







论文地址:https://arxiv.org/pdf/1902.09104.pdf
作者来自中科大和南洋理工,研究方向是语义边缘检测任务。
参考博客:百度安全验证
动态特征融合语义边缘检测论文Dynamic Feature Fusion for Semantic Edge Detection解读_import_torch_as_tf-CSDN博客
摘要
如果多尺度特征融合良好,可以大大提高语义边缘检测的效率。
现有研究的不足:然而,目前流行的语义边缘检测方法采用固定权值的融合策略,强制图像中不同的语义共享相同的权值,使得所有图像和位置的通用权值不考虑其不同的语义或局部上下文。
在这项工作中,我们提出了一种新的动态特征融合策略,该策略自适应地为不同的输入图像和位置分配不同的融合权重,这是通过一个权值学习器根据特定的输入条件,为特征图的每个位置在多个层次的特征上提供适当的融合权重来实现的。这样,可以更好地考虑特征图和输入图像在不同位置所产生的差异,从而有助于产生更精确和更尖锐的边缘预测。通过在Cityscapes和SBD上的综合实验,我们证明了我们的新的动态特征融合模型优于固定权重融合模型和直接定位不变权重融合方法。
引言
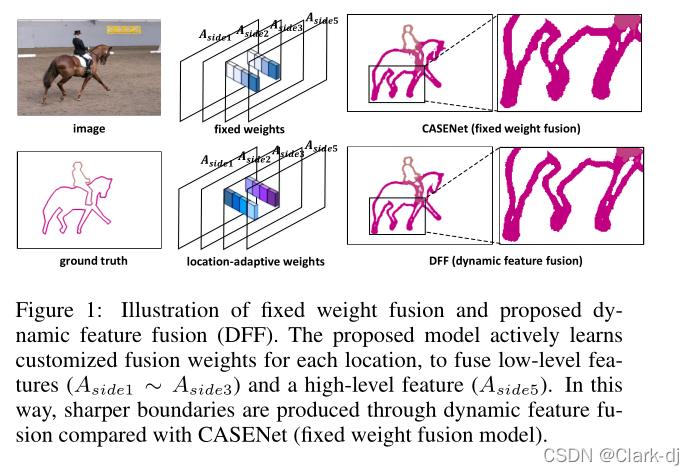
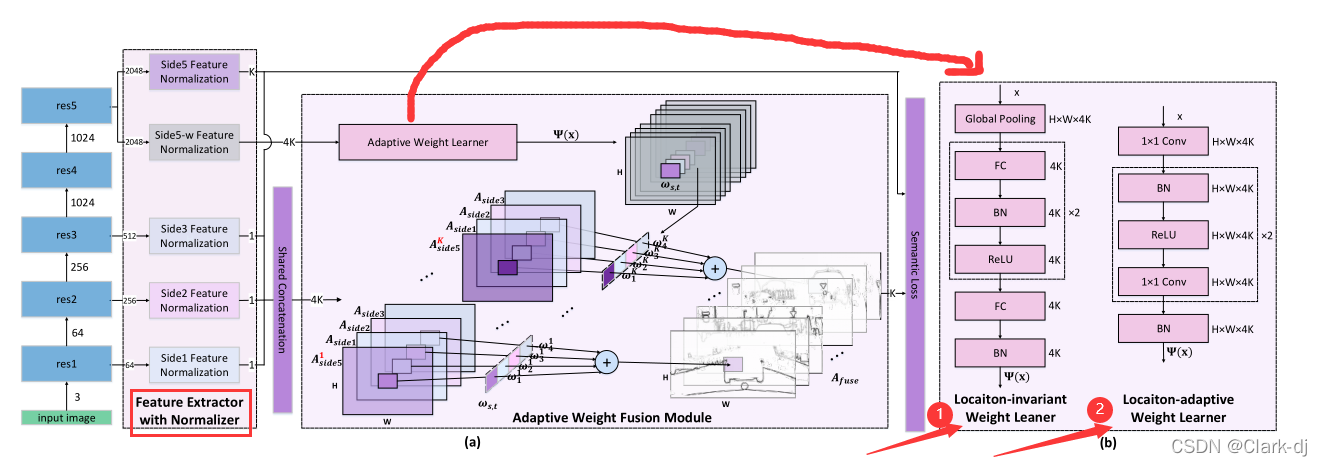
(这里直接从本文工作开始解读,具体分析看原文)在本文中,我们提出了一种动态特征融合(Dynamic Feature Fusion, DFF)方法,该方法将自适应融合权值分别分配到每个位置,旨在生成一个自适应于每个图像特定内容的融合边缘映射,如图1的底行所示。
图1:固定权值融合和提出的动态特征融合(DFF)的示意图。
该模型主动学习每个位置的自定义融合权值,以融合低级特征(Aside1 ~ Aside3)和高级特征(Aside5)(CASENet )。
这样,与固定权值融合模型CASENet (fixed weight fusion model)相比,动态特征融合产生更清晰的边界。设计了一种新型的位置自适应权重学习器,该学习器根据多层级响应图的特征图内容,主动学习自定义的特定于位置的融合权重。
如图1所示,将低级特征(Asidel ~ Aside3)和高级特征(Aside5)合并,生成最终的融合输出。
- 低层次的特征映射对细节(如物体内部的边缘)有很高的响应,而高层次的特征映射则比较粗糙,只在物体层次的边界上有很强的响应(低层细节,高层粗糙)。
- 这location-adaptive权重学习器为每个单独位置生成融合权重。
例如,对于马的边界,融合权值偏向于低级特征,以充分利用精确定位的边缘。
对于马的内部,较高的权重被分配到高层次的特征,以抑制物体内部零碎和琐碎的边缘反应。
主要贡献是:
- 本文首次揭示了目前流行的固定权值融合方法的局限性,并解释了其不能产生令人满意的融合结果的原因。
