






来源 | 新智源 ID | AI-era
ICLR 2024审稿结果公布了!
ICLR是机器学习领域重要的学术会议之一,每年举办一次。2024年是第十二届,将在奥地利维也纳5月7日-11日召开。
根据OpenReview官方放出的结果显示,今年共有7135篇投稿论文。

此外,另有国内开发者魏国强自己爬虫做了完整的统计数据,论文投稿有7215篇,平均分为4.88。
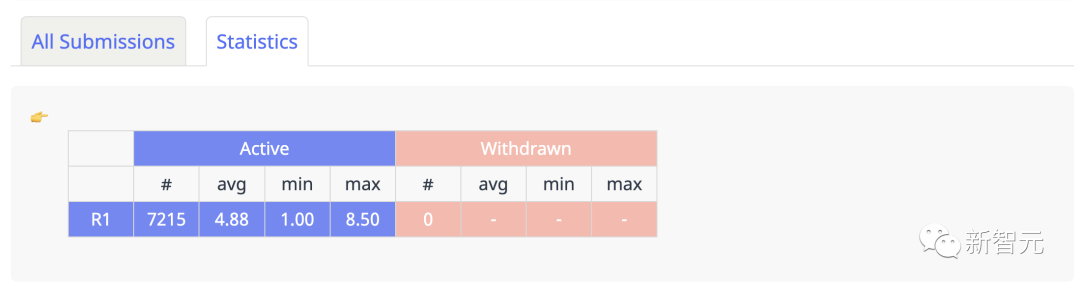
https://guoqiangwei.xyz/iclr2024_stats/iclr2024_submissions.html
就具体分数分布情况来看,均分为4.2分的论文有1086篇,4.9分1163篇,5.7分1015篇,这些都是1000篇+的论文的得分。
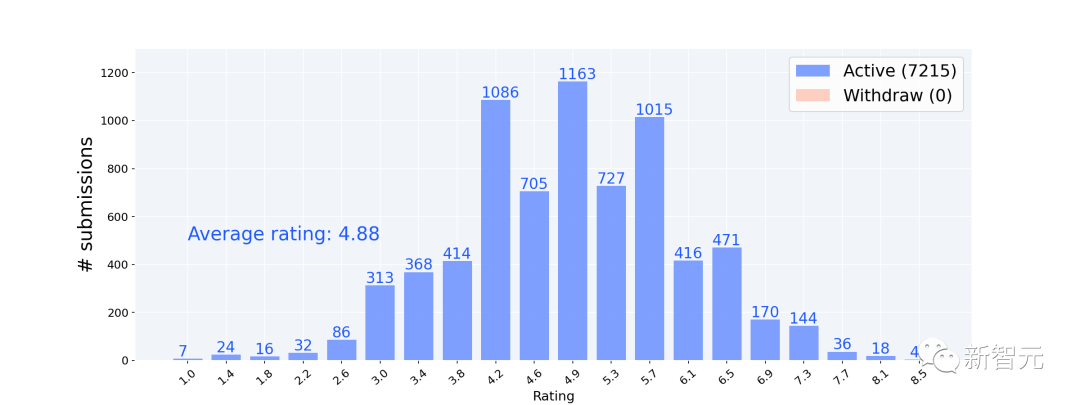
亚马逊工程师统计有7304篇提交的论文,平均分为4.9。

