







1、前言
检索增强生成 (RAG) 系统通过集成外部知识源来增强大型语言模型 (LLM),从而根据用户需求实现更准确和上下文相关的响应。然而,现有的 RAG 系统存在重大局限性,包括对平面数据表示的依赖和上下文感知不足,这可能导致答案碎片化,无法捕捉复杂的相互依赖关系。为了应对这些挑战,我们提出了 LightRAG,它将图形结构整合到文本索引和检索过程中。这个创新的框架采用双级检索系统,增强了从低级和高级知识发现中进行全面的信息检索。此外,图形结构与矢量表示的集成有助于高效检索相关实体及其关系,从而显著缩短响应时间,同时保持上下文相关性。增量更新算法进一步增强了此功能,该算法可确保及时集成新数据,使系统能够在快速变化的数据环境中保持有效和响应。广泛的实验验证表明,与现有方法相比,检索准确性和效率有了相当大的提高。
- LightGraph论文地址: https://arxiv.org/pdf/2410.05779v1
- LightGraph源码地址:https://github.com/HKUDS/LightRAG
2、简介
LightRAG 是一种轻量级、高效的检索增强生成(Retrieval-Augmented Generation, RAG)框架,旨在通过结合外部知识库和生成式模型(如大语言模型)来提升文本生成任务的质量和准确性。
LightRAG的主要优势包括:
- 高效的知识图谱构建:LightRAG通过图结构差异分析实现增量更新算法,显著降低了计算开销,使知识库维护更加高效。
- 双层检索机制:该系统结合了低层次(具体实体和属性)和高层次(广泛主题和概念)的检索策略,满足了不同类型的查询需求,提高了检索的全面性和多样性。
- 快速适应动态数据:LightRAG能够在新数据到来时快速整合,无需重建整个知识库,确保系统在动态环境中保持高效和准确。
3、核心设计
检索增强生成:支持无缝集成新数据到现有图结构中,无需重建索引,确保系统快速适应新环境,融合了kv存储、图数据存储、向量存储。检索增强生成 (RAG) 将用户查询与来自外部知识数据库的相关文档集合集成在一起,其中包含两个基本元素:检索组件和生成组件。1) 检索组件负责从外部知识数据库获取相关文档或信息。它根据输入查询识别并检索最相关的数据。2) 检索过程之后,生成组件获取检索到的信息并生成连贯的、与上下文相关的响应。它利用语言模型的功能来生成有意义的输出。从形式上讲,这个 RAG 框架(表示为 M)可以定义如下:
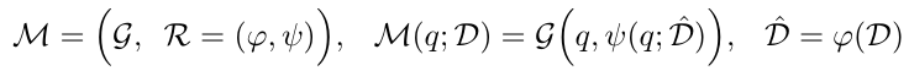
• 提取实体和关系。R(·),此函数提示 LLM 识别文本数据中的实体(节点)及其关系(边缘)
•LLMProfiling 用于生成键值对。P(·),使用 LLM 授权的分析函数 P(·),为 V 中的每个实体节点和 E 中的关系边生成一个文本键值对 (K,V)
• 去重以优化图形作。D(·),实现了一个重复数据删除函数 D(·),它识别并合并原始文本中的不同片段中的相同实体和关系。
整体框架结构
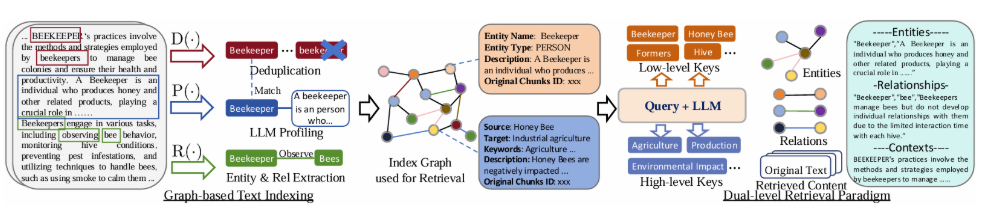
相关主要流程代码:
1)文档切片
chunking_func: Callable[
[
str,
str | None,
bool,
int,
int,
str,
],
list[dict[str, Any]],
] = field(default_factory=lambda: chunking_by_token_size)
# 逻辑:chunk tokens大小为1200,重叠部分为100,先获取每个chunk的start后切分
for chunk in raw_chunks:
_tokens = encode_string_by_tiktoken(chunk, model_name=tiktoken_model)
if len(_tokens) > max_token_size:
for start in range(
0, len(_tokens), max_token_size - overlap_token_size
):
chunk_content = decode_tokens_by_tiktoken(
_tokens[start : start + max_token_size],
model_name=tiktoken_model,
)
new_chunks.append(
(min(max_token_size, len(_tokens) - start), chunk_content)
)
else:
new_chunks.append((len(_tokens), chunk))
结果样例

