






Supplementary information | nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation
’Automated Design of Deep Learning Methods for Biomedical Image Segmentation’稿件的补充信息。
1、Dataset details
Table SN1.1提供在这个手稿中使用的数据集的概述,包括数据访问的相应参考文献。这里给出的数值是根据每个数据集的训练案例计算的。它们是图5中显示的数据集指纹dataset fingerprints的基础。

Table SN1.1: Overview over the challenge datasets used in this manuscript
2 nnU-Net design principles
在这里,从概念层面简要概述nnU-Net的设计原则。
2.1 Fixed parameters
- 架构的设计决策
- 当pipeline配置良好时,类似U-Net的架构能够达到最先进的分割效果。根据作者实验,复杂的架构变化,并不一定能够产生最好的分割效果。
- 我们的架构只使用简单的卷积convolutions、实例规范化instance normalization和Leakey nonlinearities的非线性。每个计算块computational block的运行顺序是conv-instance norm-leaky ReLU.
- 在每个分辨率阶段都有两个计算块computational block,分别在encoder和decoder中。
- 下采样Downsampling是用交叉卷积strided convolution完成的(新分辨率的第一个块block的卷积stride>1),上采样upsampling是用反卷积convolutions transposed完成的。我们应该注意到,在这种方法和备选方案之间(例如最大池化max pooling,双线性/三线性上采样bi/trilinear upsampling),我们没有在分割精度上观察到实质性的差异。
- 选择U-Net的最佳配置:很难估计哪个U-Net配置在哪个数据集上表现最好。为了解决这个问题,nnU-Net设计了三个单独的配置,并根据交叉验证cross-validation自动选择最佳配置(参见基于规则的参数)。预测哪些配置应该在哪些数据集上训练是未来的研究方向。
- 2D U-Net:运行在全分辨率数据,期望能在各向异性数据上很好地工作。如D5(Prostate MRI)和D13 (ACDC,cine MRI)(数据集参考见Table SN1.1)。
- 3D full resolution U-Net:运行在全分辨率数据。补丁大小Patch size受GPU内存可用性的限制。总体上是性能最好的配置(参见6中的结果)。然而,对于大数据,补丁大小patch size可能太小,无法聚合足够的上下文信息。
- 3D U-Net cascade:特别针对大数据。首先,粗分割图是通过一个3D U-Net在低分辨率数据上操作来学习的。然后,第二个3D U-Net对全分辨率数据进行处理,对这些分割图进行细化。
- 训练方案
- 所有的训练都以1000个epoch的固定长度运行,其中每个epoch被定义为250个训练迭代(使用nnU-Net配置的批大小batch size)。在经验上,较短的训练时间会导致分割性能下降。
- 对于优化器optimizer而言,具有高初始学习率high initial learning rate(0.01)和大nesterov动量large nesterov momentum(0.99)的随机梯度下降法stochastic gradient descent效果最好。在使用[14]中的“polyLR”计划在训练期间,降低学习率,几乎是线性下降到0。
- 数据扩增对于达到最先进的性能是至关重要的。重要的是在联机中运行这些增强,并使用相关的概率来获得永不结束的惟一示例流(详细信息见第4节)。
- 生物医学领域的数据存在类别不平衡的问题。罕见的类别class最终可能会被忽视,因为它们在训练中没有得到充分的表示。过采样前景区域Oversampling foreground regions可以可靠地解决这个问题。但是,不应该过度使用,这样网络也可以看到背景的所有数据变异性。也就是过采样前景区域过度使用,会导致网络学习到不该学习的背景变化。
- Dice loss function很适合解决类别不平衡的问题,但也有它自己的缺点。Dice loss直接优化了评估指标,但由于基于补丁patch的训练,所有在实践中仅仅近似于它。此外,类别过采样oversampling of class扭曲了在训练中看到的类别分布。经验上,将Dice loss 和交叉熵损失cross-entropy相结合可以提高训练的稳定性stability和分割的精度accuracy。因此,这两项损失只是简单地取平均值。
- 推理
- 在交叉验证cross-validation中,所有折叠all folds的验证集通过在各自的训练数据上训练的单一模型来预测。在5个单独的折叠folds上训练得到的5个模型随后被用作预测测试用例的集成。5折训练,交叉验证选出最优的作为推理模型。
- 根据训练中使用的相同大小的补丁patch size进行推理。不推荐使用完全卷积推理. Fully convolutional inference,因为它会导致零填充zero-padded卷积和实例规范化instance normalization的问题。
- 为了防止拼接伪影,相邻的预测是在距离为patch_size/ 2的情况下完成的。对边界的预测不太准确,这就是为什么我们对softmax聚合使用高斯重要性权重(中心体素的权重高于边界体素)。
2.2 Rule-based parameters
这些参数不是跨数据集固定的,也就是不同的数据集有不同的设置,而是由nnU-Net根据手头任务的数据指纹data fingerprint(数据集属性的低维表示)实时配置的。
- 动态网络的适应Dynamic Network adaptation:
- 网络结构需要适应训练过程中看到的输入块的大小和间距the size and spacing of the input patches。也就是需要确保网络的接受域覆盖整个输入。patch训练一定要让整个输入能够完整的包含在不同的patch里面,不要漏掉
- 我们执行下采样直到特征图相对较小(最小值是4*4(*4)),确保有足够的上下文聚合。
- 由于在编码器和解码器endcoder and decoder中每个分辨率步骤都有固定数量的块blocks,网络深度与它的输入补丁大小input patch size耦合。网络中的卷积层数(不包括分割层)为(5*k + 2),其中k为下采样操作的次数(每下采样downsampling 5次源自编码器中的2个convs,解码器中的2个加上卷积转置convolution transpose)。其实也就是说前后两个卷积层中有每个下采样层中都有5个卷积层。
- 附加的损耗函数应用于除两个最低分辨率lowest resolutions之外的所有解码器decoder,以向网络深处注入梯度gradients。
- 对于各向异性数据,池化首先只在平面内执行,直到坐标轴之间的分辨率匹配为止。很好理解,就是将spacing不一样的数据通过池化操作将spacing变成一样的。最初,3D卷积在z轴上使用内核大小为1的(使其有效地成为2D卷积),以防止spacing较大切片的信息聚合。一旦一个轴变得太小,下采样单独停止这个轴。也就是spacing接近后就可以停止这个轴上的下采样了。
- 配置输入补丁的大小patch size
- patch size应该尽可能大,同时仍然允许批量大小为batch size=2(在给定的GPU显存限制下)。这将使网络中可用的决策环境最大化。也就是patch size能包含更多有效的判断信息。
- patch大小的长宽比遵循重采样训练案例的中间形状(体素)median shape(in volxels) of resmapled training case。
- 批量大小Batch size:
- 批大小batch size配置为最小2,以确保鲁棒优化robust optimization,因为在batch size小的时候梯度中的噪声会增加。
- 配置补丁大小patch size后,如果GPU显存空间还可用,则继续增加批量大小batch size,直到GPU显存达到最大值。因此应当是先设置patch size,然后在设置batch size。
- 目标间距和重采样Target spacing and resampling:
- 对于各向同性数据isotropic,训练案例的间隔中位数the median spacing of training cases(每个轴单独计算)设置为默认值。用三阶样条(数据)third order spline和线性插值linear interpolation(one hot编码分割图,如训练注释,也就是mask)进行重采样得到了很好的结果。其实simpleitk中有很好的重采样方案。
- 对于各向异性的数据,目标在离面轴上的间距应小于中值,从而获得更高的分辨率,以减少重采样伪影。也就是z轴的spacing应该偏小,层数增多。为了实现这一点,我们将目标间距设置为训练数据中该轴的间距的第10个百分位数。也就是z轴spacing设置为第1/10位的spacing,在平面外轴Z轴上的重采样是通过数据和one-hot编码分割图的最近邻来完成的。
- 灰度归一化intensity normalization
- 默认是每个图像的Z-sore(减去平均和除以标准偏差)。
- 作者只对CT图像不使用z-sore,其中全局归一化方案是基于所有训练案例中前景体素的强度确定的。
2.3 Empirical parameters
仅从训练案例的数据集指纹dataset fingerprint中无法推断出一些参数。这些都是在训练后通过监控验证性能来确定的。也就是训练完成后,同过验证集来修改empirical parameters。
- 模型选择model selection:虽然3D full resolution U-Net显示了总体上最好的性能,但特定任务需要选择最佳模型。因此,nnU-Net会生成三种U-Net配置,并在交叉验证cross-validation后自动选择性能最好的方法(或方法集合)。
- 后处理Postprocessing:通常,特别是在医疗数据中,图像只包含目标结构target structure的一个实例。这种先验知识通常可以通过在预测的分割图上进行联通分析,并去除除最大连通区域外的所有区域来加以利用。是否应用此后处理取决于在交叉验证后监控验证性能。具体来说,通过删除单个类别除最大连通区域的其他联通区域来提高Dice系数后,会触发后处理。
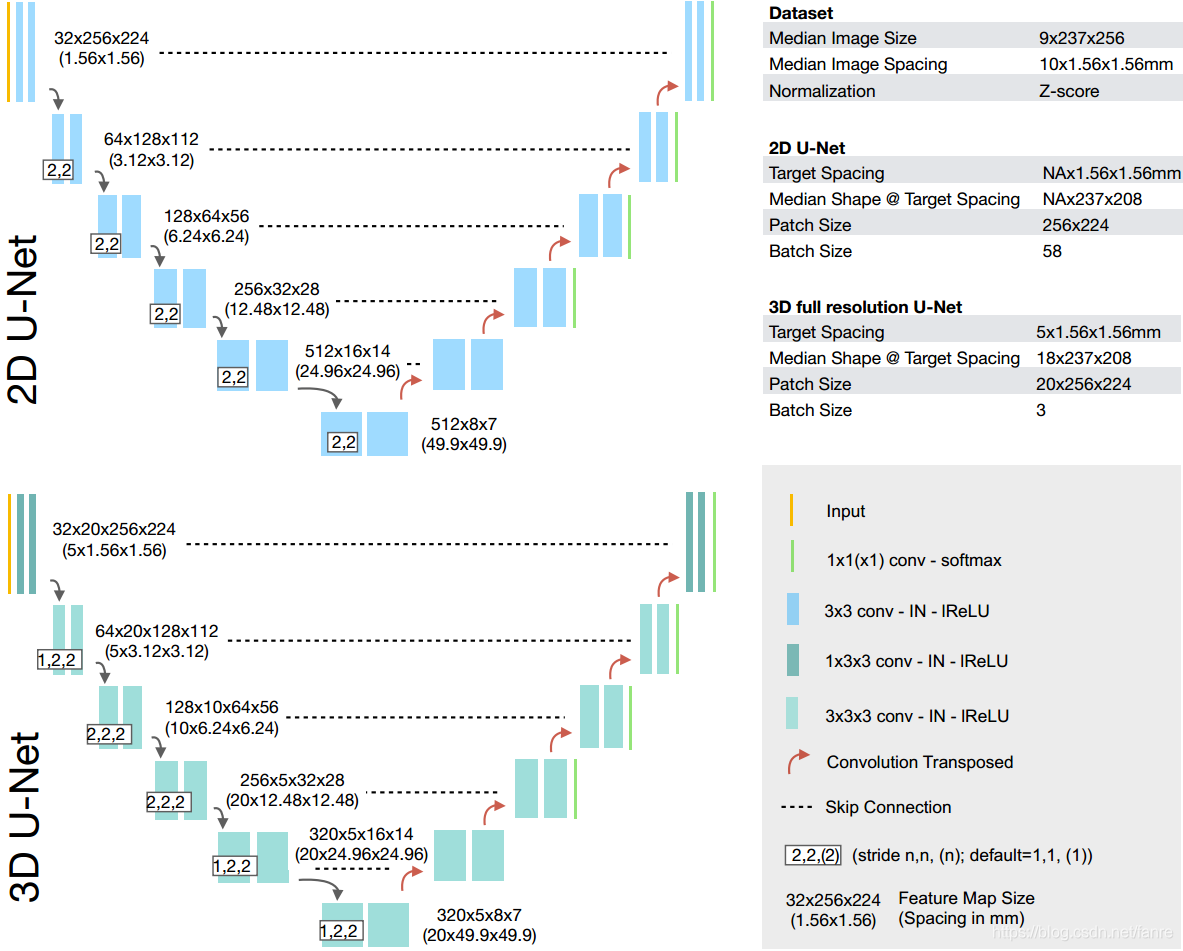
Figure SN3.1: Network architectures generated by nnU-Net for the ACDC dataset (D13)
3 nnU-Net-generated pipelines的经验分析
本节简要介绍nnU-Net为D13 (ACDC)和D14(LiTS)生成的管道pipelines,来创建一个直观的理解nnU-Nets的设计原则和背后的动机。
3.1 ACDC
图SN3.1提供了nnU-Net为该数据集自动生成的管道pipelines的摘要。
Dataset description 2017年由MICCAI主办的自动心脏诊断挑战赛The Automated Cardiac Diagnosis Challenge(ACDC)[6]。从那以后,它就成了一个公开的挑战,数据和当前的排行榜都可以在https://acdc.creatis.insa-lyon.fr上找到。在挑战赛的分割部分,参与团队需要在cine MRI图像中,分割出的右心室right ventricle,左心肌left myocardium和左心室腔left ventricular cavity。对于每个患者,提供了心动周期内两个时间步的参考分割。有100个训练患者,总共有200个标注图像。cine MRI的一个关键特性是在多个心动周期和屏住呼吸时进行切片获取。这使得切片数量有限、平面分辨率较低、且切片可能没对齐。图SN3.1提供了nnU-Net为该数据集自动生成的管道pipelines的摘要。一般的图像形状(这里的图像大小中值median image size分别为每个轴单独计算)为9x237x256 voxels,间距为10x1.56x1.56 mm。
Intensity normalization 当图像是MRI时,nnU-Net通过减去它们的平均值并除以它们的标准偏差来对所有图像单独进行标准化。