具体占比,均分为4.9-5.0,5.2-5.3论文数分别占总数的9%。
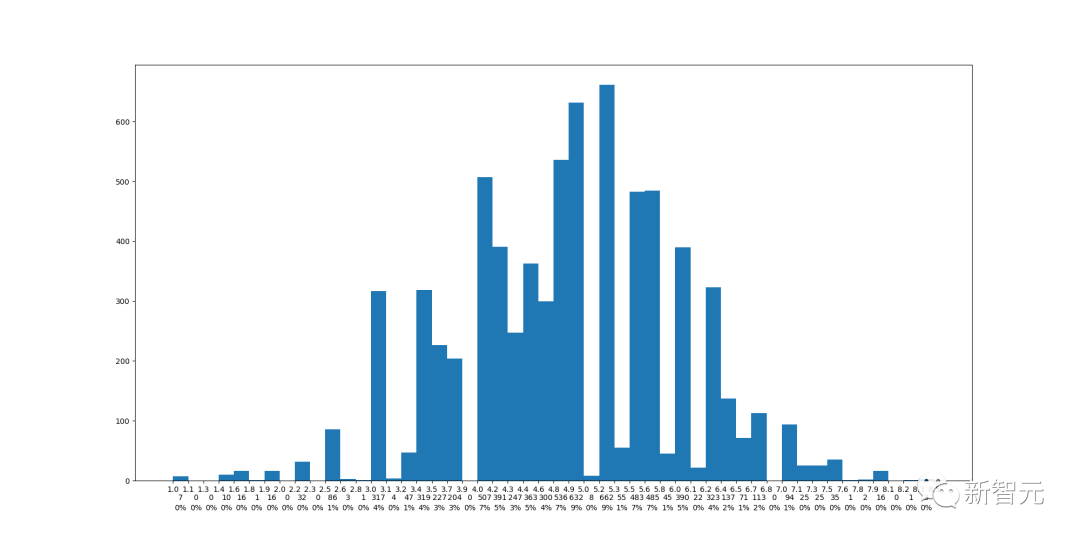
https://github.com/maxxu05/openreview_summarizereviews/tree/main
论文投稿暴涨7000+,创历史新高
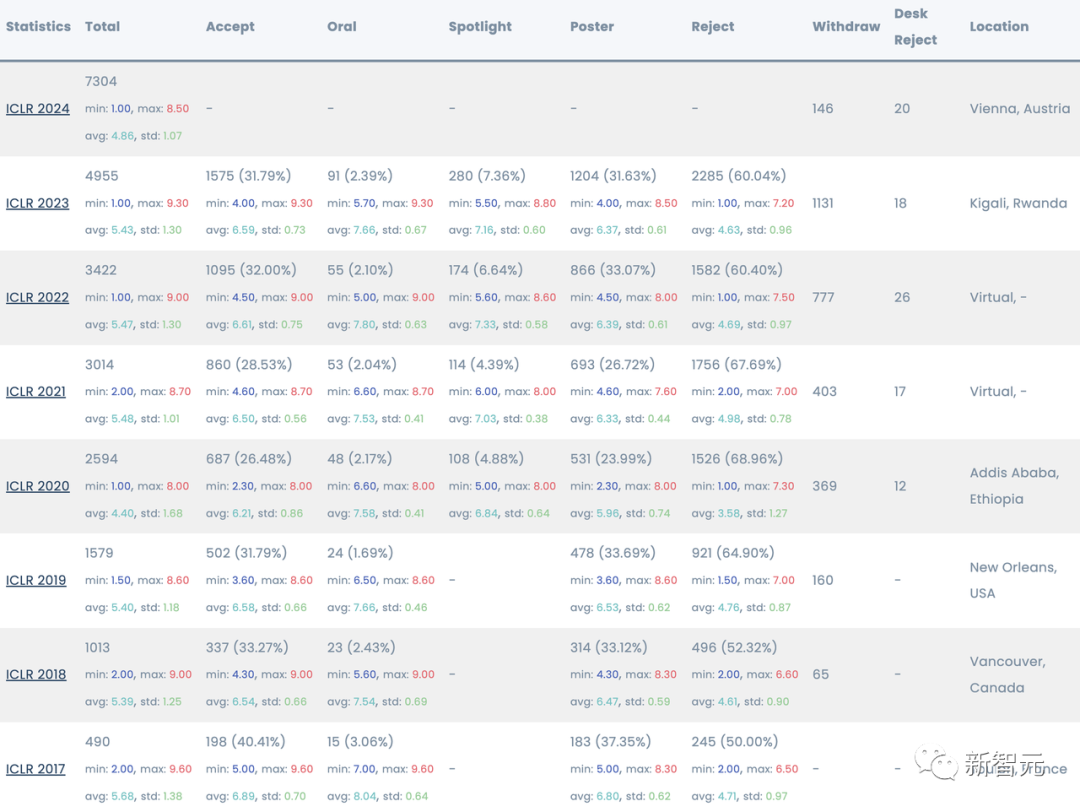
最值得一提的是,不管具体投稿数字是多少,ICLR 2024总论文提交创下历史新高。
