






最近因为需要给大数据金融学院的学生讲解《Python数据挖掘及大数据分析》的课程,所以在这里,我将结合自己的上课内容,详细讲解每个步骤。作为助教,我更希望这门课程以实战为主,同时按小组划分学生,每个小组最后都提交一个基于Python的数据挖掘及大数据分析相关的成果。但是前面这节课没有在机房上,所以我在CSDN也将开设一个专栏,用于对该课程的补充。
希望该文章对你有所帮助,尤其是对大数据或数据挖掘的初学者,很开心和夏博、小民一起分享该课程,上课的感觉真的挺不错的,挺享受的。我也将认真对待每一个我的学生,真的好想把自己的所学的所有知识都给予你们。同时由于学生来自不同的学院,有的甚至没有接触过编程,所以这门课程也将采用从零单排的形式讲述。
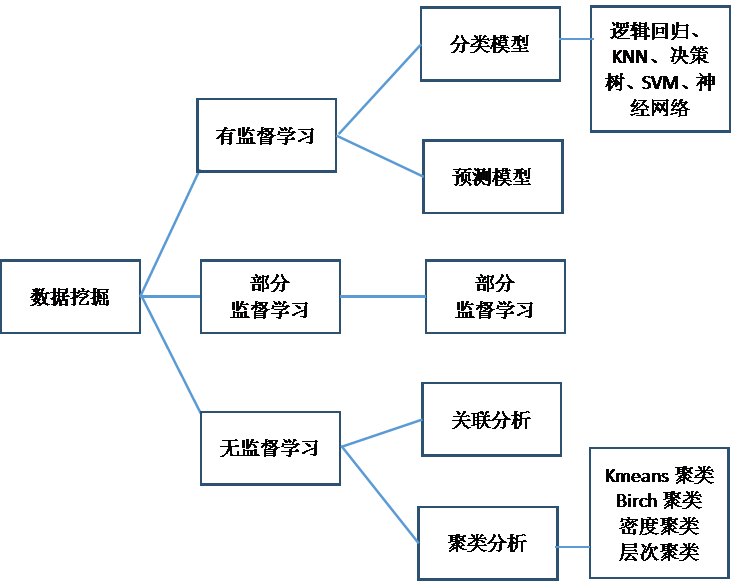
这门课程围绕下图所示的内容进行展开及实战。
课程资源:

希望该文章对你有所帮助,尤其是对大数据或数据挖掘的初学者,很开心和夏博、小民一起分享该课程,上课的感觉真的挺不错的,挺享受的。我也将认真对待每一个我的学生,真的好想把自己的所学的所有知识都给予你们。同时由于学生来自不同的学院,有的甚至没有接触过编程,所以这门课程也将采用从零单排的形式讲述。
这门课程围绕下图所示的内容进行展开及实战。
课程资源:

 订阅专栏 解锁全文
订阅专栏 解锁全文















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