2D U-Net 为的。2D和3D full resolution U-Net的面内分辨率target spacing都是1.56x1.56 mm。由于2D U-Net只在切片上操作,这种Z轴分辨率没有改变,并且在训练集内仍然是异构的。2D U-Net已按照联机方式4Online Methods配置成补丁大小patch size为256x224 voxels,完全覆盖平面内重采样后的典型图像形状(237x208)。由于该数据集的大小size和间距spacing各向异性,因此选择3D full resolution U-Net的离面目标间距target spacing为5mm,也就是z轴,对应于训练案例中发现的间距的第10个百分点。在ACDC等数据集中,由于切片与切片之间的距离较大,分割轮廓在切片之间会发生很大的变化。选择较低的目标间距可以得到更多的图像,这些图像先被上采样进行U-Net训练,然后再被下采样进行最终分割输出。与中值median相比,选择这种变体会导致更多的图像被向下采样用于训练,然后向上采样用于分割输出,从而大大减少插值伪影。也就是通过10%target spacing z轴分辨率的方式,图像上采样,训练图像增加了,插值伪影减小了。还要注意的是,mask重新采样平面外轴是用最近邻插值完成的。3D full resolution U-Net重采样后的中值图像形状为18x237x208 voxels。在Online Methods 4的描述中 nnU-Net为网络训练配置的补丁大小为20x256x224,该patch size适合批量显存预算,批量显存大小为batch size=3。请注意3D U-Net中的卷积核大小是从(1x3x3)开始的,这实际上是初始层的2D卷积(参见图SN3.1)。这背后的原因是,由于体素间距的巨大差异,在切片间有太多的变化,因此直接聚合图像信息可能没有好处。类似地,池化只在平面内进行(conv kernel stride(1,2,2)),直到平面内和平面外轴之间的间距小于2。只有当间隔spacing与池pooling近似匹配之后,卷积核大小变为各向同性。
3D U-Net 由于3D U-Net已经覆盖了图像整个形状的中值,因此不需要进行U-Net级联。也就是只要能够覆盖整个median shape,就不需要级联。
Training and Postprocessing,在训练区间,3D U-Net的空间扩增spatial augmentation(如缩放和旋转)只在平面内进行,以防止成像信息在切片间的重采样,从而导致插值伪影。也就是重采样只在x、y方向上进行,不再z方向重采样。每个U-Net配置都在培训案例的五倍交叉验证five-fold cross-validation中进行培训。注意,我们进行数据划分是为了确保患者被正确分层(因为每个患者有两张图像)。由于交叉验证,nnU-Net可以使用整个训练集进行验证validation和集成ensembling。将五个fold中的每个验证划分聚合起来。nnU-Net通过对所有前景类和数据的Dice Scores平均值来评估性能(模型的集合ensemble或单个配置),从而得到单个标量值。为了简洁起见,详细的结果在这里被省略了(它们是作为补充提出Supplementary Information的6)信息。基于该评价方案,2D U-Net得分为0.9165,3D full resolution得分为0.9181,两者综合得分为0.9228。因此,选择集成ensemble来预测测试用例,对集成ensemble的分割图进行后处理。除了最大的连通区域外,去除其他所有的区域,对右心室和左心室腔都有好处。
Figure SN3.2: Network architectures generated by nnU-Net for the LiTS dataset (D14)
3.2 LiTS
图SN3.2提供了nnU-Net为这个数据集自动生成的管道pipelines的摘要。
Dataset description The Liver and Liver Tumor Segmentation challenge (LiTS)[3]是由2017年MICCAI举办的。由于它提供了大量、高质量的数据集,这一挑战在并发研究中扮演着重要的角色。挑战赛举办在https://competitions.codalab.org/competitions/17094,LiTS割任务是对腹部abdominal CT扫描中的肝脏liver和肝脏肿瘤liver tumors进行分割。该挑战提供了131个训练数据,并提供了参考标注。测试集有70个数据,只有挑战组织者知道参考标注。训练数据的的图像形状中位数为432x512x512体素,相应体素间距为1x0.77x0.77 mm。
Intensity normalization CT扫描中的体素强度与组织的定量物理特性有关。因此,扫描器之间的强度应该是一致的。nnU-Net通过应用全局强度规范化方案global intensity normalization(相对于Supplementary Information 3.1中的ACDC,其中数据单独使用其均值和标准差进行标准化)。为此,nnU-Net提取强度信息作为数据集指纹dataset fingerprint的一部分:收集所有训练数据前景类(肝和肝肿瘤)的体素强度。然后,计算这些值的均值和标准差以及它们的0.5和99.5百分位,随后,所有图像通过裁剪到0.5和99.5百分位进行归一化,然后减去全局均值并除以全局标准差。
2D U-Net确定2D U-Net的目标间距target spacing为NAx0.77x0.77 mm,对应于训练数据中遇到的中位数体素间距median voxel spacing。注意,2D U-Net只在切片x、y上操作,所以离开平面轴z是不受影响的。重采样训练数据的结果是的NAx512x512体素中位数图像形状(我们用NA表示该轴不重采样)。因为这是中位数形状,所以训练集中的数据可以比它更小或更大。2D U-Net的输入补丁大小patch size为512x512体素,批量大小为batch size = 12。
3D U-Net确定3D U-Net的目标间距target spacing为1x0.77x0.77 mm,对应体素间距中位数。由于间距中位数几乎是各向同性的,nnU-Net不像ACDC那样使用离面轴的第10个百分位数(见Supplementary Information 3.1)。重采样策略是根据每张图像决定的。在各向同性的情况下(最大轴间距/最小轴间距< 3),对图像数据使用三阶样条插值,对分割使用线性插值。注意,分割图总是重采样前转换成one-hot的表示,插值后转换回原分割图表示。对于各向异性图像,nnU-Net像在ACDC中一样,分别对离面轴Z重采样。
重采样后的图像形状中值为482x512x512。nnU-Net优先考虑大补丁大小large patch而不是大的批处理大小batch size(注意,这些是在给定的GPU显存预算下耦合的),以捕获尽可能多的上下文信息。因此,3D U-Net被配置为有一个128x128x128体素块大小和一个批大小为2,这是根据nnU-Net启发式允许的最小值。由于输入patch的间距几乎是各向同性的,所以所有的卷积核大小和downsampling步幅都是各向同性的(分别是3x3x3和2x2x2)。
3D U-Net cascade虽然nnU-Net对大的输入patch进行优先排序,但3D full resolution U-Net的patch还是太小,无法捕捉到足够的上下文信息(重采样后只覆盖中值图像形状的1/60体素)。这可能会导致对体素的错误分类,因为这些patches太“zoomed in”了,使得spleen和liver之间的区别特别困难。3D U-Net cascade设计的目的是解决这个问题,首先对下采样数据训练一个3D U-Net,然后low-resolution分割的输出作为U-Net作为full resolution的输入。使用Online Methods 4中描述的过程如图SN5.1 b)所示,low resolution U-Net的目标间距确定为2.47x1.9x1.9 mm,产生的中位数图像形状195x207x207体素。3D low
resolution操作128x128x128补丁批量大小为2的。请注意,虽然此设置与此处的3D U-Net配置相同,但对于其他数据集却不一定如此。如果3D full resolution U-Net数据具有各向异性,nnU-Net会优先向下采样更高分辨率轴,可能会引起网络结构、补丁大小和批大小偏离。在对3D low resolution U-Net进行five-fold cross-validation,将各自验证集的分割图更新到3D full resolution U-Net的目标间距。完full resolution U-Net of the cascade(与常规的3D full resolution U-Net具有相同的配置)然后开始训练,以细化粗分割图并纠正其遇到的错误。将one hot编码的重采样分割作为网络的输入。
Training and postprocessing所有的网络配置都经过五倍交叉验证five fold cross-validation训练。nnU-Net再次通过计算所有前景类的平均Dice得分来评估所有配置,从而为每个配置提供一个标量metric度量。基于此评估方案,得分为0.7625为2D U-Net, 0.8044为3D full resolution U-Net, 0.7796为3D low resolution U-Net和0.8017full resolution 3D U-Net of the cascade。两种模型的最佳组合为low and full resolution U-Nets的组合,得分为0.8111。在这个集成ensemble的分割图上配置了后处理。除去除了最大的连通区域外的所有连通区域发现对联合前景区域(肝脏和肝脏肿瘤标记的结合)以及单独的肝脏标记都有好处,因为在训练数据上进行经验测试时,两者都有了小幅度的性能增益。
4 Details on nnU-Net’s data augmentation
在培训过程中应用了多种数据增强技术。所有的扩增都使用background workers在CPU上实时计算的。数据增强管道data augmentation pipeline是通过公公开的batchgenerators框架实现的,nnU-Net不改变数据集之间的数据扩增管道参数data augmentation pipeline。
样本的patch最初大于用于训练的patch大小。当应用旋转和缩放时,这就会使得在数据增强过程中引入较少的边界值(这里为0)。作为旋转和缩放增强的一部分,patch被中心裁剪到最终的目标patch大小。为了保证原始图像的边界出现在最终的patches中,最初的crop可以初始扩展到图像的边界之外。
空间增强(旋转、缩放、低分辨率模拟)应用于3D U-Nets的3D数据和应用于2D训练二维2D U-Net or a 3D U-Net的各向异性块大小patch size。如果一个patch size的最大边缘长度至少是最小边缘长度的三倍,则该patch的大小被认为是各向异性的,这里是size。
为了增加生成的补丁的可变性,大多数增强都是根据从预定义范围随机抽取的参数进行改变的。在这种情况下,x~U(a, b)表明x是从a和b之间的均匀分布中得出的。此外,所有的增广都是根据预先设定的概率随机应用的。
nnU-Net(按给定顺序)应用了以下扩展:
- Rotation and scaling.缩放和旋转同时应用,提高了计算速度。这种方法将所需的数据插值量减少到一个。缩放和旋转应用的概率都是0.2(结果是0.16概率仅用于缩放,0.16仅用于旋转,0.08都被触发)。如果处理各向同性的3D patches,旋转角度(以角度表示)ax,ay和az分别从U(-30,30)绘制。如果一个patch是各向异性的或2D的,旋转角度被采样
U(-180,180)。如果2D patch size大小是各向异性的,角度从U(-15,15)采样。缩放是通过将坐标与体素网格中的缩放因子相乘来实现的。因此,比例因子小于1会产生“缩小”效应,而数值大于1会产生“放大”效应。对于所有的补丁类型,缩放因子是服从U(0.7, 1.4)中采样的。 - Gaussian noise.零中心的加性高斯噪声独立地添加到样本中的每个体素。这个增广的应用概率是0.15。噪声的方差来自于U(0,0.1)(注意,由于强度归一化,所有样本中的体素强度都接近于零均值和单位方差)。
- Gaussian blur.模糊应用每个样本的概率为0.2。如果这个增强在一个样本中被触发,模糊应用的概率为每一个相关模态的0.5(使得单个模态样本的综合概率仅为0.1)。每个模态的高斯核的宽度σ(体素)“服从U(0.5, 1.5)独立采样。
- Brightness体素强度以0.15的概率乘以x~U(0.7, 1.3)。
- Contrast体素强度以0.15概率乘以x~U(0.65, 1.5)。在乘法之后,这些值被剪切到它们的原始值范围。
- Simulation of low resolution。这种增强应用于每个样本的概率为0.25,每个相关模态的概率为0.5。触发的模态通过使用最近邻插值以U(1,2)因子降采样,然后用三次插值采样回其原始大小。对于2D patches或各向异性的3Dpatch,这种增强仅在2D中应用,(如果有)保留原状态下出平面轴Z轴。
- Gamma augmentation.这个增广的应用概率是0.15。将patches强度按其各自取值范围[0,1]的倍数进行缩放。然后,每个体素应用非线性强度变换:i_new = i_old^γ with γ~U(0.7, 1.5)。体素强度随后被缩小到原始值范围。在概率为0.15的情况下,这种增强应用于在转换之前倒转体素强度:(1 -i_new) = (1- i_old)^γ。
- Mirroring。所有补丁在所有轴上都以0.5的概率镜像。
对于U-net cascade的full resolution U-Net, nnU-Net还对low resolution 3D U-net生成的分割掩码进行了以下增强。注意的是mask为one-hot形式。