这种巨大反差,可以从历年的统计数据中可以看出。
ICLR 2017那时仅有490篇,一直到ICLR 2023涨到4955篇。ICLR 24更是增长了2000+篇。
最近两年接收率都在30%以上,今年也不会低。
论文提交数量空前爆发,离不开ChatGPT做出的巨大贡献。
上周,arXiv平台公布了10月份该平台论文提交总数,仅仅一个月就有20,710篇,也创下了最新记录。
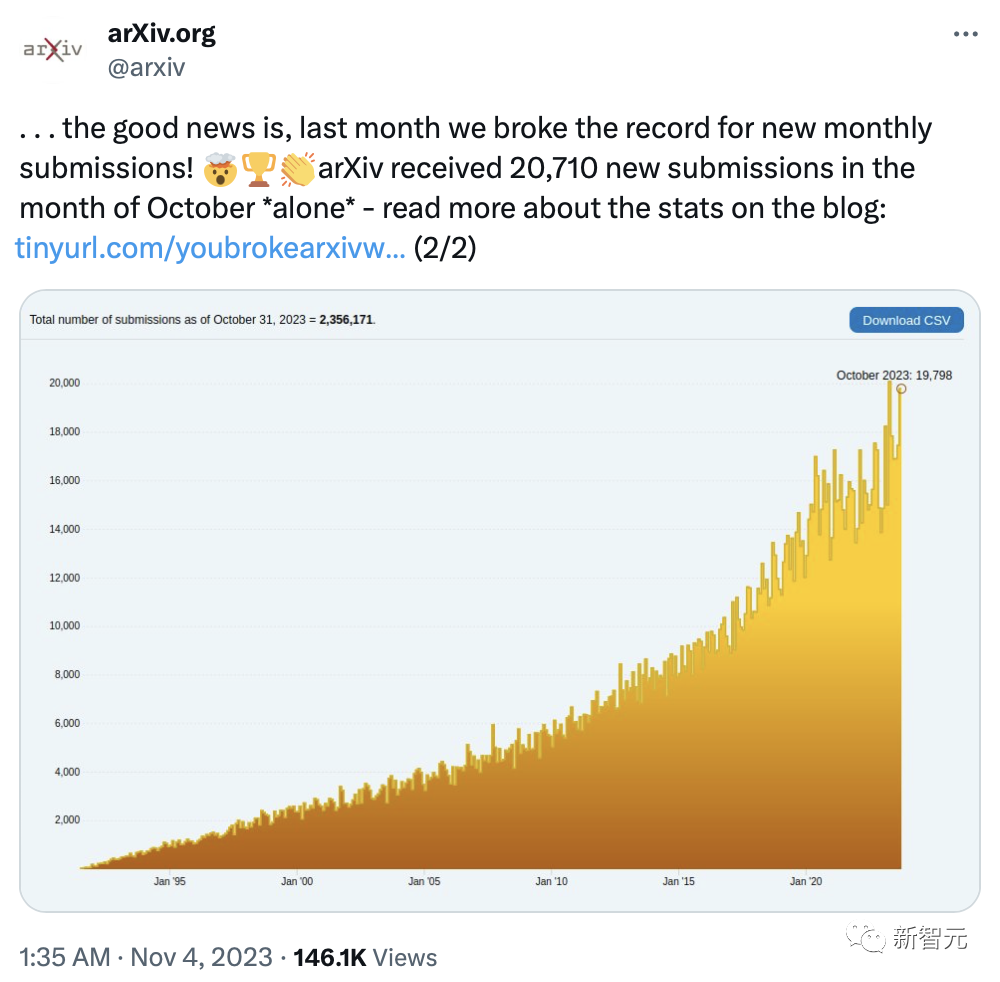
其中,大约一半的论文关于CS领域,3500预印与CV、ML领域有关。

