







音乐预测大赛的初赛今天轰轰烈烈地谢幕了,先来看看排名前10的队伍吧
我们队的成绩在切换数据后一直没有特别大的长进,虽然成绩没有达到预期,但是初赛这些天还是涌现并实现了一些不错的思路,有一些还没有来得及实现或者优化,相比去年资金预测时候的我们已经有很大进步啦(自我安慰)。看到群里不少人在询问大神团队的经验方法,虽然我们排名比较靠后,远远算不上大神,但是也有一些收获,故在此总结一下我们队用到的比较重要的特征或者方法,希望给新人有所帮助!
我们队的宗旨
首先说明一下我们团队比赛的宗旨:
1、尽量用模型实现,少些人工成分。因为去年比赛没有经验,所以很多时间都在人工调整参数(算是规则吧),有时候就是臆想或瞎猜,现在想想其实收获并不大,还很浪费时间,打比赛就是要学习一套思路和方法。
2、坚持每天提交成绩,每天有进步。每天提交成绩是我们立下的目标,比赛下来2个月每天坚持也是一种挑战,这也是一种逼自己去想去思考的办法。每次提交成绩都要有针对性,要么是尝试某个特征,要么是尝试某个模型,或者某种新思路,切忌盲目地手动改改就提交成绩,掩耳盗铃啊。
3、多去尝试新的思路和方法。一步步深入下去你会发现很多有趣的东西(后续博客中会具体介绍)。
好啦,废话不多说,下面进入正题。下面给出我们队一步步做用户分类(也称为用户画像)的思路和方法。
用户分类初步
资金预测的时候大熊老师做过对余额宝用户的分类,这点我在《阿里音乐流行趋势预测大赛一起做-(5)温故知新 》里详细提到,有兴趣可以回看一下。这个思路估计大部分队伍都有,那么具体如何做呢。
1、首先大家都能想到的就是粉丝用户和非粉丝用户。我们可以简单的认为粉丝用户就是:某个用户对一首歌有下载,并且播放总量超过一定的阈值,则认为该用户是粉丝用户;否则是普通非粉丝用户。当然也可以定义为有收藏,并且播放总量超过一定的阈值,则认为是粉丝用户,总之就是收藏、下载、播放量的组合选择。
2、我们需要得到一个统计每个用户对其所听的每个歌曲的总收藏量、总下载量、总播放量的一个表(见后面user_song_index表)。如下图所示:
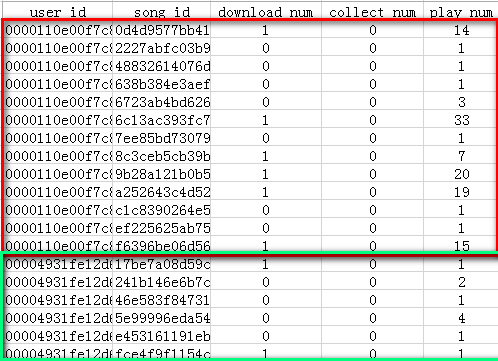
图中红色和绿色框内分别表示两个不同用户对其所听的所有歌曲的收藏、下载、播放总量的统计表。
3、这部分的代码如何实现呢?这是很多人最关心的问题。我们队实现的Python代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 生成用户-歌曲-行为统计表
tianchi_user_actions = pd.read_csv('F:/AliMusicTianChi/mars_tianchi/mars_tianchi_user_actions.csv')
# 删除列gmt_creat
del tianchi_user_actions['gmt_creat']
del tianchi_user_actions['Ds']
# 将action_type做哑变量处理
temp = pd.get_dummies(tianchi_user_actions['action_type']).join(tianchi_user_actions)
# 对操作类型对应的列名进行重命名
temp = temp.rename(columns={1:'play_num',2:'download_num',3:'collect_num'})
# 删除列action_type
del temp['action_type']
# 将数据按照user_id,song_id两级聚合
grouped = temp.groupby([temp['user_id'],temp['song_id']])
# 统计播放、下载、收藏的总量
user_song_index = grouped.agg({'play_num':'sum','download_num':'sum','collect_num':'sum'})