Figure SN5.1: Workflow for network architecture configuration.a)给定输入patch大小和相应的体素间距的U-Net架构的配置。由于在GPU显存消耗(由于池操作次数和网络深度的变化),无法解析解决架构配置问题。b)3D low resolution U-Net of the U-Net cascade的配置,3D lowres U-Net的输入patch大小必须至少覆盖重采样的训练数据中值形状的1/4,以保证足够的上下文信息。更高分辨率的轴首先进行采样,会导致数据相对于全分辨率数据的可能有不同的纵横比aspect ratio。low resolution U-Net的网络结构可能与full resolution U-Net的网络结构不同,这是由于该宽高比下的补丁大小引起的。这需要在每次迭代中重新配置a)中描述的网络架构。所有的计算都是基于显存消耗的估计,计算时间都比较小(在配置所有网络架构时低于1s)。
- Binary operators在概率为0.4的情况下,一个二元运算符应用于预测掩码中的所有标签。从[dilation, erosion, opening, closing]中随机选择该操作符。结构单元为半径为r~U(1,8)的范围。操作被随机地应用到labels上。因此one-hot属性保留下来了。例如,一个标签的膨胀会导致膨胀区域内的所有其他标签被移除。
- Removal of connected components.在概率为0.2的情况下,小于补丁大小15%的连接组件将从一个one-hot中移除。
5 Network architecture configuration
图SN5.1为在线方法中描述的架构配置的迭代过程提供了可视化的帮助。
6 nnU-Net挑战赛参会总结
在本节中,作者提供所有挑战的细节。
在一些研究中,为了与nnU-Net兼容,需要对输入数据的格式或交叉验证数据划分进行人工干预。对于每个数据集,作者在本节中披露所有的人工干预。手动干预的最常见原因是相互关联的训练案例(例如同一患者的多个时间点),因此需要在数据划分间进行互斥分离。在源代码中还提供了如何执行这种干预的详细描述。
对于每个数据集,作者运行所有适用的nnU-Net配置(2D、3D fullres、3D lowres、3D cascade)在5倍交叉验证。所有的模型都是在没有预先训练的情况下从零开始训练,并且只根据挑战提供的训练数据进行训练,没有外部训练数据。请注意,其他参赛者可能会在一些比赛中使用外部数据。对于每个数据集,nnU-Net随后根据交叉验证和集成识别出理想的配置。最后,最好的配置用于预测测试用例。nnU-Net生成的管道为每个数据集提供以6.2节描述的紧凑表示形式。作者还提供了一个包含详细交叉验证和测试集结果的表。
所有排行榜最后一次访问是在2019年12月12日。
6.1 Challenge inclusion criteria
在选择参与挑战时,作者的目标是将nnU-Net应用于尽可能多的不同数据集,以展示其健壮性和灵活性。作者采用以下标准,以确保一个严格和健全的测试环境:
- 挑战的任务是在任何三维成像模式和任何大小的图像的语义分割。
- 为挑战赛参与者提供训练数据。
- 测试用例是独立的,挑战参与者无法获得ground truth
- 可以与其他参与者的结果进行比较(例如通过在线平台和公开排行榜进行标准化评估)。
以下列出的比赛是符合这些标准的,因此被选为nnU-Net的评估。据我们所知,CREMI 5是生物领域中唯一符合这些标准的竞争对手
6.2 Compact architecture representation
在下面几节中,nnU-Net生成的网络架构将以一种紧凑的表示形式呈现,它包含两个列表:一个是卷积内核大小,另一个是downsampling步数。正如作者在本节中所描述的,这种表示可以用来完全重建整个网络架构。选择压缩表示是为了防止数字过多。

