







原文链接:ECCV2022解读:首篇基于环视相机的端到端自动驾驶框架!
论文地址: https://arxiv.org/abs/2207.07601
项目地址: https://github.com/OpenPerceptionX/ST-P3
7月4日,ECCV 2022放榜,今年共收到8000多篇投稿,其中1629篇论文被接收,接收率不到20%。上海人工智能实验室自动驾驶团队与上海交通大学严骏驰副教授团队合作的论文《ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning》被ECCV 2022接收。该论文提出了第一个基于环视相机的,具有显示中间表征结果的端到端自动驾驶框架。针对感知-预测-规划三个子模块,团队分别做了提升时空特征学习性能的特殊设计,包括:基于累积的静态物体特征增加与动态物体特征对齐,结合历史特征变化与未来不确定性建模的双路预测模块,网络前部特征融合提升规划性能。

端到端一体化的训练方式下,三个模块的性能在nuScenes上的感知、预测与开环规划效果均超越相应的方法达到SOTA,并且在CARLA上的测试也可以超越经典的基于多模态的Transfuser方法,下面为大家对这篇文章进行解读。
1如何提高视觉的时空特征性能实现端到端训练?
自从1988的Alvinn开始,端到端自动驾驶便进入了人们的视野,随着深度神经网络的发展,在近五年成为了学术及工业界的一个流行话题。基于RL/IL的一系列工作在CARLA等benchmark上展现了不俗的效果。但是这些方法大都只是简单通过一个预测头输出控制信号,是一个黑盒模型。此类黑盒模型做出的驾驶决策的原因我们无从得知,在系统出现问题后也难以排查,这对安全驾驶形成了重大挑战。考虑到端到端自动驾驶的安全性,一个具备良好可解释能力的模型对于安全驾驶来说很有必要。
过去几年,Uber ATG团队在LiDAR的感知决策一体化方面作了充分的研究,有NMP[1]、DSDNet[2]、P3[3]、MP3[4]等工作,基于纯视觉的端到端的感知决策一体化模型却鲜有研究。但考虑到成本问题以及视觉方面的优势(交通灯、远距离检测等),基于纯视觉的框架也具有较大的研究潜力。如果每个模块都设计精巧,那么每个任务在感知、预测和规划方面的性能应该提高到什么程度,如何提高视觉的时空特征性能实现端到端训练?
从以上的问题出发,团队提出了ST-P3网络(ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning)。
2显示中间表征的环视端到端自动驾驶框架
ST-P3 pipeline
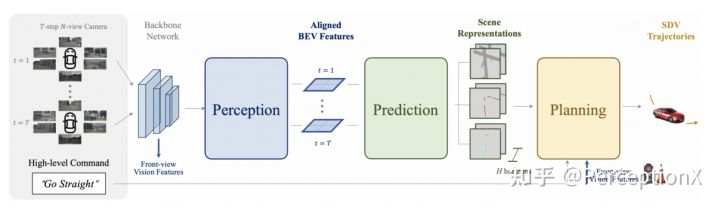
ST-P3整体pipeline
ST-P3, 一个基于视觉的可解释的端到端系统,该系统可以改善感知、预测和规划的特征学习,上图描述了它的整体框架。多个时刻下的环视相机图像会依次经过感知、预测、规划模块,输出最终的规划路径。其中,感知和预测模块的feature输出,可以经过decoder得到不同类型的场景语义信息,增强可解释性。团队还通过每个模块中特殊的设计来增强时空特征的学习,下面将对每个模块进行详细的介绍。
感知模块(Egocentric Aligned Accumulation)
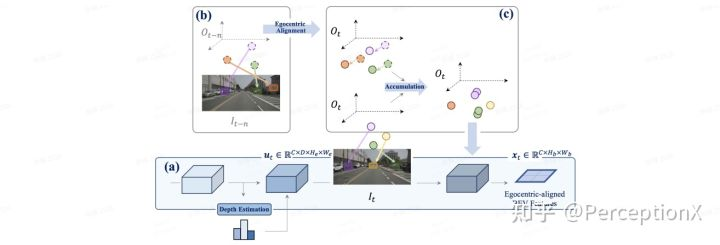
感知模块的时空融合算法示意图
基于视觉的方法的第一个关键挑战是将特征表示从透视图适当地转换为鸟瞰图 (BEV) 空间。开创性的 LSS [5]方法从多视图相机中提取透视特征,通过深度估计将它们提升为 3D 并融合到 BEV 空间中。而为了进一步提高特征的表征能力,可以将时间信息合并到框架中,我们在 3D 空间中累积所有过去对齐的特征,尽可能保留更多的几何信息。
该模块中我们分为空间融合和时序融合:
-
空间融合:在某一时刻时,我们首先将用LSS方法提取的各个视角的图片特征统一转化到以自车为中心的3D空间中,然后为了下游任务的处理方便,需将过去时刻的特征统一转化到当前特征。最后我们将该3D空间的特征进行“压扁”,在垂直坐标轴上进行累加从而将3维特征转化为2维特征,大大减小后续的计算量。值得注意的是我们在3D空间进行特征对齐,是考虑到raw/pitch角不为0的时候BEV对齐方法会存在问题。
-
时序融合:注意到不同时刻的对应的相同位置应具有类似的特征,比如车道线,静止的车辆等。基于这个性质我们首先进行自注意力机制来加强对静态物体的识别能力,即每一个时刻的特征还要累加上之前处理的所有的特征,如下面公式所示。而为了更加精确的感知动态物体,我们随后用3D卷积来进一步处理上述特征。
