







1、torch安装
pytorch cuda版本下载地址:https://download.pytorch.org/whl/torch_stable.html
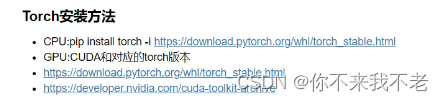
其中先看官网安装torch需要的cuda版本,之后安装cuda版本,之后采用pip 下载对应的torch的gpu版本whl来进行安装。使用pip安装时如果是conda需要切换到对应的env下。
2、tensor创建
(1)创建不同类型的tensor
#torch 基础知识
import torch
#创建不同类型的tensor
print("创建不同类型的tensor")
a_float = torch.Tensor([1,2,3])
print("a_float=", a_float)
a_float2 = torch.FloatTensor([1,2,3]).zero_()#增加了zero_表示原地计算绝对值,返回原值,zero则计算一个新的tensor结果
print("a_float2=", a_float2)
a_int = torch.IntTensor([1,2,3])
print("a_int =", a_int)
a_double = torch.DoubleTensor(1,2)
print("a_double =", a_double)
print("后面还有ByteTensor(unsigned 8 bit integer),CharTensor(signed 8 bit integer), ShortTensor(16 bit integer), LongTensor(64 bit integer)")=============================结果=======================================
创建不同类型的tensor a_float= tensor([1., 2., 3.]) a_float2= tensor([0., 0., 0.]) a_int = tensor([1, 2, 3], dtype=torch.int32) a_double = tensor([[4.4743e-316, 4.4757e-316]], dtype=torch.float64) 后面还有ByteTensor(unsigned 8 bit integer),CharTensor(signed 8 bit integer), ShortTensor(16 bit integer), LongTensor(64 bit integer)
(2)通过不同形式输入创建tensor
#通过不同输入创建tensor
print("通过不同输入创建tensor,size, *size, sequence, ndarray,tensor,storage")
a_size = torch.IntTensor(2,3)
print("a_size =", a_size)
a_size2 = torch.Tensor(*[1,2,3])
print("a_size2=",a_size2)
a_sequence = torch.Tensor([1,2,3])
print("a_sequence =", a_sequence)======================================结果========================================
通过不同输入创建tensor,size, *size, sequence, ndarray,tensor,storage
a_size = tensor([[408112416, 32605, 90579216],
[ 0, 32, 0]], dtype=torch.int32)
a_size2= tensor([[[1.2311e-35, 0.0000e+00, 1.1751e-35],
[0.0000e+00, 8.9683e-44, 0.0000e+00]]])
a_sequence = tensor([1., 2., 3.])
(3)torch.Tensor()与torch.tensor()的区别
torch.Tensor()是一个类,是默认张量类型torch.FloatTensor()的别名,用于生成一个单精度浮点类型的张量
torch.tensor()这里是小写,仅仅是一个python函数,函数原型是torch.tensor(data, dtype=None, device=None, require_grad=False),其中data可以是list、tuple,numpy,ndarray等其他类型,torch.tensor会从data中数据部分拷贝而不是直接引用,根据数据类型生成相应类型的torch.Tensor
a_Tensor = torch.Tensor([1,2,3])
print("a_Tensor =", a_Tensor)
a_tensor = torch.tensor([1,2,3])
print("a_tensor =", a_tensor)==================================结果====================================
Torch.Tensor()与torch.tensor()的区别 a_Tensor = tensor([1., 2., 3.]) a_tensor = tensor([1, 2, 3])
(4)Tensor类型间的转换
CPU和GPU的Tensor之间转换
data.cuda():cpu –> gpu
data.cpu():gpu –> cpu
Tensor与Numpy Array之间的转换
data.numpy():Tensor –> Numpy.ndarray
torch.from_numpy(data):Numpy.ndarray –> Tensor
Tensor的基本类型转换
tensor.long():
tensor.half():将tensor投射为半精度浮点(16位浮点)类型
tensor.int():
tensor.double():
tensor.float():
tensor.char():
tensor.byte():
tensor.short():
Tensor的基本数据类型转换
type(dtype=None, non_blocking=False, **kwargs):指定类型改变。例如data = data.type(torch.float32)
type_as(tensor):按照给定的tensor的类型转换类型。
#Tensor类型间的转换
print("Tensor类型间的转换")
#1 转换tensor的类型
a_int = torch.IntTensor([1,2,3])
print("a_int =", a_int)
a_float = a_int.type(torch.float)
print("a_float =", a_float)
b_int = torch.IntTensor([6,6,6])
print("b_int =", b_int)
b_float = b_int.type_as(a_float)
print("b_float =", b_float)
b_float2 = b_int.float()
print("b_float2 =", b_float2)==========================结果=================================
Tensor类型间的转换 a_int = tensor([1, 2, 3], dtype=torch.int32) a_float = tensor([1., 2., 3.]) b_int = tensor([6, 6, 6], dtype=torch.int32) b_float = tensor([6., 6., 6.]) b_float2 = tensor([6., 6., 6.])