- 提出了一种动态特征融合(DFF)模型。我们是第一个提出以输入内容为条件来学习自适应融合权值来融合多级特征的。(在语义边缘检测研究领域中首次学习自适应融合权重将输入的内容有条件的融合到多层次特征中;)
相关工作
详细见原文的相关工作。
CASENet、SEAL等
将多尺度的激活量缩放到一个相似的量级将有利于后续的预测或融合。例如,SSD [Liuet al., 2016]在进行多尺度预测之前,会对低级特征图进行L2归一化处理。[Liet al., 2018]增加了一个缩放层,用于学习融合尺度,将通道注意和空间注意输出结合起来。在本文中,我们采用了一个特征提取器,并对所有多级激活进行了归一化处理。
我们提出的方法也与动态滤波网络有关[Jiaet al., 2016],在动态滤波网络中,根据输入生成特定于样本的滤波参数。具有特定内核大小的过滤器是动态生成的,以使输入特征图上的局部空间转换成为动态卷积核。相比之下,我们的方法是将自适应融合权值应用于多级响应图以获得期望的融合输出,并提出一个带有归一化器的特征提取器来缓解训练过程中的偏差。
CASENet https://blog.csdn.net/dujuancao11/article/details/122918643
- CASENet采用ResNet-101进行少量修改,提取多级特征。
- 在主干的基础上,1×1convolution层和随后的上采样层连接到剩余块的前三个堆栈和最上层堆栈的输出,产生三个单通道特征映射{Aside1, Aside2, Aside3}和k -channel类激活mapAside5={A1side5,…,AKside5}。这里是类别的数量。
- 共享连接复制底部特性{Aside1, Aside2, Aside3}K次,分别连接aside5中的每个k top激活:
- 得到的串联激活映射Acat 然后输入到k -grounped 1×1 conv层,用kchannels生成融合的激活映射:
CASENet对特征图中所有位置上的所有图像施加了ith类别相同的一组固定的融合权值(wi1, wi2, wi3, wi4)。
通过复制CASENet,我们进行了以下观察。
- 每个类的权重1总是显著超过其他权重(wi2, wi3, wi4)。
- 通过评估Aside5和融合输出的性能,我们发现它们提供了几乎相同的性能。
这意味着底层特征响应{Aside1, Aside2, Aside3}对最终融合输出的贡献很小,尽管它们包含了细粒度的边缘位置和结构信息。
最终的决定主要由高级特性决定。
因此,CASENet不能充分利用底层信息,只产生粗糙边缘。
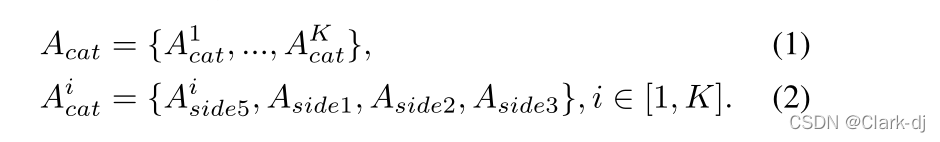
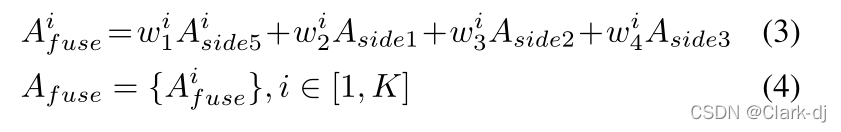
提出的方法
针对现有的语义边缘检测(SED)模型在融合固定权值特征时存在的上述局限性,我们提出了一种新的基于动态特征融合的SED模型。
本文提出的模型通过两个模块对多级特征进行融合:
