






测试在实现半加器和全加器的基础上开始实现多位数的加法器
一、顺序加法器
可以按照一位全加器,然后循环实现多位加法器。
1、4位加法器 verilog代码
`timescale 1ns / 1ps
module mul_bit_add(
input [3:0] A,
input [3:0] B,
input Ci1,
output [3:0] SUM,
output Ci
);
reg carry;
reg [3:0] SUM_reg;
always @(*) begin
SUM_reg[0] = A[0] ^ B[0] ^ Ci1;
carry = (A[0] & Ci1) | (A[0] & B[0]) | (B[0] & Ci1);
for(integer i=1; i<=3; i= i+1) begin
SUM_reg[i] = A[i] ^ B[i] ^ carry;
carry = (A[i] & carry) | (A[i] & B[i]) | (B[i] & carry);
end
end
assign SUM = SUM_reg;
assign Ci = carry;
endmodule2、testbench
`timescale 1ns / 1ps
module mul_bit_add_tb(
);
reg [3:0] A;
reg [3:0] B;
reg Ci1;
wire[3:0] SUM;
wire Ci;
mul_bit_add mul_bit_add1(
.A(A),
.B(B),
.Ci1(Ci1),
.SUM(SUM),
.Ci(Ci)
);
initial begin
A = 4'b0001;
B = 4'b1000;
Ci1 = 1;
#10
$display("A = %d, B = %d, Ci1 = %d, SUM = %d, Ci = %d",A,B,Ci1,SUM,Ci);
A = 4'b1111;
B = 4'b1;
Ci1 = 0;
#10
$display("A = %d, B = %d, Ci1 = %d, SUM = %d, Ci = %d",A,B,Ci1,SUM,Ci);
A = 4'b1001;
B = 4'b1111;
Ci1 = 0;
#10
$display("A = %d, B = %d, Ci1 = %d, SUM = %d, Ci = %d",A,B,Ci1,SUM,Ci);
end
endmodule3、测试结果:
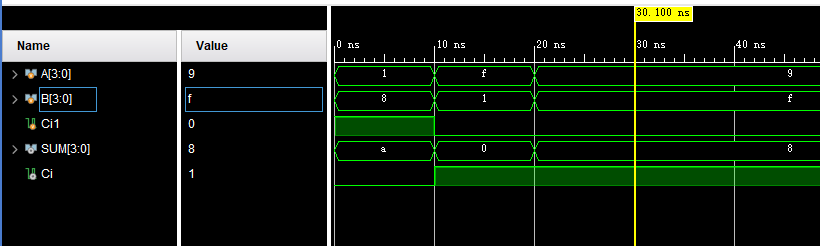
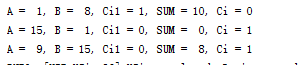
相加正确,功能正确。
4、RTL实现
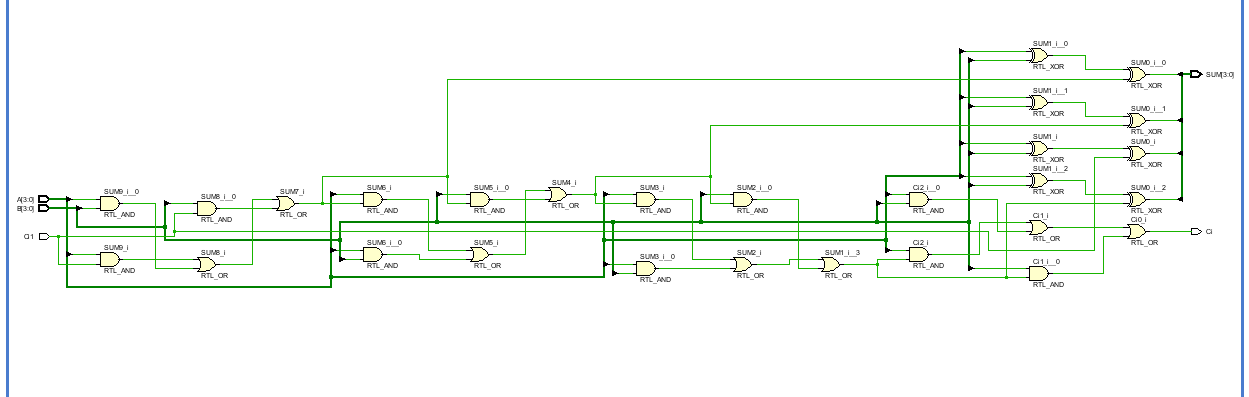
可能看不太清,但是基本就是按照与、或、异或进行连接,而且是串行实现的。
5、综合结果如图
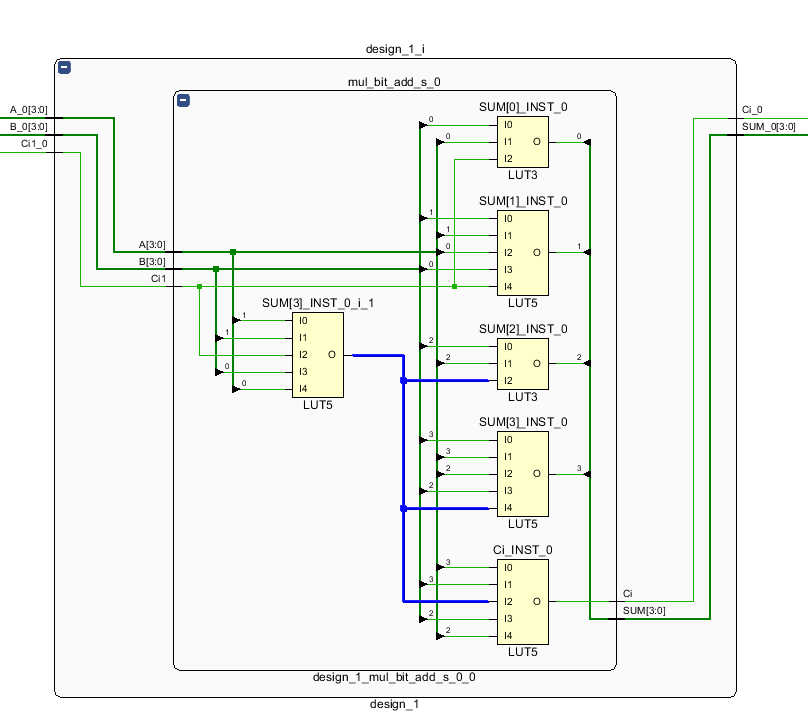