Figure SN6.1: Decoding the architecture.作者提供所有生成的架构一个紧凑的表示,如果需要完全可以重建。这里显示的体系结构可以通过内核大小来表示[[1, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3]]、strides [[1, 2, 2], [2, 2, 2], [2, 2, 2], [1, 2, 2], [1, 2, 2]](见正文描述)
图6.2示例展示了ACDC数据集(D13)的3D full resolution U-Net。体系结构有6个解决阶段。编码器和解码器的每个分辨率阶段都由两个计算块block组成。每个块block是一个序列(conv - instance norm - leaky ReLU),如4中所述。在这个图中,一个这样的块用一个蓝色框框表示。在每个盒子box里,卷积的步数stride由前三个数字表示(最左上角的盒子是1,1,1),卷积的核大小size由第二组数字表示(最左上角的盒子是1,3,3)。使用这些信息,以及作者设计架构时使用的模板,我们可以用以下列表完整地描述所呈现的架构:
- Convolutional kernel sizes:该架构的内核大小为[[1,3,3],[3,3,3],[3, 3, 3],[3, 3, 3],[3, 3, 3],[3, 3, 3]]。注意,这个列表包含6个元素,与编码器中遇到的6种分辨率相匹配。这个列表中的每个元素都给出了该分辨率下卷积层的内核大小(这里是三个数字,因为卷积是三维的)。在一个分辨率中,两个块使用相同的内核大小。解码器中的卷积镜像了编码器(由于瓶颈blockneck,而删除列表中的最后一个条目)。
- Downsampling strides:向下采样的步数是[[1,2,2],[2,2,2],[2,2,2],[1,2, 2],[1,2, 2]]。编码器中的每个下采样步骤都用一个条目表示。一个步幅为2的结果是下采样因子2,步幅为1的轴向大小不变。注意,由于间距差异,步幅最初是[1,2,2]。这将初始间距5x1.56x1.56 mm更改为在第二个分辨率步骤间距5x3.12x3.12 mm。下采样步幅仅适用于编码器中每个分辨率阶段的第一次卷积。第二个卷积的步长总是[1, 1, - 1)。同样,解码器镜像了编码器,但步幅被用作反卷积convolution transposed后的输出步幅(导致特征图的适当升级)。所有卷积转置后的输出与来自编码器的skip连接具有相同的形状。
分割输出的辅助损失auxiliary losses被添加到除两个最低的分辨率步骤所有分辨率阶段。
6.3 Medical Segmentation Decathlon
Challenge summary Medical Segmentation Decathlon 6[1]是一项跨越10个不同细分任务的竞赛。选择这些任务是为了涵盖医学领域中数据集可变性的很大一部分。竞赛的主要目标是鼓励研究人员开发出不需要人工干预就能立即处理这些数据集的算法。每个任务都带有各自的训练和测试数据。数据集的详细描述可以在挑战主页上找到。最初,这个挑战分为两个阶段:在第I阶段,为算法开发的参与者提供了7个数据集。在阶段II,这些算法不进行任何改变,直接被应用到另外三个先前未见过的数据集。对这两个阶段分别进行挑战评估,根据他们在测试用例中的表现确定获胜者。
Initial version of nnU-Net nnU-Net的初步版本是作者参赛作品的一部分,在这两个阶段都取得了第一名(http://medicaldecathlon.com/results.html)。我们其后将各自有关的挑战报告载于arXiv[15] 。
nnU-Net已经使用Medical Segmentation Decathlon的全部十个任务进行了改进。nnU-Net的当前版本提出了改进版再次打榜(https://decathlon-10.grand-challenge.org/evaluation/results/),并取得第一等级优于初始nnU-Net以及其他方法,自原始比赛把优[16]。
Application of nnU-Net to the Medical Segmentation Decathlon nnU-Net在没有任何人工干预的情况下,应用于所有的10个任务的Medical Segmentation Decathlon
BrainTumour (D1)
Normalization:通过减去其均值并除以其标准偏差,每个图像都被独立归一化。

Table SN6.1:由nnU-Net为Medical Segmentation Decathlon (D1)的BrainTumour dataset生成的网络配置。有关如何解码downsampling大步和内核大小到架构的更多信息,请参见6.2。
Table SN6.2: Decathlon BrainTumour (D1) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是2D U-Net and the 3D full resolution U-Net组合
Heart (D2)
Normalization通过减去其均值并除以其标准偏差,每个图像都被独立归一化。
Table SN6.3: nnU-Net为Medical Segmentation Decathlon (D2)Heart dataset生成的网络配置。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.

Table SN6.4: Decathlon Heart (D2) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是2D U-Net and the 3D full resolution U-Net组合
Liver (D3)
Normalization裁剪到[-17,201],然后减去99.40,最后除以39.36。

Table SN6.5:nnU-Net为Medical Segmentation Decathlon (D3)Liver dataset生成的网络配置。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.6:Decathlon Liver(D3) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是3D low resolution U-Net and the 3D full resolution U-Net组合
Hippocampus (D4)
Normalization:通过减去其均值并除以其标准偏差,每个图像都被独立归一化
Table SN6.7:nnU-Net为Medical Segmentation Decathlon (D4)Hippocampus dataset生成的网络配置。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.8:Decathlon Hippocampus (D4) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是2D U-Net and the 3D full resolution U-Net组合.
Prostate (D5)
Normalization:通过减去其均值并除以其标准偏差,每个图像都被独立归一化。

Table SN6.9:nnU-Net为Medical Segmentation Decathlon (D5)Prostate dataset生成的网络配置。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.10:Decathlon Prostate (D5) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是2D U-Net and the 3D full resolution U-Net组合.
Lung (D6)
Normalization:裁剪到[-1024, 325],然后减去-158.58,最后除以324.70。
Table SN6.11:nnU-Net为Medical Segmentation Decathlon (D6)Lung dataset生成的网络配置。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.

Table SN6.12:Decathlon Lung (D6) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是3D low resolution U-Net and the 3D full resolution U-Net组合。
Pancreas (D7)
Normalization:裁剪到[-96.0, 215.0],然后减去-77.99,最后除以75.40。

Table SN6.13::nnU-Net为Medical Segmentation Decathlon (D7)Pancreas dataset生成的网络配置。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.