# 导出为csv表格
user_song_index.to_csv('F:/AliMusicTianChi/data/classify_users/user_song_index.csv') 4、得到了这样的一个表user_song_index后,我们需要把mars_tianchi_user_actions表中按照不同的用户分别取出来,一个专门存放粉丝用户的行为记录(表fan_table),另一个专门存放非粉丝用户的行为记录(表non_fan_table)。有了表user_song_index,我们可以用如下代码实现不同用户行为记录的提取:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 用户分类:认为有下载、总播放量大于5的用户是粉丝用户,其他为非粉丝用户
user_song_index = pd.read_csv('F:/AliMusicTianChi/data/classify_users/user_song_index.csv')
# 设置用户分类规则
index = np.logical_and(user_song_index['download_num']>0,user_song_index['play_num']>5)
fan_list_tmp= user_song_index[index]
fan_list = sorted(set(fan_list_tmp['user_id']))
# in1d(x,y)表示得到一个x是否包含于y的布尔型数组
fan_index = np.in1d(tianchi_user_actions['user_id'],fan_list)
non_fan_index = np.logical_not(fan_index)
fan_table = tianchi_user_actions[fan_index]
non_fan_table = tianchi_user_actions[non_fan_index]
fan_table.to_csv('F:/AliMusicTianChi/data/classify_users/fan_table.csv')
non_fan_table.to_csv('F:/AliMusicTianChi/data/classify_users/non_fan_table.csv')5、然后我们用这两个表分别运行自己的模型,然后叠加到一起就是最后的结果。
用户分类进阶
前面我们已经可以实现根据用户不同行为组合进行简单的用户分类。那么问题来了,这样分类真的好吗?什么样的分类才是好的分类?
我觉得好的分类要满足几个条件:
1、首先分类具有可解释性。针对音乐预测我们可以考虑一下针对用户这一个维度分类是否合理。我们可以考虑大部分人的听歌习惯:
1)下载了音乐软件后,首先收藏自己喜欢的歌曲或者艺人,下载自己喜欢的歌曲。
2)想听歌了,打开收藏的列表或者下载的列表的歌曲播放。
3)有时候心血来潮可能会试听软件推荐的歌单。
4)听了电视剧或电影中的主题曲、插曲觉得不错会试听。
5)得知某个喜欢的歌手发行了新歌会去下载、播放、收藏。
6)某首歌曲最近比较火,会播放听一听,如果喜欢可能会下载或收藏。
相信大部分的人习惯都是这样,所以每个用户的每天可能有稳定的播放歌曲。换句话说,就是每个用户可能下载了很多歌曲,但是经常播放的只是其中一部分。所以“用户分类初步”里使用用户一个维度进行粉丝划分并不是非常符合实际情况。
综上,建议使用user_id & song_id两个维度作为粉丝分类更为合适。
2、用户分类后的统计数据应该在同一个数量级上。举个极端点的例子,比如你按照某种方式分类后粉丝的播放量一般为每天10次左右,非粉丝的一般为每天1000次左右,由于数量级相差较大,那么两者相加时粉丝的分类结果就淹没在非粉丝的茫茫大海之中。即使你粉丝部分预测的再好也无济于事。
3、用户分类后的数据应该更容易预测。用户分类的目标就是把一个复杂问题分解成多个简单问题的叠加。所以衡量一个分类是否好坏的重要标志就是分类后的数据应该变地更平稳了、更有规律了、或者有很好的线性等,这些特点可以提高预测的精度。
后记
每个人根据不同的方法进行用户分类都会有不同的结果,有的人可能分离出容易预测的线性数据,有的人可能分离出明显的周期性数据。一千个人眼中有一千个哈姆雷特,所以如果你深入一步步得挖掘,一定会发现适合于自己的分类方法。
欢迎参赛同学分享观点,祝大家在复赛中取得佳绩!















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