1)带归一化器的特征提取器对多级特征的幅度尺度进行归一化;
2)自适应权重融合模块对多级特征映射不同位置的自适应融合权重进行学习(见图2 (a))。
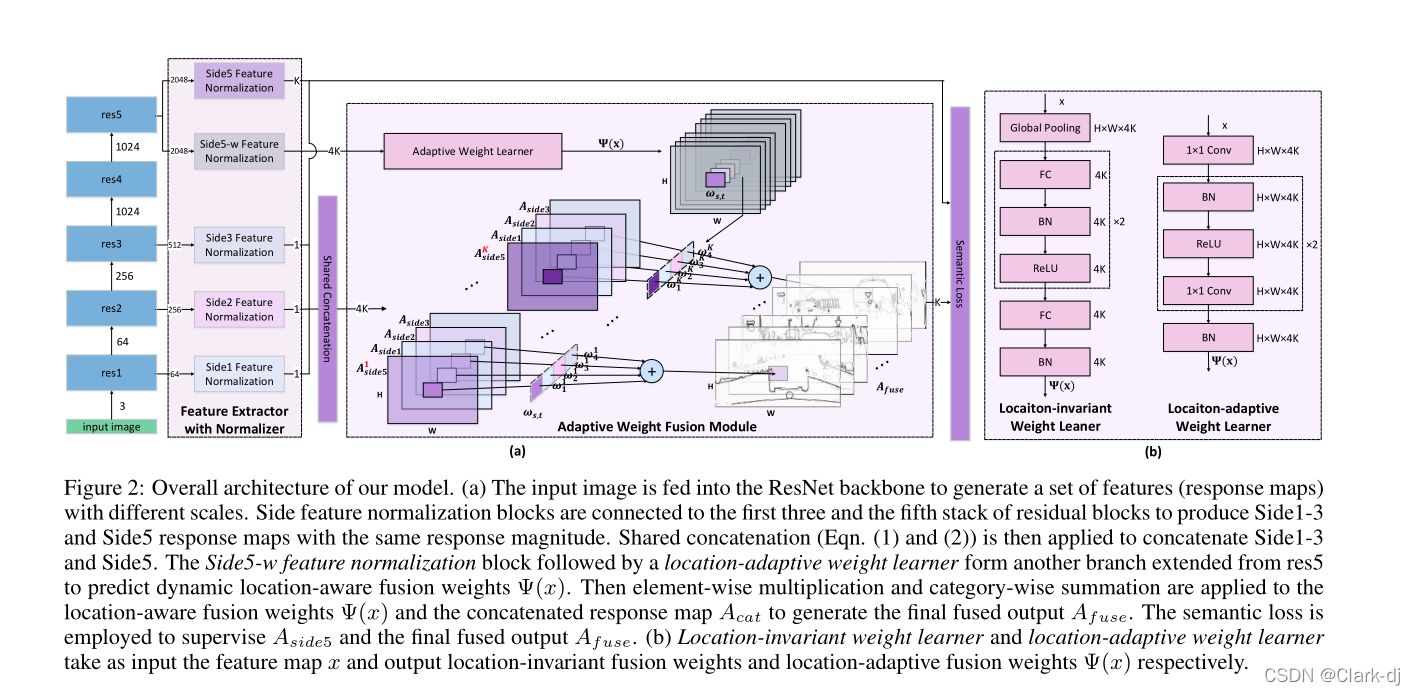
图2:我们模型的总体架构。
(a)
- 输入图像被馈送到ResNet主干,以产生一组不同比例的特征(响应图)。
- 将边特征归一化块连接到剩余块的前三个堆栈和第五个堆栈,生成响应大小相同的Side1-3和Side5响应图。
- 共享连接(Eqn。(1)和(2))用于连接Side1-3和Side5。
- siide5 -w特征归一化块,然后是位置自适应权重学习块,形成res5扩展的另一个分支,预测动态位置感知融合weightsΨ(x)。
- 然后将元素乘法和类别求和应用于位置感知融合weightsΨ(x),并将连接的响应mapAcatto生成最终的融合输出taf使用。
- 语义损失被用来监督easide5和最终的融合输出。
(b)位置不变权值学习者和位置自适应权值学习者分别以特征映射为输入,输出位置不变融合权值和位置自适应融合权值weightsΨ(x)。
- 主干网络仍然采用resnet-101,在前三阶段提取通道数为1的标准化特征图 ,在第五阶段提取通道数为k和4k的标准化特征图,同CASENet一样,用前三阶段提取的特征图和第五阶段提取的k个特征图做shared concatenation生成4k个连接特征图(具体见CASENet)。
- 用第五阶段提取的4k个标准化特征图来经过自适应权重学习器学习得到4k个H*W的权重图,这样权重参数4k*H*W与连接特征图的像素点个数相等,对于连接特征图的每个像素点都会有一个对应的权重,而不是以往的对于同一张连接特征图的所有像素点其权重都是相同的。
- 然后用这些权重来做融合。
- 自适应权重学习器结构见上图b,其把原来的位置不变权重学习器结构中的全连接换成了1*1卷积并去掉了全局池化操作,使得原来只能得到1*1*4k的权重参数量变成了H*W*4k。
动态特征融合
第一个模块的灵感来自以下观察。
在CASENet [Yuet al., 2017]中,来自顶层的边缘响应要比来自其他三个底部输出的边缘响应强得多。这种激活尺度上的变化使多层特征融合倾向于来自顶层的反应。此外,顶层的输出与训练示例的groundtruth非常相似,因为有直接的监督。对所有位置应用相同的权重会迫使网络为顶级特征学习更高的融合权重,而不希望忽略来自低级特征的贡献。这进一步抑制了在边缘和非边缘像素的严重偏置分布的情况下,低级别特征提供用于检测对象边界的精细边缘信息。
因此,在特征融合之前,我们首先通过标准化多级响应的大小来处理它们的尺度变化。这样,下面的自适应权重学习者就可以摆脱尺度变化带来的干扰,更容易地学习有效的融合权重。
如图所示,DFF模型是通过以下两个模块融合多层特征的。
