






点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达大家好,我是阿潘,今天和大家分享 ICCV 2021 的一份非常惊艳的工作, DeepSim
论文标题:
Image Shape Manipulation from a Single Augmented Training Sample
论文和代码链接:
https://arxiv.org/pdf/2109.06151.pdf
https://github.com/eliahuhorwitz/DeepSIM

效果太震撼了,pix2pix 可以实现简单表征(草图)到目标图像(真实图),但是泛化能力并不理想,对于训练集数据以外的结果生成效果不好,本文仅需一对样本对训练(如果没有理解错的话)即可得到这样子的结果真的太牛了
先看效果:

衣服设计demo:
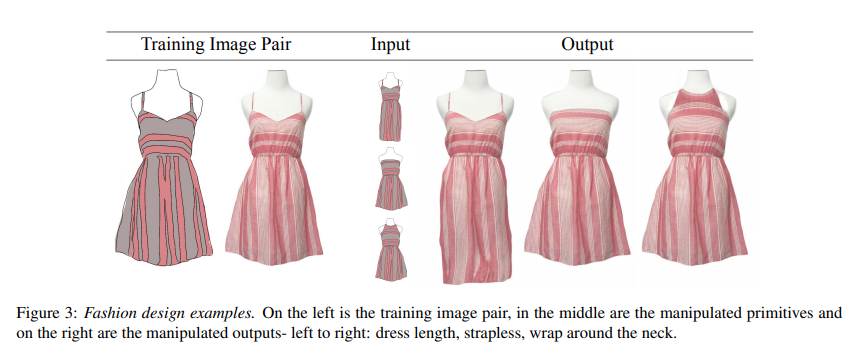
动物的简单表征到真实图片:

与其他算法效果对比:


摘要
在本文中,提出了一种基于单个图像的条件图像操控生成模型DeepSIM。我们发现,广泛的增强是实现单图像训练的关键,并结合使用薄板样条(thin-plate-spline, TPS)作为一种有效的增强。网络学习在图像的原始表征与图像本身之间进行映射。原始表征的选择对操作的易用性和表达能力有影响,可以是自动的(如边)、手动的(如分割)或混合的(如分割顶部的边)。在操作时,我们的生成器允许通过修改原始输入表征并通过网络映射来进行复杂的图像更改。我们的方法在图像操控任务中取得了显著的效果。
主要贡献
-
一种仅由单个图像对监督的训练条件生成器的通用方法。
-
识别是图像增强是这项任务的关键,以及薄板样条(TPS)增强的显著性能,该增强以前未用于单个图像处理。
-
在一系列图像操控应用程序中实现出色的视觉性能
方法
方法仅使用由主图像及其原始表征组成的单个图像对来学习条件生成对抗网络(cGAN)。为了考虑有限的训练集,我们通过在训练对上使用薄板样条曲线(TPS)来扩充数据。提出的方法有几个目标:
i)单个图像训练
ii)保真度-输出应反映原始表征
iii)外观-输出图像应与训练图像来自相同的分布
模型设计遵循cGAN模型的标准实践(特别是Pix2PixHD[35])
目标是学习一个生成网络,能够学习将输入的原始表征映射到生成的图片 G(x)
这里适用 VGG感知损失衡量结果的保真程度,这里适用的是在ImageNet数据集上预训练的 VGG 网络,从图片中提取一系列激活值来对比两个图像之间的差距(生成结果和原始图片),因此重建损失可以写成:

Conditional GAN loss:
按照标准实践,添加了一个对抗性损失,该损失衡量判别器区分(原始,生成图像)对(x,G(x))和(原始,真实图像)对(x,y)的能力。

因此整体的loss可以写成:

重点:
当存在大型数据集时,通过生成器G和条件判别器D,不断优化整体loss以产生一个强大的生成器G。然而,由于我们只有一个图像对(x,y),此公式严重过拟合。这就产生了G不能推广到新的原始输入的负面后果。为了推广到新的原始表征,需要人为地增加训练数据集的大小,以覆盖预期原始的范围。条件生成模型通常使用简单的裁剪和翻转增强,这种简单的增强策略不会推广到具有非一般变化的原始图像。
将薄板样条线(TPS)作为一个额外的增强,以扩展我们的单一图像数据集。对于每个TPS增强,在图像上放置一个等距3×3的控制点网格(i,j),然后在水平和垂直方向上按随机(均匀分布)数量的像素移动控制点。这个偏移会产生一个非平滑的扭曲,我们用t(i,j)来表示。为了防止在我们的训练图像中出现退化变换,移动量被限制为图像宽度和高度之间最小值的10%

可视化效果:
优化:
在训练期间,我们随机抽取TPS翘曲。每个随机翘曲f∼ Ω 变换输入原语x和图像y以创建新的训练对(f(x),f(y))(其中我们表示f(x)(i,j)=x(i′,j′),其中(i′,j′)=f(i,j))。我们对发生器和鉴别器进行了逆向优化,以最小化损失的整体loss的期望。随机TPS翘曲的经验分布下的总计:
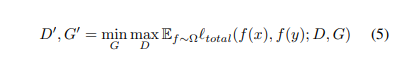
将Pix2PixHD体系结构与官方超参数一起使用(除了使用16000次迭代)
总结
这里作者针对图像翻译任务中,常见的问题,模型的生成效果存在泛化能力不足,特别是当训练数据不足的情况,广泛的增强是实现单图像训练的关键,并结合使用薄板样条(thin-plate-spline, TPS)作为一种有效的增强。
提出了一种基于TPS增强的从单个训练图像训练条件生成器的方法。能够在高分辨率下执行复杂的图像处理。单图像方法具有巨大的潜力,它们将图像的细节保留到以前在大型数据集上训练的方法无法达到的水平
今天分享的内容就到这里拉,如果喜欢可以帮忙分享一下,我是阿潘,努力分享更多优秀的成果!















 6604
6604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