平均一下,每天有668论文上传,这个数据确实有点离谱。


ICLR 2024研究领域,扩散模型占比最多
那么,ICLR 2024提交论文的主题都涉及了哪些领域,也有网友做出了总结。
- 451个标题包含「Diffusion」
- 208个标题包含「LLM」
- 6个标题包含「ChatGPT」
- 25个标题包含「NeRF」
- 41个标题包含「GAN」
- 15个标题包含「All you need」
- 22个标题包含「Dream」
- 6个标题包含「Magic」
高分论文
第一篇Generalization in diffusion models arises from geometry-adaptive harmonic representation是关于扩散模型的研究,评分为8,8,10,8。
当前,基于分数的反向扩散算法,能够生成高质量的样本,这一发现表明经过去噪训练的深度神经网络(DNN)可以学习数据密度分布,尽管存在维数灾难(curse of dimensionality)。
但是,最近有许多讨论关于,模型只是简单地记忆了训练数据,并没有真正意义上学习到数据的本质分布。
对此,研究人员训练了两个在不同数据子集上训练去噪DNN模型,结果发现它们得分函数和密度分布非常接近,而且训练图像数据量惊人地少。
这种强大的泛化能力证明了,DNN架构和训练算法中存在强大的归纳偏置(Inductive bias)。
研究人员进一步分析了这种归纳偏置存在的原因,证明去噪模型在适应底层图像的基础上执行收缩操作。
即使在一些不适合这种基础的图像数据上训练,模型也还是会学习到这种谐波表示。因此可以证明去噪模型对这种自适应谐波表示存在偏置。
此外,我们表明,当在已知最优基础是几何自适应和调和的常规图像类上训练时,网络的去噪性能接近最优。

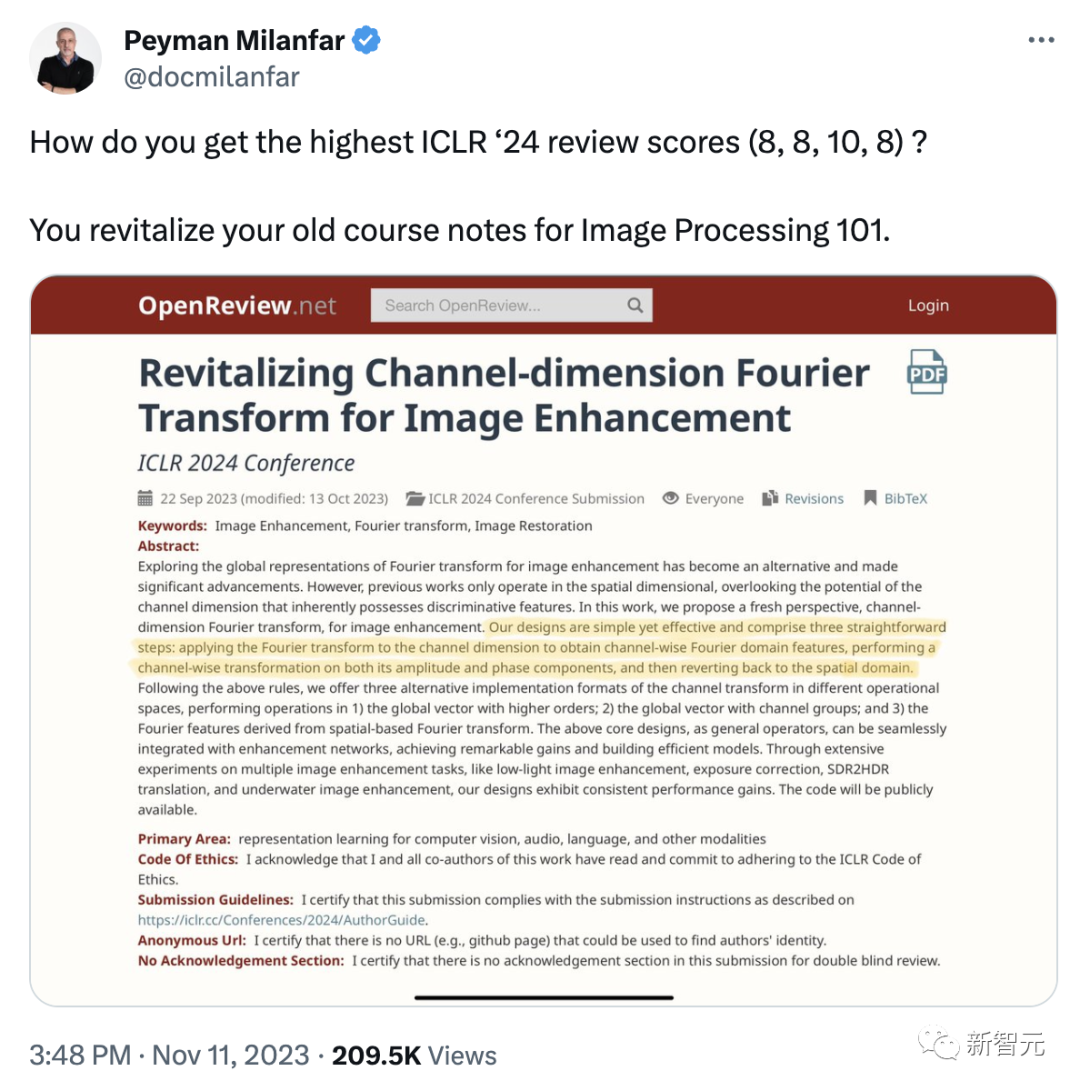
第二篇Revitalizing Channel-dimension Fourier Transform for Image Enhancement是关于图像增强、傅里叶变换的研究,评分为8,10,8,8。
探索傅立叶变换的全局表示来增强图像已成为一种替代方法,并取得了重大进展。
然而,以往的研究只在空间维度上进行,忽略了通道维度的潜力,而通道维度本身就具有识别特征。
在这项工作中,作者提出了一个全新的视角,即用于图像增强的通道维傅里叶变换。
其中的设计过程简单而有效,包括3个简单的步骤:对通道维度进行傅里叶变换以获得通道傅里叶域特征,对其振幅和相位分量进行通道变换,然后返回空间域。
根据上述规则,作者在不同的运算空间中提供了3种可供选择的通道变换实现格式,分别在 1) 带高阶的全局向量;2) 带通道组的全局向量;以及 3) 基于空间的傅里叶变换得到的傅里叶特征中进行运算。
上述核心设计作为通用运算器,可与增强网络无缝集成,取得显著收益并建立高效模型。
通过对多种图像增强任务(如低照度图像增强、曝光校正、SDR2HDR转换和水下图像增强)的广泛实验,研究的设计架构显示出一致的性能提升。

