







文献来源
IEEE TRANSACTION ON NEURAL SYSTEMS AND REHABILITATION ENGINEERING, VOL,28, NO.12, DECEMBER 2020
Eduardo Santamaría-Vázquez , Víctor Martínez-Cagigal , Fernando Vaquerizo-Villar , and Roberto Hornero , SeniorMember,IEEE
摘要
方法:EEG-Inception 结合跨被试转移学习、微调fine-tuning
目的:改善精确率和校准时间
效果:rLDA、xDAWN+黎曼几何、CNN-BLSTM、DeepConvNet和EEGNet,分别实现提高了16.0%, 10.7%, 7.2%, 5.7% 和5.1% 的解码性能
引言
Inception模块:允许并行使用不同内核大小的卷积层,对输入数据进行多尺度分析。能够以较小的计算量提取出更丰富的特征,在保持合理的训练和评估时间的前提下提高性能。
被试
73个被试,来自3个数据集。其中,42健康(年龄25.4±4.3,31男),31重度残疾(年龄44.2±7.7,20男)
73个被试分为三部分:训练training、验证validation、测试test。健康被试分为两组:训练80%、验证20%。31个运动障碍为测试。
基于ERP的矩阵拼写器(row-column paradigm RCP)范式
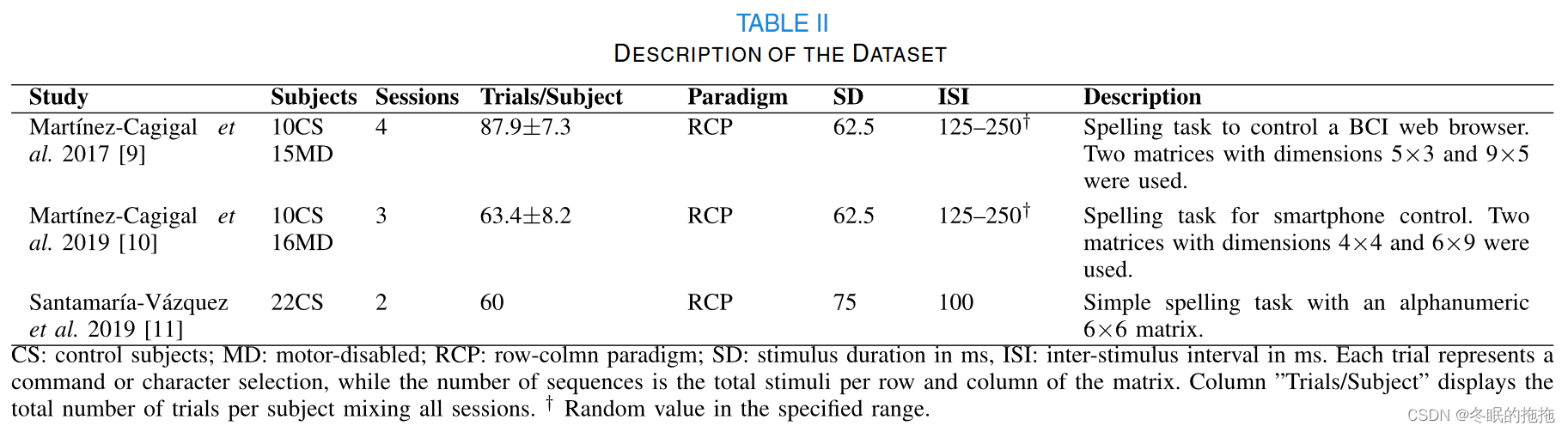
脑电数据采集:采样率256 Hz,导联数8(Fz, Cz, Pz, P3, P4, PO7, PO8 and Oz),FPz作为地,耳垂为参考电极,导联位置按照国际10-20标准。
信号预处理:降采样到128 Hz;采用通带为0.5-45 Hz的带通滤波器;重参考,使用共平均参考;对数据进行切分,从刺激开始时刻到之后的1000 ms为止。
输入模型的EEG为大小 128×8(时间×空间OR采样点×通道、导联)的数组。
方法
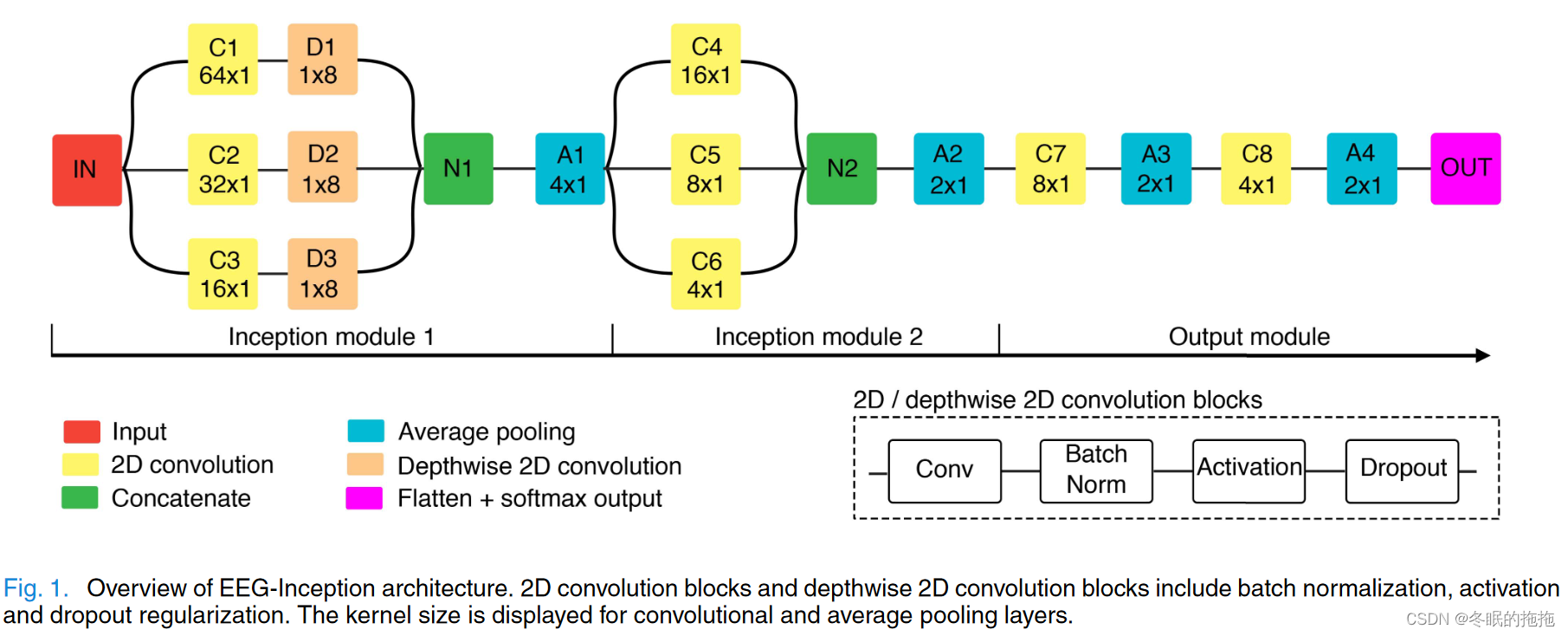
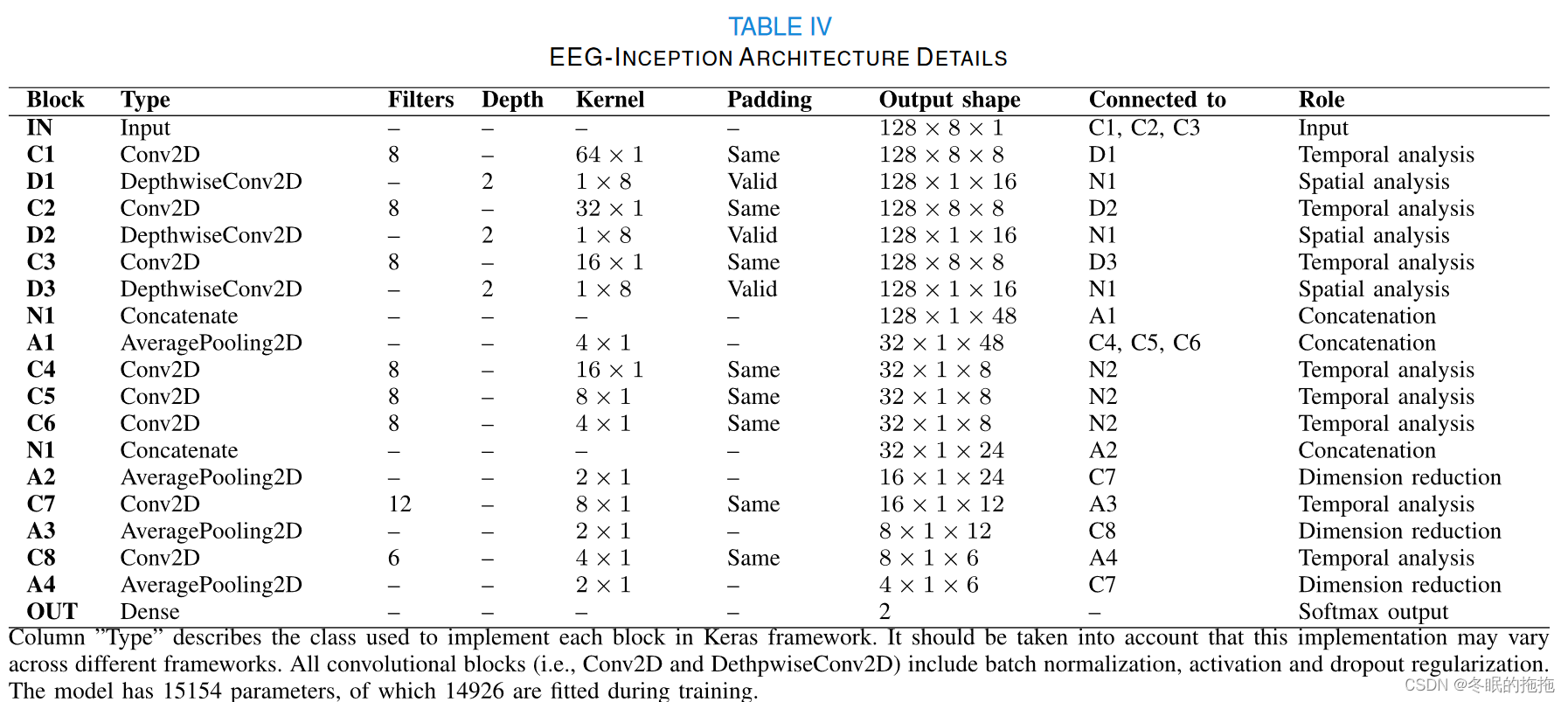
EEG-Inception网络结构上包含了2个Inception模块、1个output模块(2个卷积层、最后全连接层分类)。
Inception module 1: 卷积核C1、2、3对信号进行3种时间维度的特征提取,输入采样率128Hz,每个卷积对应500、250、125ms的时间窗。D1、2、3卷积层进行导联维度的深度卷积。N1将输出拼接。A1进行平均池化降低维度。
Inception module 2: 在更高的特征抽象层次提取所有导联的时序特征。卷积核C4、5、6对应500、250、125ms的时间窗。N2拼接输出,A2平均池化降低维度。
Output module: 将信息压缩为少数的几个特征。卷积层C7、8用于提取特征中对分类有用的模型,A3、4平均池化降低维度,最后全连接+softmax分类(目标、非目标)输出(估计每个类别的概率)。(滤波器数量递减,和平均池化层一起降维,避免过拟合)
模型训练配置:Adam optimizer with default hyperparameters β1 = 0.9and β2 = 0.999 [38]; categorical cross entropy loss function [39]; mini-batch size of 1024; and 500 epochs.