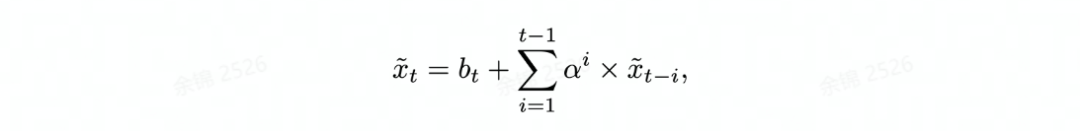
感知输出的特征将与下一步的预测特征一起共同经过decoder头,根据中间表征结果进行监督。同时,我们也对深度估计部分进行显示监督,这思路也与最近的BEVDepth[6]等工作不谋而合。我们也将会开源我们通过其它额外网络训练用以监督的深度图。
预测模块(Dual Pathway Probabilistic Future Modelling)
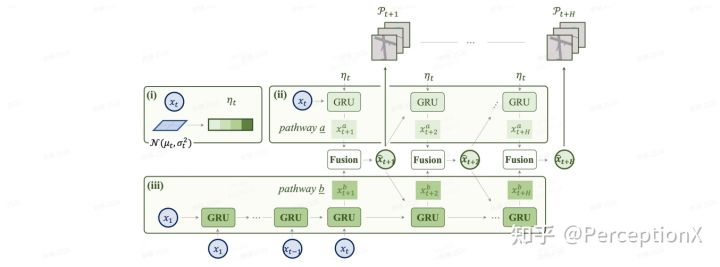
预测模块的Dual-GRU结构示意图
为了适应 BEV 空间中的代表性特征,我们将预测任务制定为未来场景的实例/语义分割,这与 FIERY[7]中的设定相同。类似FIERY的设计,我们首先将未来不确定性建模成高斯分布,并将其作为hidden state输入到时序模型中。但FIERY仅根据所有历史信息融合后的一个feature进行预测,而为了提高未来预测,我们需要更显示地考虑过去的运动变化,故本文引入一个具有融合单元的附加时间模型来推理过去和未来运动的概率性质。
path_a 用之前生成的不确定度作为输入且用当前时刻的状态作为隐状态,path_b 则用历史的特征作为GRU的输入,并且使用最早时刻的特征初始化隐状态。当预测t+1时刻的特征时,我们将两条线路预测的状态以混合高斯的形式进行混合,并将其作为下一时刻的输入。
最终生成的所有状态将会被送到各个decoder中生成不同的可解释中间表示,具体来说包含8个decoder头:
-
instance (centerness, offset, flow)
-
semantic (vehicle, pedestrian, drivable area, lanes)
-
cost volume
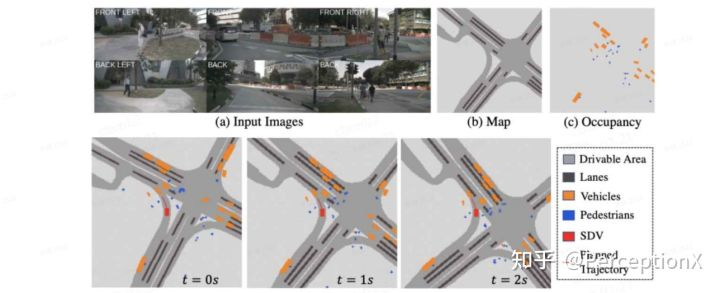
预测模块的中间表征输出
规划模块(Prior Knowledge Incorporation and Refinement)
作为最终目标,运动规划器需要规划一条朝向目标点的安全舒适的轨迹。它根据high-level command采样一组不同的轨迹,并选择一条最小化代价的路径,其中cost分为(1)上一步通过学习得到的预测cost volume,(2)根据感知得到的场景表示人为设定的各项cost。且我们将通过额外的优化步骤来整合目标点和交通信号灯的信息。其图示过程如下:
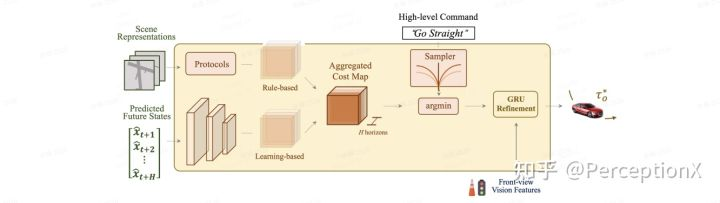
规划模块结构示意图
特别地,人为设定的cost function构造可充分利用先验知识,例如:
-
安全性:轨迹不应与道路上其他agents相撞;在道路上车辆通常会跟随着前车并且保持着一定的安全距离;车辆应尽可能在道路中心行驶等。
-
舒适性:会导致乘坐体验不适的较大的径向加速度或者侧向加速度都应具有较大的cost。
为了更好地将红绿灯情况纳入到轨迹生成的考虑中,我们将上一步选出来的具有最小成本的轨迹进一步细化。我们将encoder生成的前视摄像头的特征作为隐特征,轨迹和目标点作为输入输入到GRU中,通过这种方式最终细化后的轨迹能够较好的判断出红绿灯并且能够正确地导向目标点。
3实验结果
由于ST-P3具有显示的中间表征,我们可以将每个模块解码出的结果与其它相应方法进行比较,其中感知与预测模块在nuScenes上比较,最终的规划结果分为nuScenes上的开环任务与CARLA仿真环境中的闭环任务比较。
感知模块结果
对于感知模块而言,我们主要评估地图模块和语义分割的结果。感知到的地图包括可行驶区域和车道线——这是驾驶行为的两个最关键的元素,因为SDV需要在可行驶区域内行驶并保持在车道中心。而语义分割侧重于车辆和行人,两者都是驾驶环境中的主要参与人。我们使用 IoU作为度量,将感知模块建模为 BEV 分割任务。如下表格所示,我们的方法在nuScenes验证集上取得了最高的平均值,使用我们的感知模块超过了之前的SOTA。
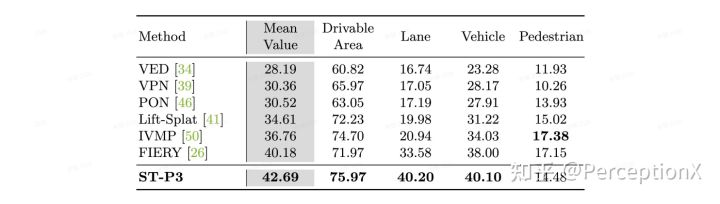
感知模块输出结果比较
预测模块结果
在FIERY文章中首次提出预测 BEV 中的未来分割任务,我们选择它作为我们的baseline。我们通过 IoU、现有全景质量 (PQ)、识别质量 (RQ) 和分割质量 (SQ) 来评估我们的模型,这些指标遵循视频预测区域中的指标。由下表可知,由于预测模块的新颖设计,我们的模型在所有指标中达到了最优秀的水平。