1. 带归一化的特征提取模块,用于将多层特征的幅值尺度进行归一化。这个模块在特征融合之前,通过归一化它们的大小来处理多层响应的尺度变化。通过这种方式,下面的自适应权重学习模块可以避免尺度变化所带来的干扰,更容易学习到有效的融合权重。(该特征提取器主要将多层响应缩放到相同的量级,为下行融合操作做准备。)
2. 自适应权重融合模块,学习用于多层特征图不同位置的自适应融合权重。作者设计了两种不同的方案预测自适应融合权重,即位置不变的融合权重和位置自适应的融合权重。
- 位置不变的融合权重:前者同等对待特征图中所有位置,并且根据特定输入自适应地学习通用融合权重。根据图像内容动态生成特定位置的融合权值。
- 位置自适应的融合权重:后者根据图像位置特征自适应调整融合权重,并且提升低层特征对沿着目标轮廓精确定位边缘的贡献。应用特定位置的融合权值,主动融合高、低层次响应图;自适应权值融合模块能够充分挖掘多级响应的潜力,特别是低阶响应的潜力,从而在每个位置产生更好的融合输出。
对比CASENet
具体来说,考虑到多级侧输出H×W的激活,目标是通过聚合多级响应来获得融合输出。Eqn(3)中CASENet中的融合操作。 可以写成以下一般形式:
不同的是,我们提出了一种自适应权重学习器来主动学习基于特征映射本身的融合权重,其公式如下:
- 其中X表示特征图。上述公式描述了我们提出的自适应权重融合方法和固定权重融合方法之间的本质区别。
- 我们强制融合权重W显式地依赖于特征map x,即W=ψ(x)。
- 不同的输入特征映射会产生不同的参数ψ(x),从而导致对自适应权重学习器f(.;)的修改动态的。
- 这样,语义边缘检测模型可以快速适应输入图像,并以端到端的方式学习适当的多级响应融合权重。
- 关于ψ(x),对应于两种融合权重方案,有两种自适应权重学习器,即位置不变权重学习器和位置自适应权重学习器。位置不变权重学习者学习的融合权重总计为4K,如下式所示,由待融合特征地图的所有位置共享:
- 然而,位置自适应权重学习器为每个空间位置生成4K融合权重,这总共会产生4KHW权重参数。
- 位置不变权重学习器为所有位置生成通用融合权重,而位置自适应权重学习器根据空间变化为每个位置定制融合权重。

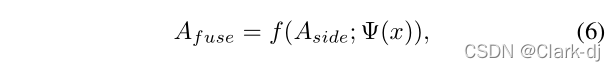
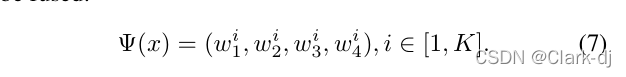
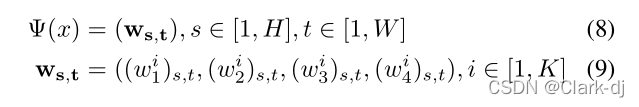
网络结构
如DFF网络结构图所示,DFF基于ResNet,使用和CASENet相同的方式对其进行了一些修改,保留了低层边缘信息。
- 我们提出的网络架构基于ResNet[Sheet al.,2016],并采用了与CASENet[Yu等人,2017]相同的修改,以保留低级边缘信息,如图2所示。
- 侧特征归一化块连接到前三个和第五个剩余块堆栈。该区块由1×1卷积层、批量归一化(BN)[Ioffe and Szegedy,2015]层和反卷积层组成。
- 1×1卷积层分别为Side1-3和Side5生成单通道和K通道响应图。将BN层应用于1×1卷积层的输出,以规范化相同量级的多级响应。