实验结果
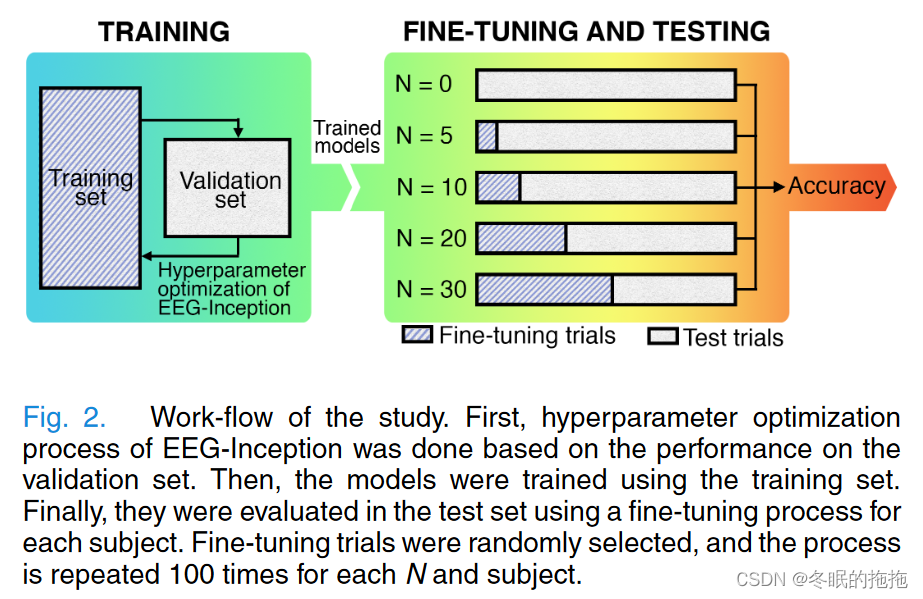
先在验证集上进行EEG-Inception的超参数优化,用训练集完成模型训练。
然后测试,被试随机抽取N个trial的脑电数据,对模型进行fine-tuning,再测试被试剩余的数据上进行测试获得最后的精度。
微调fine-tuning过程:从每个被试中随机选N个trial;训练的模型与这些数据进行微调,获得该被试的特定模型;微调模型与每个被试的其余实验一起测试,对每个N和被试重复100次,平均结果。N是微调次数
结果
测试集指令解码精度
模型是使用单个刺激对应的观测值(即EEG epoch)进行训练和测试的。
命令解码过程遵循单刺激方法:预测单个epoch的概率,然后对每行和每列进行平均。然后选择概率较大的行和列对应的命令。
模型的输入为刺激引发的脑电样本(128×8,文中称observation, eeg epoch),但是对于矩阵拼写器,经过一轮行列的闪烁才能确定想要拼写的字符。
表中的指令解码精度为不同fine-tuning数量(n)情况下,使用No.Sequences轮的数据,实现拼写字符判断的正确率。

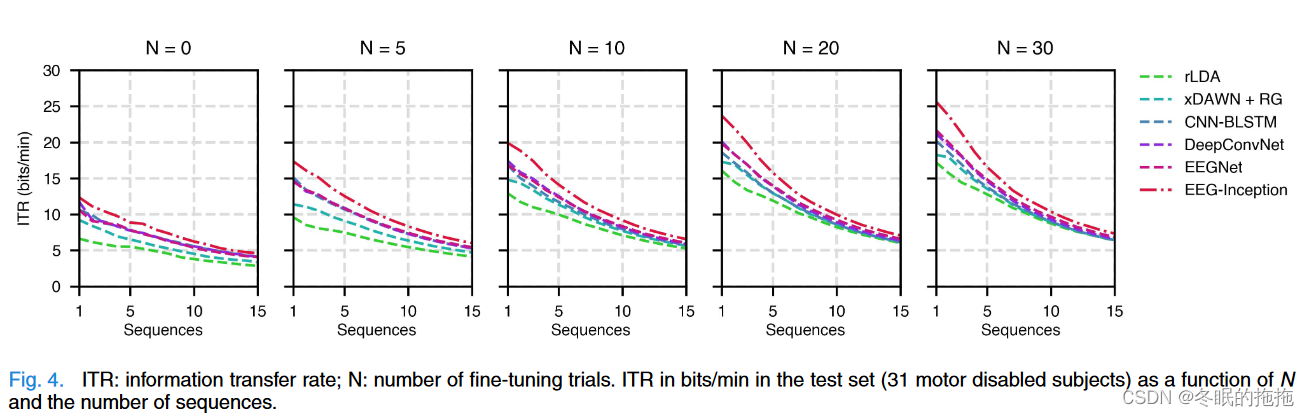
信息传输速率
N越大 IRT越大
参考
https://zhuanlan.zhihu.com/p/486009520















 6285
6285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









