







这篇文章,我们将向你教你如何使用 LangChain 快速构建一个简单的 LLM 应用,本系列文章将使用 Jupyter notebooks 和 VSCode 编辑器,推荐大家也用这两个,简单易用,非常适合学习如何使用大型语言模型系统,因为事情有时会出错(意外输出、API故障等),在交互环境中逐步阅读指南是更好理解它们的好方法。如果还没使用过的同学,可以参考我们先前的教程文章 《代码编辑与数据分析的完美结合:VSCode 携手 Jupyter Notebook》
1、LangChain 介绍
LangChain 是一个开源框架,旨在简化和加速语言模型(如 GPT-4、通义千问 等)的应用开发。它提供了一系列工具和组件,帮助开发者构建基于语言模型的应用程序,特别是在自然语言处理(NLP)和对话系统方面。
LangChain 包含比较完善的生态, 下面的依赖图显示了不同包之间的关系, 一个有向箭头表示源包依赖于目标包:
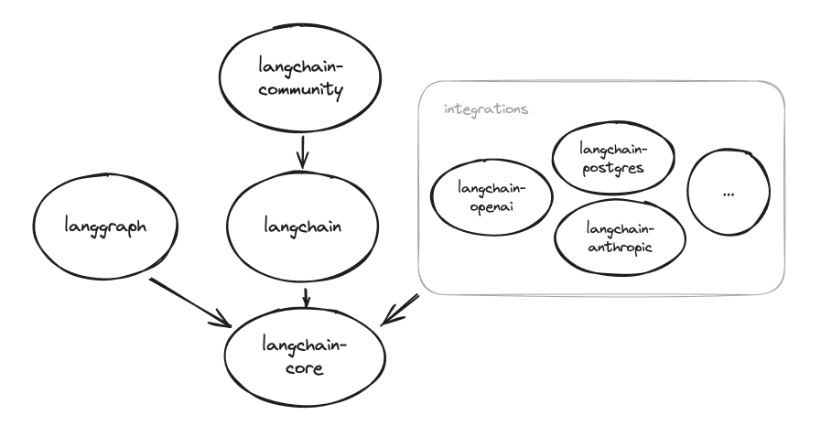
- langchain-core:是 LangChain 的核心包,提供了构建和管理语言模型应用所需的基本组件和功能,包括链(Chains)、代理(Agents)、工具(Tools)和内存(Memory)等,帮助开发者快速搭建复杂的自然语言处理工作流。该包旨在简化与语言模型的交互,使开发者能够更高效地创建智能应用;
- langgraph:是一个用于可视化和分析语言模型工作流的工具包,它允许开发者以图形化方式构建和展示复杂的自然语言处理管道。通过直观的界面,用户可以轻松管理和优化各个组件之间的交互,提高开发效率;
- langchain-community:是一个专为 LangChain 用户设计的扩展包,提供了一系列社区贡献的组件和工具,旨在增强 LangChain 的功能。该包包含示例、模板和实用工具,帮助开发者更高效地构建基于语言模型的应用;
- Integrations 集成包:是指与其他工具和服务的连接,旨在扩展 LangChain 的功能和应用场景。这些集成包可以与多种外部 API、数据库、云服务和其他机器学习框架协同工作,例如:langchain-openai、langchain-postgres 等;
正如上面依赖图所示,langchain 包承上启下,作为使用 LangChain 框架的起点,安装 langchain 包会自动安装以上介绍的 langchain-core、langgraph、langchain-community 包,Integrations 集成中的包根据需要进行安装。
我们使用国内的清华源来安装 langchain 包,运行以下命令即可完成安装
pip install langchain -U -i https://pypi.tuna.tsinghua.edu.cn/simple/2、语言模型使用
LangChain 支持许多不同的语言模型,你可以使用你想要使用的模型!LangChain 支持几乎包括绝大部分的大模型供应商,包括国外的:OpenAI、AWS、谷歌、微软、Hugging Face、IBM等,国内的:阿里云、百度、腾讯、字节跳动、华为、科大讯飞、智普清言等等。
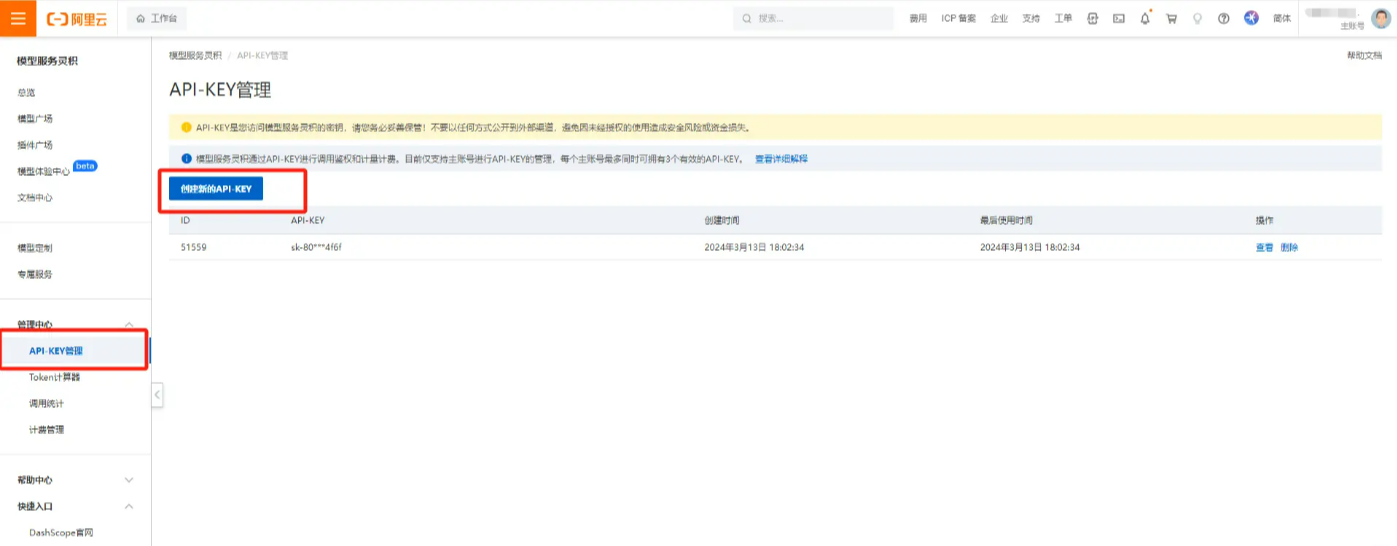
本文我们使用阿里云的通义千问语言模型,可以去通义千问官网申请 apikey,申请地址:dashscope.console.aliyun.com/apiKey
创建一个 api-key,这个 api-key 要好好保存,如果不慎遗失了,可以在查看里面找到这个 key