2)提取实体关系并合并
循环遍历每次对单个chunk提取实体以及关系,提取后合并
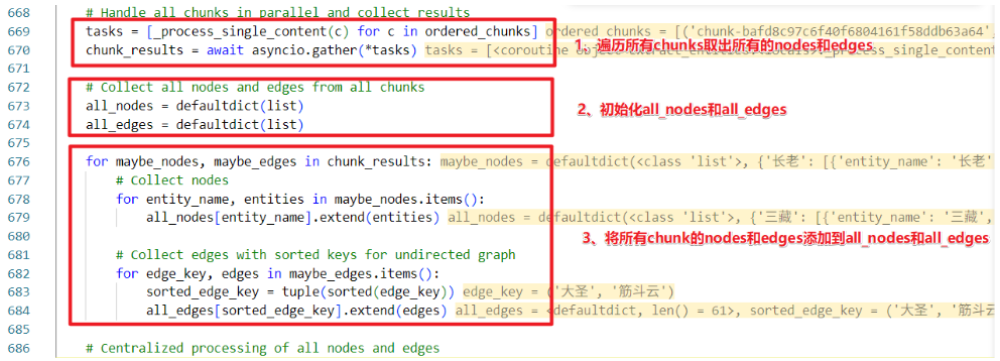
合并数据来源
nodes_data:当前处理批次中提取的实体数据(例如单篇文档分块后提取的实体列表)。
全局节点数据:通过查询知识图谱(knowledge_graph_inst.get_node)获取已存在的节点信息。
合并过程(all_nodes)
实体类型(entity_type)合并:
逻辑:统计当前批次实体类型(nodes_data)和已有节点类型的出现频率,选择频率最高的类型。
entity_type = sorted(
Counter([dp["entity_type"] for dp in nodes_data] + already_entity_types).items(),
key=lambda x: x[1],
reverse=True,
)[0][0]
3)入库存储
将提取的实体关系写入图数据库文件
# Update vector databases with all collected data
if entity_vdb is not None and entities_data:
data_for_vdb = {
compute_mdhash_id(dp["entity_name"], prefix="ent-"): {
"entity_name": dp["entity_name"],
"entity_type": dp["entity_type"],
"content": f"{dp['entity_name']}\n{dp['description']}",
"source_id": dp["source_id"],
"file_path": dp.get("file_path", "unknown_source"),
}
for dp in entities_data
}
await entity_vdb.upsert(data_for_vdb)
if relationships_vdb is not None and relationships_data:
data_for_vdb = {
compute_mdhash_id(dp["src_id"] + dp["tgt_id"], prefix="rel-"): {
"src_id": dp["src_id"],
"tgt_id": dp["tgt_id"],
"keywords": dp["keywords"],
"content": f"{dp['src_id']}\t{dp['tgt_id']}\n{dp['keywords']}\n{dp['description']}",
"source_id": dp["source_id"],
"file_path": dp.get("file_path", "unknown_source"),
}
for dp in relationships_data
}
await relationships_vdb.upsert(data_for_vdb)
图结构化索引
采用图结构存储文档中的实体及其关系,通过LLM(Large Language Model)识别实体和关系,生成索引键值对,优化检索效率。
源码中自带的英文版的promt,可以自己翻译生成中文版promt,通过中文版promt以及大模型可生成相应的中文关系描述。
4)双层检索机制
低层精确查询(如特定实体属性)和高层主题查询(捕捉上下文主题),分层收集相关数据。
**Local 模式:**聚焦实体,需直接定位实体信息,适合精确查询(如实体名称匹配),使用 entity-vdb
快速定位与查询直接相关的单个实体(如人物、地点、概念等)。
将查询转换为实体嵌入,在 entity-vdb 中检索相似实体。
通过实体匹配找到相关文本片段。
适用场景 简单问题 需要直接关联实体与文本(如实体链接、属性查询)。
**Global 模式:**关注关系,需通过关系描述泛化检索,适合语义扩展(如通过关键词匹配多跳关系),使用 relationship-vdb
将查询转换为关系嵌入,在 relationship-vdb 中检索相关关系。
通过关系匹配找到实体对及其关联文本。
适用场景 需要推理的问题、涉及多跳关系或跨实体分析。
(1)对于给定的查询,LightRAG 的检索算法会提取局部查询关键词(low_level_keywords)和全局查询关键词(high_level_keywords):