预测模块输出结果比较
最终规划结果
可以看到,我们的ST-P3在开环nuScenes数据集和闭环CARLA上都取得了当前基于视觉方法下的最好结果。注意到在闭环实验中,我们的方法在长程情况下在道路完成率上远远领先基于LiDAR方法的Transfuser,虽然另一方面长距离的运动导致了更高的惩罚系数,总体来看ST-P3的设计符合道路行驶条件。
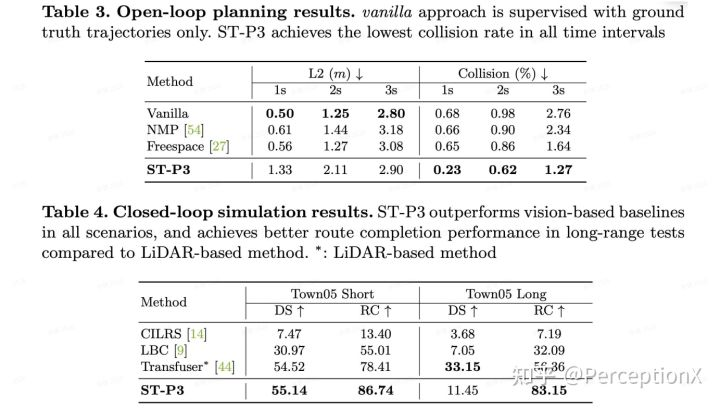
规划(nuScenes开环,CARLA闭环)结果比较
Ablation分析
下表格显示了 ST-P3 中不同模块的有效性。
-
Exp.1-3 展示了深度监督信息和以特征累积(EAA.)对感知的影响。
-
Exp.4-6 展示了双路GRU和相应的训练方式(对所有历史状态计算损失,LFA.)对预测任务的影响。由于双路GRU同时考虑了不确定性和历史连续性,因此过去特征的正确性在其中起着至关重要的作用。
-
Exp.7-9 则显示了规划中的采样器和 GRU 细化单元的作用。没有前视相机特征refinement(Exp.7)或没有先验采样知识的隐式模型(Exp.8)都会导致较高的规划误差和碰撞率。
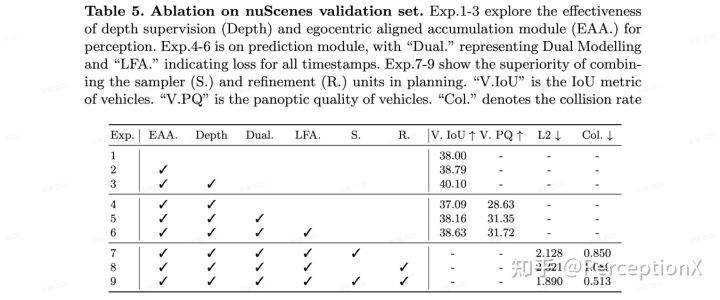
各模块消融实验
4可视化结果
下面展示nuScenes和CARLA上的可视化结果,更多的结果可以参考补充材料~