让我们首先直接使用模型,我们从 langchain_community.llms 包中导入 Tongyi 模型,然后简单地调用模型,我们可以将消息列表传递给 invoke 方法,其中
- HumanMessage:代表用户或人类参与者发送的消息。这通常是用户的输入或提问,系统需要根据这些消息进行响应;
- SystemMessage:代表系统或机器生成的消息。这可以是系统的提示、背景信息、指示或任何其他非用户输入的内容;
import os
os.environ["DASHSCOPE_API_KEY"] = "api-key"
from langchain_community.llms import Tongyi
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Chinese"),
HumanMessage(content="hi!"),
]
Tongyi().invoke(messages)
# --------输出--------
# '你好!'3、提示词模板
前面我们直接将消息列表传递给语言模型,但是我们可以使用提示词模版 PromptTemplates 用来接收原始用户输入并返回准备传递给语言模型的数据(提示)。
让我们在这里创建一个 PromptTemplate。它将接收两个用户变量:
- language: 要翻译成的语言
- text: 要翻译的文本
from langchain_core.prompts import ChatPromptTemplate
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
result = prompt_template.invoke({"language": "Chinese", "text": "hi"})
result.to_messages()
# --------输出--------
# [SystemMessage(content='Translate the following into Chinese:', additional_kwargs={}, response_metadata={}),
# HumanMessage(content='hi', additional_kwargs={}, response_metadata={})]4、使用 LCEL 连接组件
我们可以使用 LangChain 表达式 (LCEL) 来连接以上 LangChain 模块的简单示例,这种方法有几个好处,包括优化的流式处理和追踪支持。如下所示,我们使用管道 (|) 操作符将其与上面的模型和提示词模版结合起来:
chain = prompt_template | Tongyi()
chain.invoke({"language": "Chinese", "text": "hi"})
# --------输出--------
# '你好'这篇文章,我们教你如何使用 LangChain 快速构建一个简单的 LLM 应用,包括 LangChain 介绍、通义语言模型使用、提示词模板、使用 LCEL 连接组件的完整介绍,希望对你有帮助!
如果你喜欢本文,欢迎点赞,并且关注我们的微信公众号:Python技术极客,我们会持续更新分享 Python 开发编程、数据分析、数据挖掘、AI 人工智能、网络爬虫等技术文章!让大家在Python 技术领域持续精进提升,成为更好的自己!
添加作者微信(coder_0101),拉你进入行业技术交流群,进行技术交流


















 3543
3543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