Monte Carlo guided Denoising Diffusion models for Bayesian linear inverse problems是关于去噪扩散模型的研究,评分为6,10,8,10。
从计算摄影到医学成像,各种应用中经常出现难以解决的线性逆问题。最近的研究方向是利用贝叶斯推理和信息先验来处理这类问题。
在这些前置条件中,基于分数的生成模型(SGM)最近被成功应用于几个不同的逆问题。
在这项研究中,作者利用SGM定义的先验的特殊结构,定义了一系列中间线性逆问题。随着噪声水平的降低,这些逆问题的后验越来越接近原始逆问题的目标后验。
为了从这一系列后验中采样,研究人员使用了序列蒙特卡罗(SMC)方法,并提出了算法 \algo。
研究证明,在贝叶斯环境下处理问题不明确的逆问题时,该算法的性能优于其他同类算法。

SDXL模型我们最熟悉不过了,它的评分为8,8,8,8。
作者介绍了用于文本到图像合成的潜在扩散模型——SDXL。与之前版本的SD模型相比,SDXL利用的UNet主干网扩大了3倍,这是通过显著增加注意力块的数量,并加入第二个文本编码器实现的。
此外,研究者还设计了多种新颖的调节方案,并在多种长宽比上对SDXL进行了训练。
为了确保获得最高质量的结果,他们还引入了一个细化模型,用于利用事后图像对图像技术提高SDXL生成的样本的视觉保真度。
研究证明,SDXL比以前版本的Stable Diffusion有了显著改进,其结果可与Midjourney等先进图像生成器相媲美。

至于如何能拿下8,8,10,8的高分论文,你只需要复习自己大学本科学习的图像处理课程就行了。
剩下的高分论文,有感兴趣的童鞋,可以自己查阅。
地址:https://guoqiangwei.xyz/iclr2024_stats/iclr2024_submissions.html
最后,祈祷大家都能中。

参考资料:
https://www.zhihu.com/question/622925909
https://twitter.com/SergeyI49013776/status/1723265271366914481
https://guoqiangwei.xyz/iclr2024_stats/iclr2024_submissions.html
https://twitter.com/omerbartal/status/1723247327710761029

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)


















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