分析可知,工具使用两个查找表(SUM[0]_INST_0,SUM[1]_INST_0)实现了A[1:0]+B[1:0]+Ci1 =》 sum[1:0]的计算,并用一个查找表(SUM[3]_INST_0_i_1)实现低两位相加产生进位的结果,如图中蓝色线;然后计算高两位相加的结果,用两个查找表(SUM[2]_INST_0,SUM[3]_INST_0)实现,最终输出的进位只需要考虑高位相加的结果,使用一个查找表(Ci_INST_0)实现,总共花费6个查找表。
6、实现:
在板卡上也是6个查找表实现
二、并行加法器
超前进位加法器(carry-look-ahead-adder),通过预先计算每一位的进位,减少进位的传递时延,从而更快产生加法结果。
一位加法器真值表
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
1、真值表达式:
公式1
令
公式2
其中P(progagate)代表传递进位,G(generate)代表生成进位,生成进位代表输入两位相加是否会产生进位,传递进位代表地位的进位是否会传递到高位。由公式2可知P、G的值只由两个输出相加数的每位决定,可以同时算出。
则
公式3
,
其中S很好计算,C的真值表达式如下:
公式4
由公式4可知,每位的进位可以不需要知道中间进位结果,直接通过输入进位以及P、G的值便可得到每位的进位,对比原本串行计算减少了进位结果等待的过程,所以被称为超进位。
其中,
根据,所以
公式5
2、4位加法器 verilog代码
`timescale 1ns / 1ps
module adder1(//一位全加器
input X,
input Y,
input Ci1,
output S,
output P,
output G
);
//真值表达公式2
assign P = X ^ Y;
assign G = X & Y;
//真值表达公式3
assign S = X ^ Y ^ Ci1;
endmodule
module CLA_4(//超前进位加法器
input [3:0] P,
input [3:0] G,
input Ci1,
output [3:0] Cout,
output Pout,
output Gout
);
//真值表达公式4
assign Cout[0] = G[0] | (P[0]&Ci1);
assign Cout[1] = G[1] | (P[1]&G[0]) | (P[1]&P[0]&Ci1);
assign Cout[2] = G[2] | (P[2]&G[1]) | (P[2]&P[1]&G[0]) | (P[2]&P[1]&P[0]&Ci1);
assign Cout[3] = G[3] | (P[3]&G[2]) | (P[3]&P[2]&G[1]) | (P[3]&P[2]&P[1]&G[0]) | (P[3]&P[2]&P[1]&P[0]&Ci1);
//真值表达公式5
assign Pout = P[3]&P[2]&P[1]&P[0];
assign Gout = G[3] | (P[3]&G[2]) | (P[3]&P[2]&G[1]) | (P[3]&P[2]&P[1]&G[0]);
endmodule
module CLA_add(
input [3:0] X,
input [3:0] Y,
input Ci1,