(2)检索算法使用向量数据库来匹配局部查询关键词与候选实体,以及全局查询关键词与候选关系:
async def _build_global_query_context(
keywords,
knowledge_graph_inst: BaseGraphStorage,
entities_vdb: BaseVectorStorage,
relationships_vdb: BaseVectorStorage,
text_chunks_db: BaseKVStorage[TextChunkSchema],
query_param: QueryParam,
):
# 用keywords匹配top_k个最相关的relationships
edge_datas = await relationships_vdb.query(keywords, top_k=query_param.top_k)
# 根据relationships找到entities
use_entities = await _find_most_related_entities_from_relationships(
edge_datas, query_param, knowledge_graph_inst
)
# 找到对应的文本块
use_text_units = await _find_related_text_unit_from_relationships(
edge_datas, query_param, text_chunks_db, knowledge_graph_inst
)
......
from nano_vectordb import NanoVectorDB
......
self._client = NanoVectorDB(
self.embedding_func.embedding_dim, storage_file=self._client_file_name
)
......
async def query(self, query: str, top_k=5):
embedding = await self.embedding_func([query])
embedding = embedding[0]
results = self._client.query(
query=embedding,
top_k=top_k,
better_than_threshold=self.cosine_better_than_threshold,
)
results = [
{**dp, "id": dp["__id__"], "distance": dp["__metrics__"]} for dp in results
]
return results
(3)增强高阶关联性:。LightRAG 进一步收集已检索到的实体或关系的局部子图,如实体或关系的一跳邻近节点,数学公式表示如下:
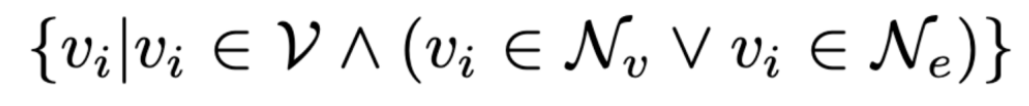
其中 Nv 和 Ne 分别表示检索到的节点 v 和边 e 的单跳相邻节点。
(4)检索到的信息分为三个部分:实体、关系和对应的文本块。然后将这个结构化数据输入到 LLM 中,使其能够为查询生成全面的答案
代码依据与流程分析
1). local 模式(基于实体)
-
目标:直接通过实体名称检索实体信息及其关联的文本块。
-
代码依据:
在 operate_bak.txt 的 _get_node_data 函数中,local 模式通过 entities_vdb.query 查询相似实体(代码)。

实体向量数据库 entities_vdb 存储实体的名称、描述等元数据,通过实体名称直接匹配高相关性的实体(如 entity_name 字段)。
2). global 模式(基于关系) -
目标:通过关系关键词(如描述、关键字)检索全局关系网络。
-
代码依据:
- 在 operate.py 的 _get_edge_data 函数中,global 模式通过 relationships_vdb.query 查询关系(代码)。
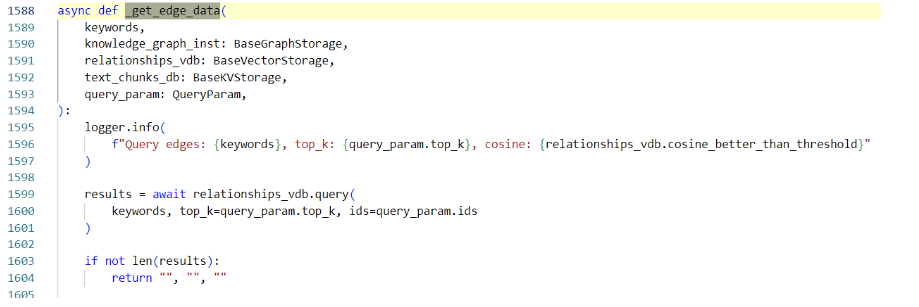
- 在 operate.py 的 _get_edge_data 函数中,global 模式通过 relationships_vdb.query 查询关系(代码)。
关系向量数据库 relationships_vdb 存储关系的 src_id、tgt_id、description 等字段,支持通过语义匹配全局关系网络。

















 4297
4297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