nuScenes转弯场景
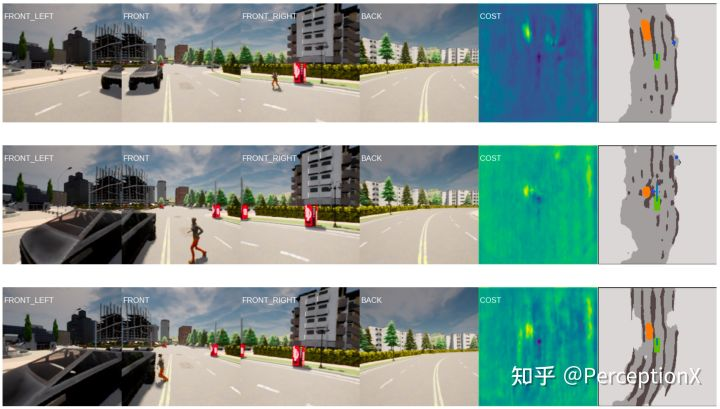
CARLA测试躲避行人场景
5下一步工作
总体来说,ST-P3作为第一个中间结果显示设计的环视端到端自动驾驶网络,还是较为基础的。同时我们的结果表明更好的中间结果表示对于最终规划的精度提高有着重要的重要,证明了端到端设计最终结果的精度同样依赖于中间结果的精度,这启发着我们进一步提高中间结果的精度。近期随着BEV vision learning任务的兴起与流行,我们相信这些工作带来的更好的感知/预测结果也能带来在端到端任务上的性能提升。同时为了实现最终模型的部署应用,多帧环视输入模型的速度也需要进一步地提高。
6参考
-
^https://arxiv.org/abs/2101.06679
-
^https://arxiv.org/abs/2008.06041
-
^https://arxiv.org/abs/2008.05930
-
^https://arxiv.org/abs/2101.06806
-
^https://arxiv.org/abs/2008.05711
-
^https://arxiv.org/abs/2206.10092
-
^https://arxiv.org/abs/2104.10490
独家重磅课程官网:cvlife.net

全国最大的机器人SLAM开发者社区

技术交流群
















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