- 然后使用反卷积层对响应图进行上采样,使其达到原始图像大小。
- 另一个侧特征归一化块连接到剩余块的第五堆栈,其中生成4K通道特征映射。
- 然后,自适应权重学习器接收Side5-w特征归一化块的输出,以预测动态融合权重W(x)。我们分别为位置不变权重学习器和位置自适应权重学习器设计了两个实例,如下所述。
- 位置不变的权重学习。(见图2(b))这是自适应权重学习的简单版本。它生成4K个位置不变的融合权重,它们取决于输入内容,但是所有位置都共享相同的融合参数。Side5-w特征规格化块X的输出(size H×W×4K)作为全局平均池层的输入,以生成4K信道向量。之后,交替连接的FC、BN和ReLU层块重复两次,然后是FC和BN层,以生成用于size H×W×4K的融合响应mapAf的4K位置不变融合权重。这些融合权重取决于输入内容,但所有位置共享相同的融合参数。
- 位置自适应的权重学习。它为Side1-3和Side5上的每个空间位置预测4K个融合权重,从而让低级响应为目标轮廓提供精细定位。后面的消融实验表明,激活函数在产生自适应融合权重的情况下对性能有阻碍。
进一步提出了位置自适应权重学习器(见图2(b))来解决固定权重融合的缺点。特征图X被转发到一个由交替连接的1×1 conv、BN和ReLU层组成的块中,重复两次,然后是1×1卷积和BN层,以生成大小为size H×W×4K的位置感知融合权重W(x)。然后将元素相乘和类别相加应用于位置感知融合权重和用于生成最终融合输出的融合响应map A f。location adaptive weight learner(位置自适应融合权重)为1-3侧和5侧的每个空间位置预测4K融合权重,以允许低水平响应为对象边界提供精细的边缘位置。人们可以考虑将SOFTMAX激活函数应用到自适应权重精简器的输出,以学习分别融合的侧面特征映射的融合权重。第5节中的消融实验5.2.证明在生成自适应融合权重的情况下,激活函数会影响性能。
实验
先后分别对归一化、位置不变的权重学习、位置自适应的权重学习、激活函数以及主干网络的深度等五个因素进行了消融实验,结果如下面两个表所示。
表1:我们提出的模型中每个组件在cityscape数据集上的有效性。所有类别的MF得分的平均值用%来衡量(消融实验结果)
主干网络深度影响
最后,作者在Cityscapes和SBD数据集上分别将DFF和其他SOT方法进行了性能对比,如下面两个表所示。
Cityscapes数据集方法结果
SBD数据集方法结果
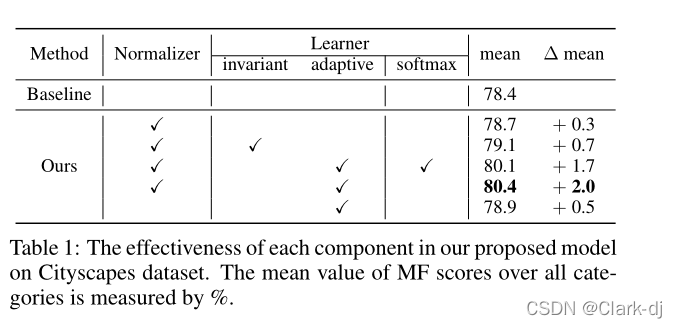



图3:ground truth、CASENet、SEAL和DFF城市景观的定性比较(图中从左到右排序)。



















 1456
1456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