Table SN6.14:Decathlon Pancreas (D7) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是3D low resolution U-Net and the 3D full resolution U-Net cascade。
Hepatic Vessel (D8)
Normalization:裁剪到[-3, 243],然后减去104.37,最后除以52.62。

Table SN6.15:nnU-Net为Medical Segmentation Decathlon (D8)HepaticVessel dataset生成的网络配置。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.

Table SN6.16:Decathlon Hepatic Vessel (D8) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是3D low resolution U-Net and the 3D full resolution U-Net 组合。
Spleen (D9)
Normalization:裁剪到[-41, 176],然后减去99.29,最后除以39.47。
Table SN6.17:nnU-Net为Medical Segmentation Decathlon (D9)Spleen dataset生成的网络配置。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.

Table SN6.18:Decathlon Spleen (D9) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是3D U-Net cascade and the 3D full resolution U-Net。
Colon (D10)
Normalization:裁剪到[-30.0, 165.82],然后减去62.18,最后除以32.65。
Table SN6.19:nnU-Net为Medical Segmentation Decathlon (D10)Colon dataset生成的网络配置。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.

Table SN6.20:Decathlon Colon (D10) results.请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是3D U-Net cascade and the 3D full resolution U-Net。
6.4 Multi Atlas Labeling Beyond the Cranial Vault: Abdomen (D11)
Challenge summaryThe Multi Atlas Labeling Beyond the Cranial Vault - Abdomen Challenge(denoted BCV for brevity)包括30张用于训练的CT图像和20张用于测试的CT图像。分割目标是腹部的13个不同器官。
Application of nnU-Net to BCV nnU-Net应用于BCV挑战,无需任何人工干预
Normalization裁剪到[-958, 327],然后减去82.92,最后除以136.97。
Table SN6.21:nnU-Net为BCV挑战生成的网络配置(D11)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.22:Multi Atlas Labeling Beyond the Cranial Vault Abdomen (D11) results.所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是3D U-Net cascade and the 3D full resolution U-Net。
6.5 PROMISE12 (D12)
Challenge summary PROMISE12挑战[5]的分割目标是prostate in T2 MRI图像。提供50个带有前列腺注释的培训案例进行培训。有30个测试用例需要由挑战参与者进行划分,然后在一个在线平台上进行评估
Application of nnU-Net to PROMISE12 nnU-Net应用于PROMISE12挑战,没有任何人工干预
Normalization:通过减去其均值并除以其标准偏差,每个图像都被独立归一化。
Table SN6.23:nnU-Net为PROMISE12挑战生成的网络配置(D12)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.24: PROMISE12 (D12) results.所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的。我们的测试集提交的评价分数是89.6507。表中报告的测试集Dice得分是根据详细的提交结果计算的(详细结果可在这里获得https://promise12.grand-challenge.org/evaluation/results/89044a85-6c13-49f4-9742-dea65013e971/),该数据集的最佳集合是2D U-Net and the 3D full resolution U-Net的组合
6.6 The Automatic Cardiac Diagnosis Challenge (ACDC) (D13)
Challenge summary The Automatic Cardiac Diagnosis Challenge [6] (ACDC)包括100名训练病人和50名测试病人。目标结构是右心室腔、左心室心肌和左心室腔。所有图像均为cine MRI序列,其中心脏周期的舒张末期(ED)和收缩期(ES)时间点被分割。每个病人有两个时间实例,训练/测试图像的有效数量是200/100。
Application of nnU-Net to ACDC由于提供了同一患者的两个时间实例,我们手动修改模型的5倍交叉验证的划分,以确保拆分之间的患者互斥性。除此之外,nnU-Net的应用无需额外的人工干预。
Normalization:通过减去其均值并除以其标准偏差,每个图像都被独立归一化。
Table SN6.25:nnU-Net为ACDC挑战生成的网络配置(D13)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.26: ACDC results (D13).所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的。在线平台分别报告舒张末期和收缩期末期的Dice得分。我们取这些值的平均值,使其更简洁。该数据集的最佳集合是2D U-Net and the 3D full resolution U-Net的组合.
6.7 Liver and Liver Tumor Segmentation Challenge (LiTS) (D14)
Challenge summary The Liver and Liver Tumor Segmentation challenge [17] 为肝脏和肝脏肿瘤提供131张训练CT图像的ground truth注释。提供了70个没有注释的测试图像。测试用例使用LiTS在线平台9预测分割掩码进行评估
Application of nnU-Net to LiTSnnU-Net应用于光照挑战,没有任何人工干预
Normalization:裁剪到[-17,201],然后减去99.40,最后除以39.39。
Table SN6.27:nnU-Net为LiTS挑战生成的网络配置(D14)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.

Table SN6.28: LiTS results (D14).请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是3D low resolution U-Net and the 3D full resolution U-Net。
6.8 Longitudinal Multiple Sclerosis Lesion Segmentation Challenge (MSLesion) (D15)
Challenge summary The longitudinal multiple sclerosis lesion segmentation challenge [7]提供5个训练病人。对于每个患者,提供在不同时间点获得的4 - 5张图像(4患者4个时间点,1患者5个时间点,共21张图像)。每个时间点由两个不同的专家标注,结果产生42个训练标注(21张图片)。该测试集包含14名患者,每个患者都有几个时间点,共进行61次MRI检查。测试集预测使用在线平台10进行评估。每个训练和测试图像由四种MRI模式组成:MPRAGE, FLAIR, Proton Density, T2.
Application of nnU-Net to MSLesion 我们在交叉验证中手动干预划分,以确保flod患者之间的互斥性。每张图片都由两名不同的专家进行了注释。我们将这些标注作为单独的训练图像(同一患者的),结果得到的训练集大小为2x21 = 42。我们不使用扫描的纵向性质,在训练和推理过程中单独对待每幅图像
Normalization:通过减去其均值并除以其标准偏差,每个图像都被独立归一化。
Table SN6.29:nnU-Net为MSLesion挑战生成的网络配置(D15)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.30: MSLesion results (D15).请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的https://smart-stats-tools.org/sites/lesion_challenge/temp/top25/nnUNetV2_12032019_0903.csv。排名是基于分数的,也包括其他指标(详见[7])。我们提交的分数是92.874。在这个数据集上最好的集合是2D U-Net and the 3D full resolution U-Net。
6.9 Combined Healthy Abdominal Organ Segmentation (CHAOS) (D16)
Challenge summary CHAOS challenge[8]分为5个任务。这里我们着重于任务3 (MRI肝脏分割)和任务5 (MRI多器官分割)。任务1、2和4还包括使用CT图像,这是一种可以获得大量公共数据的方式(参见BCV和LiTS挑战)。为了隔离nnU-Net相对于其他参与者的算法性能,我们决定只使用不太可能受到外部数据污染的任务。任务5的目标结构是肝脏、脾脏和左右肾。CHAOS challenge提供了20个训练案例。对于每个训练案例,都有一个具有相应ground truth标注的T2图像,以及一个具有自己的单独ground truth标注的T1采集。T1的采集有两种共同注册的方式:T1 in-phase and T1 out-phase。Task 3是Task 5的一个子集,只有肝脏是分割目标。使用在线平台对20个测试用例进行评估。
Application of nnU-Net to CHAOS nnU-Net只支持具有固定数量的输入模式的图像。CHAOS的训练案例有1(T2)和2(T1 in & out phase)模态。为了确保与nnU-Net的兼容性,我们可以复制T2图像并使用两种输入模式进行训练,或者只使用一种输入模式并将T1 in phase and out phase作为单独的训练示例。也就是要么将T2复制一遍,一次训练两个模态,或者是将T1 in phase and out phase分开单独训练。我们选择后者,因为这种变体会产生更多(尽管高度相关)的训练图像。在提供20个训练病人的情况下,这种方法产生了60个训练图像。对于交叉验证,我们确保划分是在患者水平上进行的。在推理过程中,nnU-Net将为T1 in and out phase生成两个单独的预测,这些预测需要进行整合以评估测试集。我们通过简单地平均两者之间的softmax概率来实现这一点,以生成最终分割。我们只训练nnU-Net任务5。因为task 3代表task 5的一个子集,所以我们从task 5的预测中提取肝脏并将其提交给task 3。
Normalization:通过减去其均值并除以其标准偏差,每个图像都被独立归一化。
Table SN6.31:nnU-Net为CHAOS挑战生成的网络配置(D16)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.32: CHAOS results (D16).请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。对标记为*的模型进行后处理。该模型(包括后处理)用于测试集预测。注意,测试集的评估是通过挑战的在线平台进行的,该平台不报告单个器官的Dice得分。作者提交的Task 5的分数是72.44 Task3 75.10(详见[8])。在这个数据集上最好的集合是2D
U-Net and the 3D full resolution U-Net组合。
6.10 Kidney and Kidney Tumor Segmentation (KiTS) (D17)
Challenge summary The Kidney and Kidney Tumor Segmentation challenge是MICCAI 2019年最大的比赛(就参赛人数而言)。目标结构是肾脏和肾脏肿瘤。挑战组织者提供了210个训练和90个测试案例。组织者以其原始几何(体素间距在不同情况下变化)和插值到共同体素间距提供数据。数据重采样了。测试集预测结果在网络平台上进行评估。
作者使用手工设计的residual 3D U-Net.参加了最初的KiTS 2019 MICCAI挑战赛。该算法,在[19]中描述,获得了挑战中的第一名。对于这次提交,作者对原始的训练数据做了轻微的修改:数据15和37被挑战赛组织者(https://github.com/neheller/kits19/issues/21)确认为错误的,这就是为什么我们用我们其中一个网络的预测替换了它们各自的分割掩码。我们进一步排除了案例23、68、125和133,因为我们怀疑这些案例中的标签错误。在发布的测试数据中,挑战赛组织者没有提供修改过的分割掩码,这就是为什么我们重新使用修改过的训练数据集来训练nnU-Net。
在MICCAI 2019挑战赛之后,一个开放的排行榜诞生了。最初的挑战排行榜仍保留在http://results.kits-hallenge.org/miccai2019/。有提交的原始KiTS挑战都反映在开放排行榜上。本手稿是nnU-Net在开放排行榜上完成的,在那里有更多的竞争者已经进入挑战。如图3所示,nnU-Net在开放排行榜上设置了一个新的技术状态,因此也优于我们最初的手动优化解决方案。
Application of nnU-Net to KiTS 由于nnU-Net被设计为自动处理数据集中不同的体素间距,我们选择了组织者提供的原始的、非插值的图像数据,并让nnU-Net处理体素间距的同质化homogenization。nnU-Net应用于KiTS挑战,没有任何人工干预。
Normalization:裁剪到[-79,304],然后减去100.93,最后除以76.90
Table SN6.33:nnU-Net为KiTS挑战生成的网络配置(D17)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.

