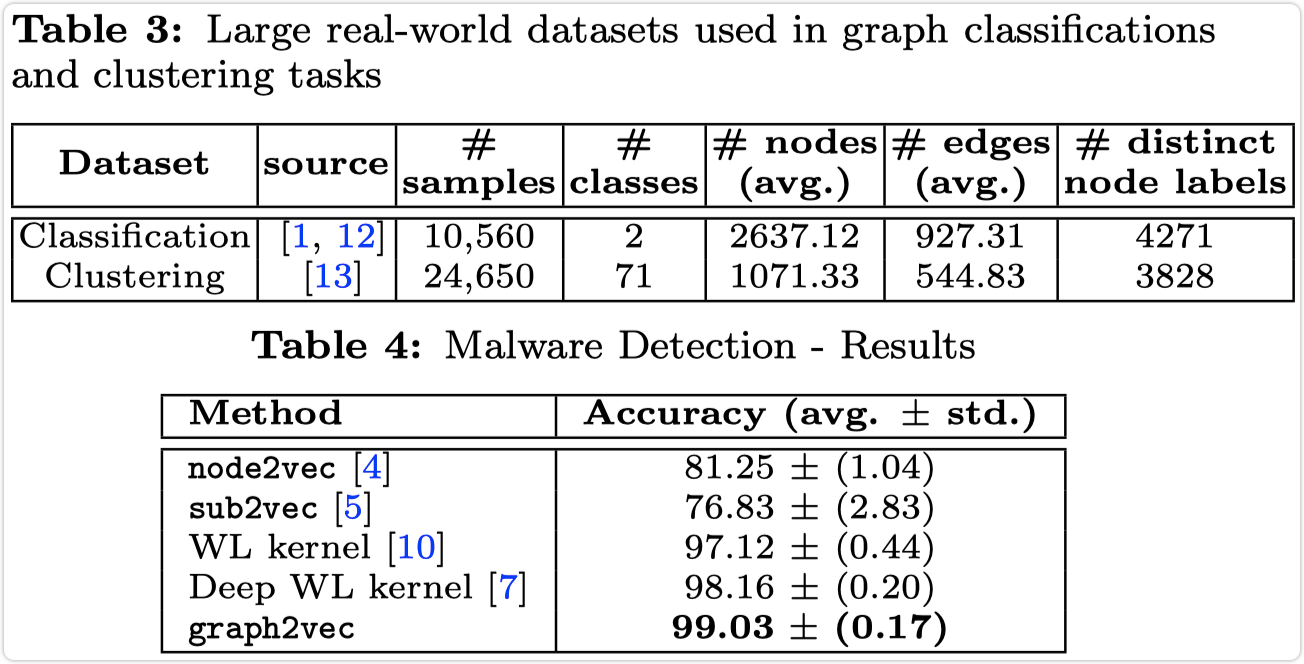
对于图分类和聚类任务算法的实验结果如下所示;

联系作者
















 1433
1433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