2.torch.nn.functional中有很多功能。什么时候用nn.Module,什么时候用nn.functional。一般参数情况下有学习参数使用nn.Module,其他情况用nn.functional相对更简单一些。
3、一般模型在训练时会使用model.train,这样会正常使用Batch Normalization和Dropout,
测试时一般选择model.eval(),这样就不使用Batch Normalization和Dropout
4、对于tensor,维度0表示纵轴,维度1表示横轴。
5、nn.Sequential是表示按照序列进行层运算。
6、加载预训练模型,torchvision中有很多经典网络架构,调用起来十分方便,并且可用人家训练好的权重参数来继续训练,也就是所谓的迁移学习。
需要注意的是别人训练好的任务跟咱们得可不是完全一样,需要把最后head层改一改,一般也就是最后的全连接层,改成咱们自己的任务;
训练时可以全部重头训练,也可以只训练最后任务层;
网络保存可以有选择性,选择验证集中效果最好的。
7、from torchvision import transforms, models, datasets
8、transforms.Compose([
transforms.Resize([96,96]),
transforms.RandomRotation(45),
transforms.RandomRotation(45),#随机旋转,-45到45
transforms.CenterCrop(64),
transforms.HorizontalFilp,RandomVerticalFlip,ColorJitter
ToTensor, Normalize
]),
归一化:x减u除以标准差
9、model name
feature_extract = True都用人家的特征,先不更新。
model_ft = models.resnet18()
最后AdaptiveAvgPool2d(output_size=(1,1))
in_features=512, out_features=1000,bias=True
def set_parameter_requires_grad(model, feature_extracting)
if feature_extracting:
for param in model.parameters()#name, param in model.named_parameters()
param.requires_grad = False