Table SN6.34: KiTS results (D17).所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。对标记为*的模型进行后处理。该模型(包括后处理)用于测试集预测。注意,测试集的Dice分数是通过计算基于肾脏和肿瘤标签的结合的肾脏Dice的在线平台计算出来的,而nnU-Net总是分别评估标签,导致表中kindey值缺失。平台报告的kindey Dice(与nnU-Net计算的值不可比较)为0.9793。在该数据集上,最好的集合是3D U-Net cascade and the 3D full resolution U-Net 的组合。
6.11 Segmentation of THoracic Organs at Risk in CT images (SegTHOR) (D18)
Challenge summary In the Segmentation of THoracic Organs at Risk in CT images [10] challenge,在CT中对腹部四个器官(心脏、主动脉、气管和食道)进行分割。提供40张训练图像用于训练,另外提供20张图像用于测试。测试图像的评估是通过在线平台完成的。
Application of nnU-Net to SegTHOR nnU-Net在没有任何人工干预的情况下应用于SegTHOR挑战。
Normalization:裁剪到[-986,271],然后减去20.78,最后除以180.50。
 Table SN6.35:nnU-Net为SegTHOR挑战生成的网络配置(D18)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.35:nnU-Net为SegTHOR挑战生成的网络配置(D18)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.

Table SN6.36: SegTHOR results (D18).请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),测试集的Dice是通过在线平台计算的,只报告两个有效数字。在这个数据集上最好的集合是3D U-Net cascade and the 3D full resolution U-Net。
6.12 Challenge on Circuit Reconstruction from Electron Microscopy Images (CREMI)(D19)
Challenge summary The Challenge on Circuit Reconstruction from Electron Microscopy Images被细分为三个任务。突触间隙分割任务可以被定义为语义分割(与实例分割相对),因此与nnU-Net兼容。在这个任务中,分割的目标是细胞形成突触的细胞膜位置。该数据集包括Transmission Electron Microscopy scans of the Drosophila melanogaster大脑的连续切片。三volumes训练用,另外三volume测试用。测试集的评估是利用在线平台完成的。
Application of nnU-Net to CREMI 由于训练图像的数量低于分割的数量,我们不能运行5倍交叉验证。因此,作者训练了5个模型实例,每一个都在所有三个训练volume上,然后集成这些模型用于测试集预测。由于该训练方案没有留下验证数据,因此在交叉验证后,nnU-Net所执行的三种模型配置中选择最好的是不可能的。因此,只通过配置和训练3D full resolution configuration配置进行干预。
Normalization:通过减去其均值并除以其标准偏差,每个图像都被独立归一化。
Table SN6.37:nnU-Net为CREMI挑战生成的网络配置(D19)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Results 由于我们针对这个挑战的培训方案没有留下验证数据,所以对于CREMI来说,给出的其他数据存储的性能评估是不可用的。通过在线平台对CREMI测试集进行了评估。评估指标是所谓的CREMI评分,其描述可以在https://cremi.org/metrics/中找到。不报告测试集的骰子得分。我们的测试集提交的CREMI分数为74.96(越低越好)
6.13 Cell Tracking Challenge
Challenge summary cell tracking challenge [12, 13] (http://celltrackingchallenge.net/3d-datasets/)被细分为两个基准:细胞分割和细胞跟踪基准。它总共包含9个2D+t和10个3D+t数据集,每个数据集显示了通过显微成像技术获得的不同类型的细胞或细胞核。由于每个数据集都是独立评估的,团队通常只参与所有可用数据集的一部分。
该挑战使用两个不同的分数,DET和SEG来评估提交的细胞分割基准。分数的详细描述在这里提供:https://public.celltrackingchallenge.net/documents/SEG.pdf 。细胞分割基准的排名是基于OPCSB的,它是DET和SEG的平均值(另见http://celltrackingchallenge.net/evaluation-methodology/)
下面我们将介绍我们参与的细胞追踪挑战。为了理解我们在这个挑战中选择的数据集,我们应该注意到nnU-Net没有设计用来训练没有注释的数据的绝大多数切片(或对象)。虽然这可以在未来的工作中解决(例如在[20]中),作者不希望修改nnU-Net以保持算法在整个手稿一致。
cell tracking挑战的参考标注说明如下:“对于每个3D帧,我们也随机选择至少一个包含一些对象的2D z-slicer”(https://public.celltrackingchallenge.net/documents/Annotation%20procedure.pdf)。竞赛中绝大多数的3D数据集只在3D volume的少数2D切片上提供(可能不完整)参考标注,因此缺乏密集的参考标注,这些标签可以用来训练nnU-Net。然而,有两个模拟3D数据集(Fluo-C3DH-A549-SIM和Fluo-N3DH-SIM)和一个真实3D数据集(Fluo-C3DHA549,单个时间步在该数据集上被密集标注,而不是稀疏的2D切片),有合适的参考标注。
尽管nnU-Net最初是为解决3D分割和与之相关的方法配置的困难而开发的,但在我们的实验中也证明它可以成功地应用于
包括Fluo-N2DH-SIM在内数据集。
Instance segmentation with nnU-Net Fluo-N2DH-SIM+和Fluo-N3DH-SIM+需要细胞核的实例分割。然而,nnU-Net是为语义分割而开发的。为了缩小这一差距,我们在应用nnU-Net之前,将提供的实例级分割转换为语义分割映射。这是通过将每个nucleus实例转换为两个语义标签来实现的:center和border。因此,转换后的参考分割在这些数据集包含语义类'背景','核中心'和'核边界'。
应用nnU-Net后,通过对center类的连通分析,将测试用例的预测语义分割转换为实例分割,然后迭代扩展到边界区域,直到所有边界像素都被分配一个cell实例。为了正确地为进入或退出帧的单元分配实例标签,我们也要识别孤立的“nucleus
border”组件,并为它们分配一个唯一的实例ID。
Fluo-N2DH-SIM+ (D20)
Dataset summary Fluo-N2DH-SIM+数据集[21]模拟了HL60细胞的分裂行为。在模拟中,用Hoescht染色,用荧光显微镜获得细胞核。训练案例被细分为两个时间序列的图像,分别为65和150个训练图像。分割任务是对细胞核cell nuclei进行实例分割
Application of nnU-Net to Fluo-N2DH-SIM+为了使nnU-Net应用于该数据集,我们将提供的核实例分割转化为语义分割问题
(如上所述)在应用nnU-Net之前。我们将边框厚度border thickness设置为0.7微米。
我们通过将感兴趣的框架前面的四个时间步骤连接到其输入,使nnU-Net能够使用时间序列信息。这是利用它们作为额外的投入方式来执行的,因此不需要对nnU-Net作任何改变。
由于缺乏足够多样化的训练数据(只有两个单独的时间序列),我们不运行交叉验证,而是对所有训练案例训练单个模型。
Normalization 通过减去其均值并除以其标准偏差,每个图像都被独立归一化。
Table SN6.38:nnU-Net为Fluo-N2DH-SIM+ 细胞追踪挑战生成的网络配置(D20)。注意,这是一个2D数据集。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Results 由于缺乏足够多样化的数据来进行交叉验证,作者对所有训练数据对nnU-Nets 2D配置中的单个U-Net进行了训练。因此,不能配置后处理,也不能对训练案例进行性能评估。作者使用这个单一的模型来预测测试用例。作者的预测,以及生成这些预测的代码,都被上传到挑战赛组织者那里进行了评估。这个排行榜是http://celltrackingchallenge.net/latest-csb-results/。我们的DET分数为0.978(第4位),SEG评分0.832(第1位),综合OPCBS评分0.905(第1位)。详细的结果以及用于生成它们的软件(nnU-Net、模型参数和胶水代码)可以在这里访问http://celltrackingchallenge.net/participants/DKFZ-GE/#
Fluo-N3DH-SIM+ (D21)
Dataset summary The Fluo-N3DH-SIM+ dataset[21]模拟HL60细胞的分裂行为。在模拟中,用Hoescht染色,用荧光显微镜获得细胞核。训练案例被细分为两个时间序列的图像,分别为150和80个训练图像。分割任务是对细胞核进行实例分割。
Application of nnU-Net to Fluo-N2DH-SIM+为了使nnU-Net应用于该数据集,我们将提供的核实例分割转化为语义分割问题
(如上所述)在应用nnU-Net之前。作者设置边框厚度为0.5微米。作者不会利用时间信息,独立地处理每一帧。
由于缺乏足够多样化的训练数据(只有两个单独的时间序列),我们不运行交叉验证,而是对所有训练案例训练单个模型。手动选择3D full resolution U-Net (2D是唯一的其他选项)
Normalization 通过减去其均值并除以其标准偏差,每个图像都被独立归一化。

