








 本文介绍了KL散度的概念,作为衡量概率分布间相似性的指标,它在模型评估和参数优化中发挥重要作用。通过实例说明了如何计算KL散度,并探讨了它与交叉熵的区别。此外,还展示了在PyTorch中计算KL散度的代码示例,以及KL散度在选择数据集概率分布表达式中的应用。最后,讨论了交叉熵作为损失函数的特殊情况。
本文介绍了KL散度的概念,作为衡量概率分布间相似性的指标,它在模型评估和参数优化中发挥重要作用。通过实例说明了如何计算KL散度,并探讨了它与交叉熵的区别。此外,还展示了在PyTorch中计算KL散度的代码示例,以及KL散度在选择数据集概率分布表达式中的应用。最后,讨论了交叉熵作为损失函数的特殊情况。
1. 概念
KL散度可以用来衡量两个概率分布之间的相似性,两个概率分布越相近,KL散度越小。
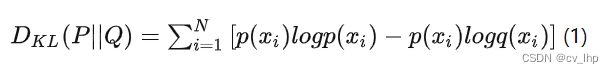
上述公式表示P为真实事件的概率分布,Q为理论拟合出来的该事件的概率分布。D(P||Q)(P拟合Q)和D(Q||P)(Q拟合P)是不一样的。
2. 举例
班里男生人数占40%,女生占60%,则班里随机抽取一个人的性别的概率分布是Q = [0.4, 0.6]。作为真实事件的概率分布。
小明猜测班里男生占30%,女生占70%,则小明拟合的概率分布P1 = [0.3, 0.7]。
小红猜测班里男生占20%,女生占80%,则小红拟合的概率分布P2 = [0.2, 0.8].
那么现在,小明和小红谁预测的概率分布离真实分布比较近?这时候就可以用KL散度来衡量P1与Q的相似性、P2与Q的相似性,然后对比可得谁更相似。
小明是模拟概率分布(对应Q1),真实概率分布对应P,所以 KL1 = KL(P||Q) = KL([0.4, 0.6] | [0.3, 0.7]) = (0.4log0.4 - 0.4log0.3) + (0.6log0.6 - 0.6log0.7) = 0.0226;同理小红是模拟概率分布(对应Q2),真实概率分布对应PKL2=KL(P||Q2) = KL([0.4, 0.6] | [0.2, 0.8]) = (0.4log0.4 - 0.4log0.2) + (0.6log0.6 - 0.6log0.8) = 0.1046。
KL1比KL2小,说明Q1与P更接近。
这个例子很直观,不用计算就可以猜测出结果,但是当分布复杂的情况下,用KL散度就比较好度量。如一个数据集分布未知,想用数学公式来表达,比如高斯分布、泊松分布、韦伯分布等,这些分布哪个更适合用来表示数据集的分布。则可以计算拟合曲线与数据集真实分布的KL散度,选择KL散度最小的作为数据集的概率分布表达式。
如:用高斯分布拟合数据集分布时,统计均值μ,标准差σ,则可得到高斯分布表达式:
再用高斯分布表达式不同自变量x1,x2,…计算出不同类别的概率q1,q2…,即概率分布Q=[q1, q2,…],与真实的概率分布P = [p1,p2,…]通过上面公式计算得到KL散度。
同理,计算其他拟合分布与真实分布的KL散度,对比得到最优用来拟合真实数据的概率分布表达式。
3. Pytorch计算KL散度
现在,明白了什么是KL散度,可以用pytorch自带的库函数来计算KL散度。
使用pytorch进行KL散度计算,可以使用pytorch的kl_div函数,假设Y_true为真实分布,Y_pred为预测分布。
import torch.nn.functional as F
kl = F.kl_div(Y_pred.log_softmax(dim=-1).log(), Y_true.softmax(dim=-1), reduction='sum')
其中kl_div接收三个参数,第一个为预测分布,第二个为真实分布,第三个为reduction。(其实还有其他参数,只是基本用不到)
这里有一些细节需要注意,第一个参数与第二个参数都要进行softmax(dim=-1),目的是使两个概率分布的所有值之和都为1,若不进行此操作,如果x或y概率分布所有值的和大于1,则可能会使计算的KL为负数。softmax接收一个参数dim,dim=-1表示在最后一维进行softmax操作。除此之外,第一个参数还要进行log()操作(至于为什么,大概是为了方便pytorch的代码组织,pytorch定义的损失函数都调用handle_torch_function函数,方便权重控制等),才能得到正确结果。