model_ft = model.resnet18(pretrained=use_pretrained)
num_f = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_f, 102)
model_ft, input_size=initialize_model(model_name,102,feature_extract, use_pretrained=True)
#保存模型就是保存graph、parameter
filename='model.ft'
if feature_extract:
params_to_update = []
for name, param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
optimizer_ft = optim.Adam(params_to_update, lr=1e-2)#将需要更新的参数传进来,这里只更新最后的fc层
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.1
#学习率每迭代10个epoch衰减原来的1/10
criterion = nn.CrossEntropyLoss()
def train_model(model, dataloaders, criterion, optimizer, num_epoch=25,
filename="best.pt")
best_acc = 0 #模型保存最好的
device = 'cuda:0'
LRs = [optimizer.param_groups[0]['lr']]
best_model_wts = copy.deepcopy(model.state_dict())
for inputs, labels in dataloader[phase]:
optimizer.zero_grad()
#只有训练的时候计算和更新梯度
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
if phase == 'train':
loss.backward()
optimizer.step()
runing_loss += loss.item()
runing_crrets += torch.sum(preds == labels.data)
epoch_loss = running_loss/len(dataloader[phase].dataset)
if phase == 'valid' and epoch_acc>best_acc:
state = {
'state_dict' :model.state_dict(),
'best_acc': best_acc,
'optimizer':optimizer.state_dict(),
}
LRs.append(optimizer.param_groups[0]['lr'])
scheduler.step()
model.load_state_dict(best_model_wts)
return model, val_acc_history, train_acc_history
10、训练对比
resnet18,只冻住FC层,则性能36%
resnet18,全部训练,则性能
for param in model_ft.parameters():
param.requires_grad = True
checkpoint = torch.load(filename)
model_ft.load_state_dict(checkpoint['state_dict'])
测试数据预处理:
测试数据处理方法要跟训练时一致才可以
crop操作目的保证输入大小一致
标准化也是必须得,使用训练相同的mean和std
最后颜色通道是一个维度,很多工具包都不一样,需要转换
PIL工具包,from PIL import image
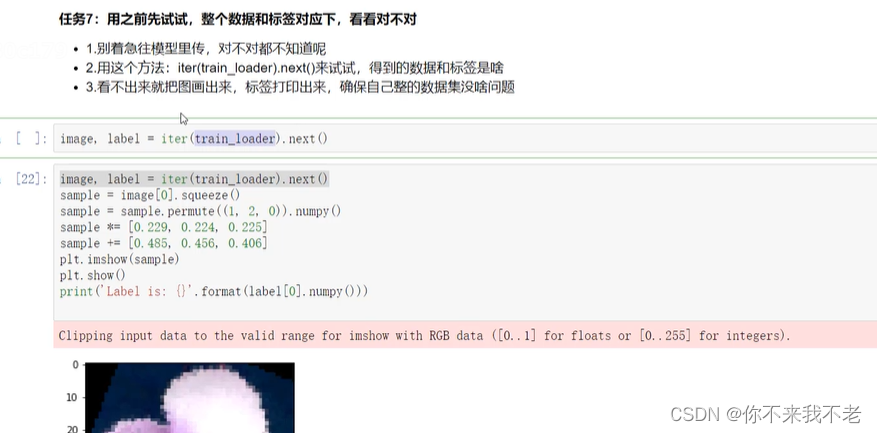
fig = plt.figure(figsize=(20,20))
11、数据集制作

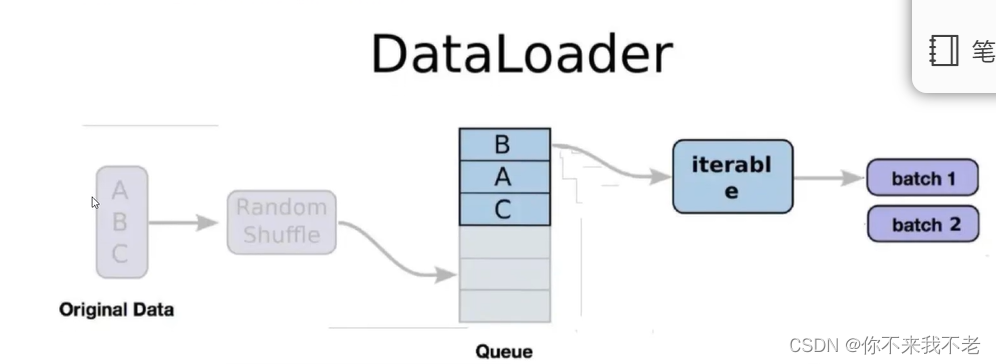
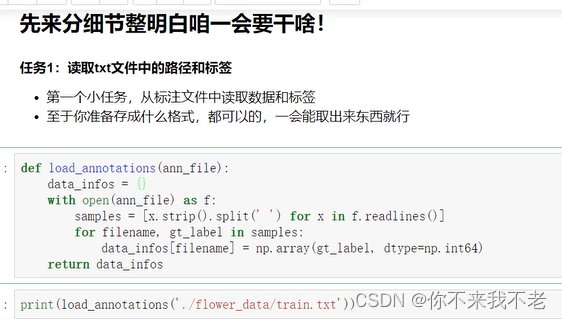

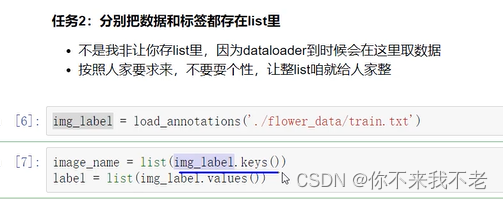
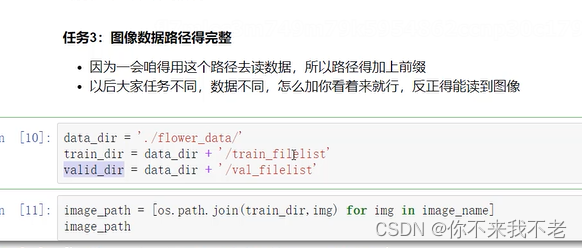
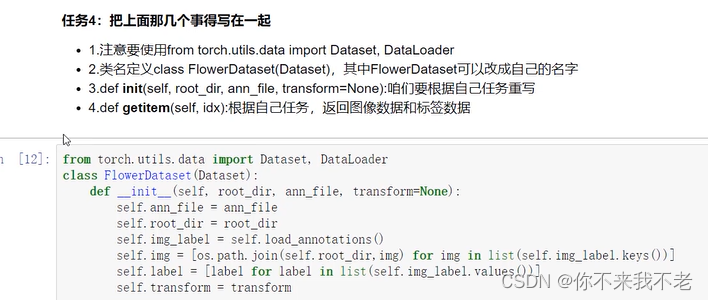
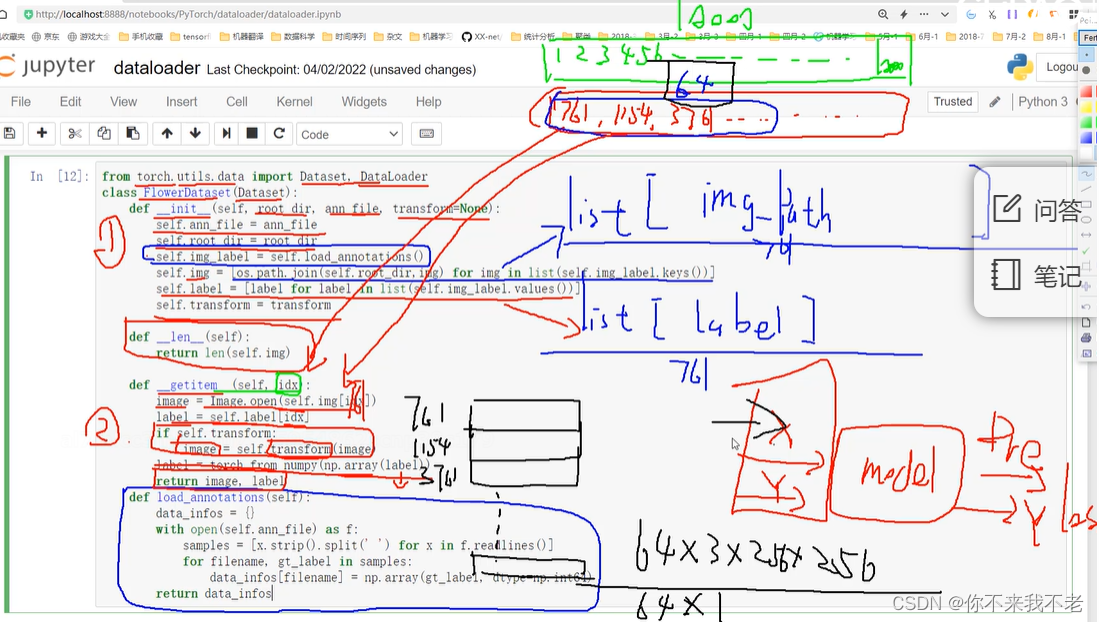

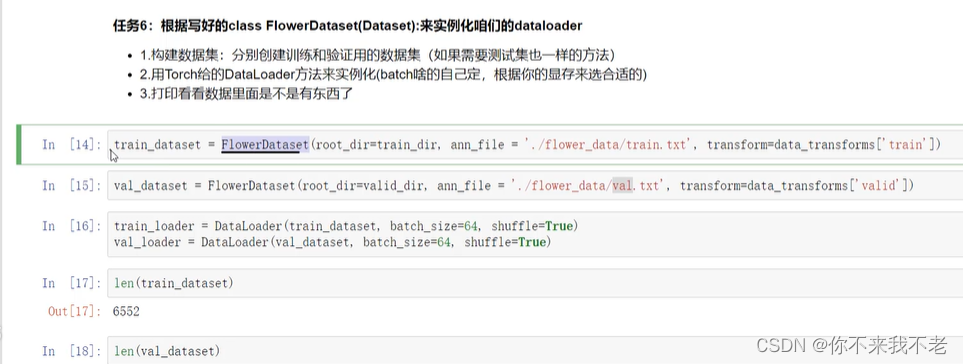
(6) 将写好的Dataset进行实例化,并实例化dataloader
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