Table SN6.39:nnU-Net为Fluo-N3DH-SIM+细胞追踪挑战生成的网络配置(D21)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Results 于缺乏足够多样化的数据来进行交叉验证,我们对nnU-Net的3D full resolution配置中的单个U-Net进行了所有训练数据的训练。因此,不能配置后处理,也不能对训练案例进行性能评估。我们使用这个单一的模型来预测测试用例。作者的预测,以及生成这些预测的代码,都被上传到挑战赛组织者那里进行了评估,排行榜可以在这里找到http://celltrackingchallenge.net/latest-csb-results/我们的DET分数为0.992(1级),SEG评分为0.906(1级),综合OPCBS评分为0.949(1级)。详细的结果以及用于生成它们的软件(nnU-Net、模型参数和胶水代码)可以在这里访问http://celltrackingchallenge.net/participants/DKFZ-GE/#
Fluo-C3DH-A549 and Fluo-C3DH-A549-SIM+ (D22 & D23)
Dataset summary Fluo-C3DH-A549[22]显示GFP-actin-stained A549肺癌细胞在基质凝胶基质中。Fluo-C3DH-A549-SIM+[23]是显示相同细胞类型的模拟数据集。每个数据集都有两个时间序列。Fluo-C3DH-A549序列包含15张图像和15张手动标注。Fluo-C3DH-A549-SIM+序列由于其模拟性质充分标注(30+30)。在这些数据集中的分割任务是对其图像中的单个细胞进行语义分割。由于数据集具有很强的相似性,我们将它们合并在一起,得到一个大数据集,我们称之为Fluo-C3DH-A549(-SIM+)。联合数据集有4个时间序列,共90幅标注训练图像
Application of nnU-Net to Fluo-C3DH-A549(-SIM+) 我们不会利用时间信息,独立地处理每一帧。
我们手动选择nnU-Net’s 3D full resolution配置,训练四个U-Net模型。每个模型在四个可用时间序列中的三个上进行训练。没有对nnU-Net进行进一步的修改。
Normalization 通过减去其均值并除以其标准偏差,每个图像都被独立归一化。

Table SN6.40:nnU-Net为Fluo-C3DH-A549(-SIM+)挑战生成的网络配置(D22&D23)。有关如何解码downsampling strides和内核大小kernel sizes到架构的更多信息,请参见6.2.
Table SN6.41: Fluo-C3DH-A549(-SIM+) results (D22 & D23).请注意,所有报告的Dice(除了测试集)都是在训练用例上使用五折交叉验证计算的。*标记为后续选择的最佳性能模型后处理(见“Postprocessed”)和测试集提交(见“Test set”),注意,我们将Fluo-C3DH-A549和Fluo-C3DH-A549- sim +数据集合并用于我们的训练(从而实现四折交叉验证)但是这些数据集是独立评估的。Fluo-C3DH-A549的DET得分为1,SEG得分为0.908(排名1),综合得分为OPCBS得分为0.954(排名1)。Fluo-C3DH-A549(-SIM)的DET得分为1分,SEG得分为0.955(第1位),综合OPCBS得分为0.977(第1位)。注意,这些数据集中的DET分数没有提供信息,因为图像中只有一个单元格。详细的结果以及用于生成它们的软件(nnU-Net、模型参数和胶水代码)可以在这里访问http://celltrackingchallenge.net/participants/DKFZ-GE/
7 Description of all leaderboard submissions
当开发机器学习方法时,使用独立的测试集是基本的,以确保客观和令人信服的报告其性能。正因为如此,我们决定仅在国际细分竞争的背景下评估nnU-Net。在这个过程中,为了防止过拟合,将测试集(在nnU-Net中也包括测试数据集)从开发集中分离出来是非常重要的。正如作者在手稿中所述,nnU-Net的开发仅仅是通过对医学分割十项全能Medical Segmentation Decathlon
[1]提供的10个数据集进行5倍交叉验证five-fold cross-validations(或train-val划分)来进行的。理想情况下,这个过程应该导致提交单个测试集。然而,当检查一些排行榜时,你可以发现多个提交可以与我们的研究小组相关联。由于这可能会引起人们对nnU-Net测试的独立性的关注,作者想澄清每一个条目的目的和性质。
nnU-Net经历了一个漫长的发展过程,主要有三个里程碑:
- 2018年9月:nnU-Net的第一个测试版是作者参与医疗细分十项全能Medical Segmentation Decathlon(http://medicaldecathlon.com/)挑战的一部分。作者的挑战参与描述在这个预印本:[15]。源代码尚未发布。
- 2019年4月:nnU-Net的第一个开源版本以及更新的预印本([24])。这个版本仍然可以在作者的代码存储库中使用,并且可以通过选择nnUNetTrainer训练器类来进行选择(而不是默认的nnUNetTrainerV2)。
- 2020年4月:本手稿所描述的最新版本的期刊提交,以及预印本([25])的更新。
作者想再次强调,在nnU-Net开发的所有时间里,即寻找适当的固定参数和启发式规则,完全是在医学分割十项全能Medical Segmentation Decathlon提供的十个数据集的训练集上使用交叉验证(或单个train-val 划分)来完成的。nnU-Net版本之间的所有改进都只在这些数据集中找到并验证。只有在发布新版本时,nnU-Net才被应用于其他挑战。这是支持相应预印本提出的要求的必要步骤。
作为一个在设计分割方法上有多年经验的研究小组,自然也有其他的分割项目需要对几个孤立的比赛进行测试集评估,例如[26,19,27]
在下面,作者提出了一个详尽的清单,所有提交的挑战使用在这个手稿。
Medical Segmentation Decathlon (D1-D10) [1]
请注意,Medical Segmentation Decathlon的排行榜被划分为原始挑战排行榜和开放排行榜。原始排行榜的结果并没有移植到开放排行榜上,所以我们需要同时查看两个排行榜才能获得完整的结果。
- 2018。作者参与了nnU-Net的初始beta版本的Medical Segmentation Decathlon挑战(第一个里程碑)。这个条目只在最初的挑战排行榜上可见。
- December 2019。评估nnU-Net的最终版本为这个手稿(第三个里程碑)。此条目仅在开放的排行榜中可见。
Multi Atlas Labeling Beyond the Cranial Vault: Abdomen (D11) [4]
排行榜可在以下网址浏览https://www.synapse.org/#!Synapse:syn3193805/wiki/217785.
- March 2019.上传的标题’submitted_ensemble_3d_fullres_cascade_and_3d_fullres.zip’.对nnU-Net开源版本的评估(第二个里程碑)
- March 2019。上传的标题’submit_proper_names’。同上(分数相同)。我们这边有用户错误。
- March 2019.上传的标题’submit_proper_names’。同上(分数相同)。我们这边有用户错误。
- December 2019.上传的标题’ready_for_submission’。打算作为评估这个手稿,但有一个错误,在推理代码需要修复(见下文)。
- December 2019.上传的标题’submission_bugfixed’。篇手稿的最终评估(修正了bug)。nnU-Net在两次提交之间没有改变,除了这个bug修复
PROMISE12 (D12)
排行榜可在以下网址浏览https://promise12.grand-challenge.org/evaluation/leaderboard/
- August 2018.上传的标题’ ’(empty)。初始nnU-Net的应用(第一个里程碑)。
- March 2019.上传的标题’ nnUNet final, trained only on Promise dataset’。对nnU-Net开源版本的评估(第二个里程碑)。
- December 2019。上传的标题‘nnU-Net v2’,nnU-Net最终版本的评估(第三个里程碑)
- December 2019.上传的标题‘nnU-Net v2’与上面一样(由相同的分数来证明),我们这边的用户错误
Automatic Cardiac Diagnosis Challenge (ACDC) (D13) [6]
排行榜可在以下网址浏览https://acdc.creatis.insa-lyon.fr/#phase/59db86a96a3c7706f64dbfed 注意,积分排行榜只显示最后一个条目,而不提供关于下面描述的多个条目的信息
- 2017。我们的参赛作品在这里描述[26],与nnU-Net无关。
- March 2019.对nnU-Net开源版本的评估(第二个里程碑)。
- December 2019.nnU-Net最终版本的评估(第三个里程碑)
Liver and Liver Tumor Segmentation Challenge (LiTS) (D14) [17]
排行榜可在以下网址浏览https://competitions.codalab.org/competitions/17094#results 注意,积分排行榜只显示了我们的一个条目(' FabianIsensee '),这是不正确的:
- March 2019.对nnU-Net开源版本的评估(第二个里程碑)。
- December 2019. nnU-Net最终版本的评估(第三个里程碑)
Longitudinal multiple sclerosis lesion segmentation challenge (MSLesion) (D15) [7]
排行榜可在以下网址浏览https://smart-stats-tools.org/lesion-challenge.
- February 2019.与作者研究小组([27])的另一份出版物有关。
- March 2019.对nnU-Net开源版本的评估(第二个里程碑)
- December 2019。nnU-Net最终版本的评估(第三个里程碑)
Combined Healthy Abdominal Organ Segmentation (CHAOS) (D16) [8]
排行榜可在以下网址浏览https://chaos.grand-challenge.org/evaluation/leaderboard/ 注意,我们只参与了Task3和Task5。通过点击“show all metrics”按钮可以获得这些任务的分数
- Sept 2019.我们得到了挑战组织者Emre Kavur的联系,他鼓励我们参加比赛(并在相应的挑战总结[8]中列出)。这个提交主要基于nnU-Net的最终版本,但是包含了一些对管道配置(目标间距)的手动修改,因此不能被重用来评估nnU-Net的真正开箱即用的性能。
- December 2019 nnU-Net最终版本的评估(第三个里程碑)
Kidney and Kidney Tumor Segmentation (KiTS) (D17) [18, 26]
MICCAI比赛的结果可以在以下网站查看http://results.kits-challenge.org/miccai2019/,开放排行榜可在https://kits19.grand-challenge.org/evaluation/leaderboard/ 看到。最初挑战的所有结果都被复制到开放排行榜上。因此,开放式排行榜提供了所有挑战条目的完整画面。
- July 2019 我们在KiTS竞赛中获得了MICCAI排行榜第一名的参赛作品在[19]中有描述。这个提交的部分是基于nnU-Net的前一个版本实现的,但是作者提交的剩余的U-Net架构与作为这个手稿的一部分生成的配置几乎没有相似之处。
- December 2019 nnU-Net最终版本的评估(第三个里程碑)
Segmentation of THoracic Organs at Risk in CT images (SegTHOR) (D18) [10]
排行榜可在以下网址浏览https://competitions.codalab.org/competitions/21145#results
- December 2019。评估nnU-Net的最终版本为这个手稿(第三个里程碑)。注意,评估平台声称有三个条目。我们想要强调的是,该平台也计算失败的提交(错误的文件名,没有给出关于性能的反馈),给人错误的印象,多次成功提交。
Challenge on Circuit Reconstruction from Electron Microscopy Images (CREMI)(D19)
排行榜可在以下网址浏览https://cremi.org/leaderboard/
- December 2019 nnU-Net最终版本的评估(第三个里程碑)
Cell Tracking Challenge (D20-D23) [12, 13]
排行榜可在以下网址浏览http://celltrackingchallenge.net/latest-csb-results/。请注意,作者提交的标识符是由组织者分配的,因此与其他比赛不同:“DKFZ-GE”。每个团队提交的作品可以通过点击中的团队“参与者与算法”标识符来访问http://celltrackingchallenge.net/participants/
- July 2020 nnU-Net最终版本的评估(第三个里程碑)
8 Ablation studies of nnU-Net’s architecture template
网络模板中的一些设计选择可以被认为是非标准的。我们以与nnU-Net框架比较不同方法的相同方式来评估这些设计选择。这允许我们只集成一次更改,并将它们应用于任意数量的数据集。按照同样用于生成图6的方法,我们展示了在10 Decathlon数据集上运行五倍交叉验证的结果。从图中可以看出,ReLU和leaky 的ReLU非线性在性能上没有明显的差别。然而,当用三线性上采样trilinear upsampling代替译码器中的卷积转置convolution transpose和去掉辅助损耗层auxiliary loss时,性能会下降