第三个参数reduction有三种取值,为 none 时,各点的损失单独计算,输出损失与输入(x)形状相同;为 mean 时,输出为所有损失的平均值;为 sum 时,输出为所有损失的总和。
需要清晰的一点解释是:D(P||Q)中P和Q的实际意义,P代表真实概率,也就是对应的是ground truth归一化+log(是否进行log由kl_div()的最后一个参数log_target确定,默认为False即认为输入kl_div()的第二个参数target未进行log)。那么Q就是对应的log(softmax(logit))。这两点才是实际中的定义,所以并没有相反一说,并且调用kl_div()是参数名称也非常明确了,第一个参数是input,第二个参数是target。
代码举例:
#target没有log
import torch
import torch.nn as nn
import torch.nn.functional as F
kl_loss = nn.KLDivLoss(reduction="batchmean")
# input should be a distribution in the log space
input = F.log_softmax(torch.randn(3, 5, requires_grad=True), dim=1)
# Sample a batch of distributions. Usually this would come from the dataset
target = F.softmax(torch.rand(3, 5), dim=1)
output = kl_loss(input, target)
target没有log输出结果:
输出结果:tensor(0.3441, grad_fn=<DivBackward0>)
#target有log
import torch
import torch.nn as nn
import torch.nn.functional as F
kl_loss = nn.KLDivLoss(reduction="batchmean", log_target=True)
input = F.log_softmax(torch.randn(3, 5, requires_grad=True), dim=1)
log_target = F.log_softmax(torch.rand(3, 5), dim=1)
output = kl_loss(input, log_target)
target有log输出结果:
tensor(0.4346, grad_fn=<DivBackward0>)
4. 我理解的交叉熵和KL
交叉熵作为深度学习常用的损失函数,可以理解为是KL散度的一个特例。当概率分布中的值只取1或0时,可以看作KL散度。但是两者又有区别,KL散度中概率分布所有值之和为1,而交叉熵则可以大于1,如[0,1,0,1,0,0,]。
从概念上讲,KL 散度通常用来度量两个概率分布之间的差异。
交叉熵用来求目标与预测值之间的差距,数据分布不一定是概率分布。
设数据的真实分布为 P(x),而Q(x)表示我们模型预测出来的数据分布,那么KL散度则为:
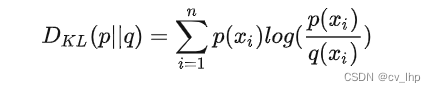
化简就是:
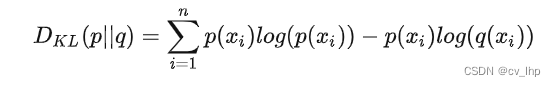
因为P(x)是真实分布,也即是由上面公式可知D(P||Q)前面一项是固定的,所以只要后面的项越小,KL散度就越小,也就是损失越小。
而交叉熵是KL的一个特例,也用上面的公式计算loss,因为label是采用one-hot格式,即是正确label处的值为1,其余label处的值为0,因此D(P||Q)前面一项是0,就只剩后面一项,因此定义了一个计算loss的交叉熵损失函数,也就是,因此KL散度等于KL前面一项(熵)加上交叉熵,一定程度上优化kl散度和优化交叉熵是等价的:
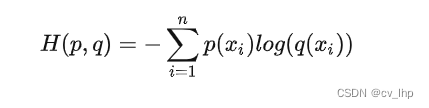
5.参考链接
KL散度理解以及使用pytorch计算KL散度
为什么 不用KL散度作为损失函数? 感觉这个问题描述得不怎么准确???

















 3579
3579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