图SN8.1: nnU-Net体系结构模板消融研究。我们配置和训练3D full resolution U-Net配置的10个Decathlon数据集具有不同的架构模板变化。演示如下图6所示:对于每个数据集,我们运行五倍交叉验证。通过引导生成1000个虚拟验证数据集。在每个虚拟验证集上对算法进行排名,从而产生一个高于排名的分布。结果表明,用常规的ReLU非线性代替默认的leaky ReLUs非线性并不会对性能产生不利影响。用三线性上采样trilinear upsampling代替反卷积convolution transposed,并去除辅助损失auxiliary losses(“深度监督 deep supervision”),会导致性能略有下降。
9 Using nnU-Net with limited compute resources
降低计算复杂度是驱动nnU-Net设计的关键动力之一。对大多数用户和研究人员来说,运行nnU-Net生成的所有配置的工作应该是可以管理的。对大多数用户和研究人员来说,运行nnU-Net生成的所有配置的工作应该是可以管理的。
9.1 Reducing the number of network trainings
根据给定数据集是否配置了3D U-Net cascade,nnU-Net需要10 (2D和3D U-Net各5个模型)或20个(2d, 3D, 3D cascade(低分辨率和高分辨率)每个有5个模型)U-Net训练需要运行,单个GPU训练需要几天的时间。虽然这种方法保证了最好的性能,但如果只有一个GPU可用,训练所有模型可能会超过合理的计算时间。因此,我们提出了两种降低nnU-Net运行时总网络训练次数的策略。
Manual selection of U-Net configurations
总体而言,3D full resolution U-Net分割效果最好。因此,该配置是一个很好的起点,可以简单地选择为默认选项。用户可以决定是否使用所有的训练用例来训练这个配置(来训练一个单一的模型),或者运行一个五倍交叉验证,并为测试用例预测集成5个结果模型。
在某些场景下,除3D full resolution U-Net外的其他配置可以获得最佳性能。然而,识别这样的场景并选择各自最有前途的配置,需要具备手头数据集的领域知识。具有高度各向异性图像的数据集例如,D12 PROMISE12可能最适合运行2D U-Net。然而,这种关系并不保证有效(参见D13 ACDC)。对于有非常大的图像的数据集,3D full resolution U-Net似乎略优于3D全分辨率U-Net(例如D11,D14, D17, D18,…),因为它改进了上下文信息的捕获。注意,只有当目标结构需要一个大的接受野以获得最佳识别时,这才成立。以CREMI (D19)为例,尽管图像尺寸较大,但只需要有限的视野,因为目标结构是相对较小的突触,仅用局部信息即可识别,这就是我们为本数据集选择3D full resolution U-Net的原因(见6.12节)。
Not running all configurations as 5-fold cross-validation
另一个计算捷径是不以5倍交叉验证的方式运行所有模型。例如,只有一个划分为每个配置可以运行(但是请注意,3D low resolution U-Net of the cascade 需要运行的5倍交叉验证为了产生低分辨率分割图,并作为second full resolution U-net of the cascade的训练输入)。即使在运行多个配置nnU-Net依靠经验选择配置,如果没有级联配置这降低了模型训练的总数2。或级联配置降低8(级联要求6个模型培训:5个3D low resolution U-Nets和1个full resolution 3D U-Net training)。nnU-Net随后根据这个单独的train-val分割来选择最佳配置。注意,这种策略提供的性能估计不太可靠,可能导致次优配置选择。最后,用户可以决定是否要在整个训练数据上重新训练选定的配置,或者为选定的配置运行五倍交叉验证。后者预计会产生更好的测试集性能,因为这5个模型可以作为一个整体使用。
9.2 Reduction of GPU memory
nnU-Net配置为使用11GB GPU内存。根据我们的经验,这是对具有深度学习能力的现代GPU(如Nvidia GTX 1080 ti)的现实需求(11GB)、Nvidia RTX 2080 ti (11GB)、Nvidia TitanX(p) (12GB)、Nvidia P100 (12/ 16gb)、Nvidia Titan RTX (24GB), Nvidia V100 (16/ 32gb),…)。作者强烈建议使用nnU-Net这种默认配置,因为它已经经过了广泛的测试,并且,正如作者在本文中显示的,提供了优秀的分割精度。如果用户仍然希望在较小的GPU上运行nnU-Net,用于网络配置的GPU内存数量可以很容易地调整。与源代码一起提供了相应的说明。














 2075
2075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