output [3:0] S,
output Pout,
output Gout,
output Cout
);
wire [3:0] P;
wire [3:0] G;
wire [3:0] C;
adder1 adder1_0(
.X(X[0]),
.Y(Y[0]),
.Ci1(Ci1),
.S(S[0]),
.P(P[0]),
.G(G[0])
);
adder1 adder1_1(
.X(X[1]),
.Y(Y[1]),
.Ci1(C[0]),
.S(S[1]),
.P(P[1]),
.G(G[1])
);
adder1 adder1_2(
.X(X[2]),
.Y(Y[2]),
.Ci1(C[1]),
.S(S[2]),
.P(P[2]),
.G(G[2])
);
adder1 adder1_3(
.X(X[3]),
.Y(Y[3]),
.Ci1(C[2]),
.S(S[3]),
.P(P[3]),
.G(G[3])
);
CLA_4 CLA_4_1(
.P(P),
.G(G),
.Ci1(Ci1),
.Cout(C),
.Pout(Pout),
.Gout(Gout)
);
assign Cout = C[3];
endmodule
参考结构夏宇闻《verilog 数字系统设计教程第三版》第十章

3、testbench
`timescale 1ns / 1ps
module CLA_add_tb(
);
reg [3:0] A;
reg [3:0] B;
reg Ci1;
wire[3:0] S;
wire P;
wire G;
wire Cout;
CLA_add CLA_add1(
.X(A),
.Y(B),
.Ci1(Ci1),
.S(S),
.Pout(P),
.Gout(G),
.Cout(Cout)
);
initial begin
A = 4'b0001;
B = 4'b1000;
Ci1 = 1;
#10
$display("A = %d, B = %d, Ci1 = %d, S = %d, Cout = %d",A,B,Ci1,S,Cout);
A = 4'b1111;
B = 4'b1;
Ci1 = 0;
#10
$display("A = %d, B = %d, Ci1 = %d, S = %d, Cout = %d",A,B,Ci1,S,Cout);
A = 4'b1001;
B = 4'b1111;
Ci1 = 0;
#10
$display("A = %d, B = %d, Ci1 = %d, S = %d, Cout = %d",A,B,Ci1,S,Cout);
end
endmodule4、测试结果:
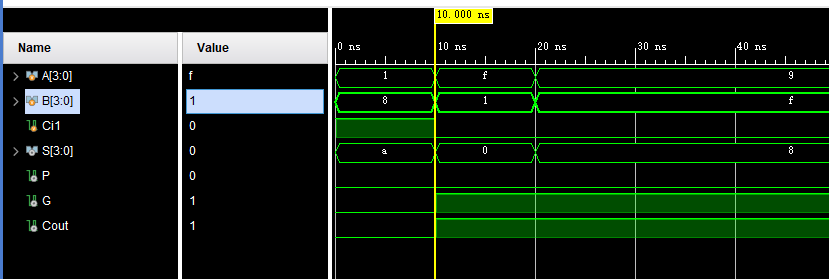
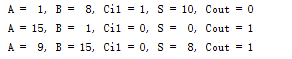
功能正确
5、RTL实现
整体结构如下,基本与参考结构相同
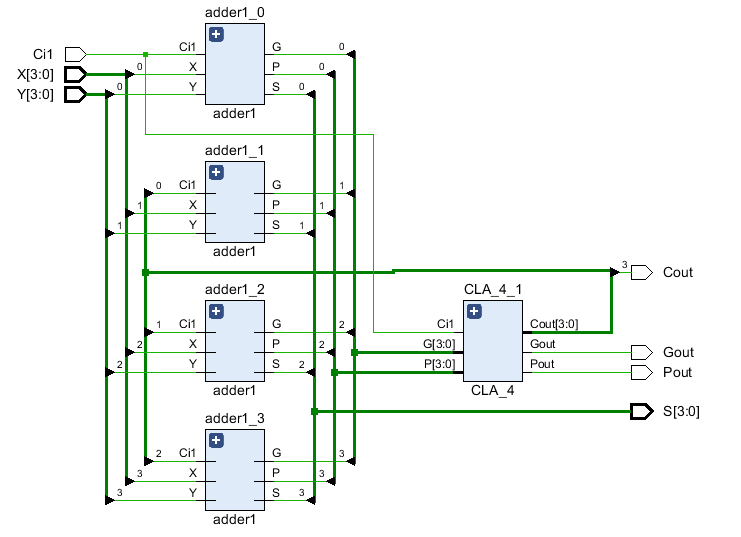
全加器的实现如下:
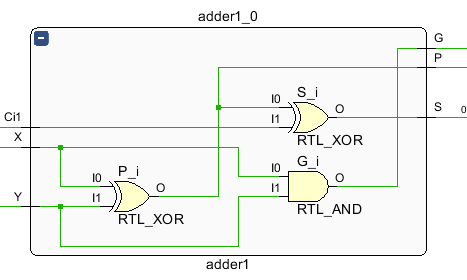
基本按照表达式实现的电路。
超进位结构如下:
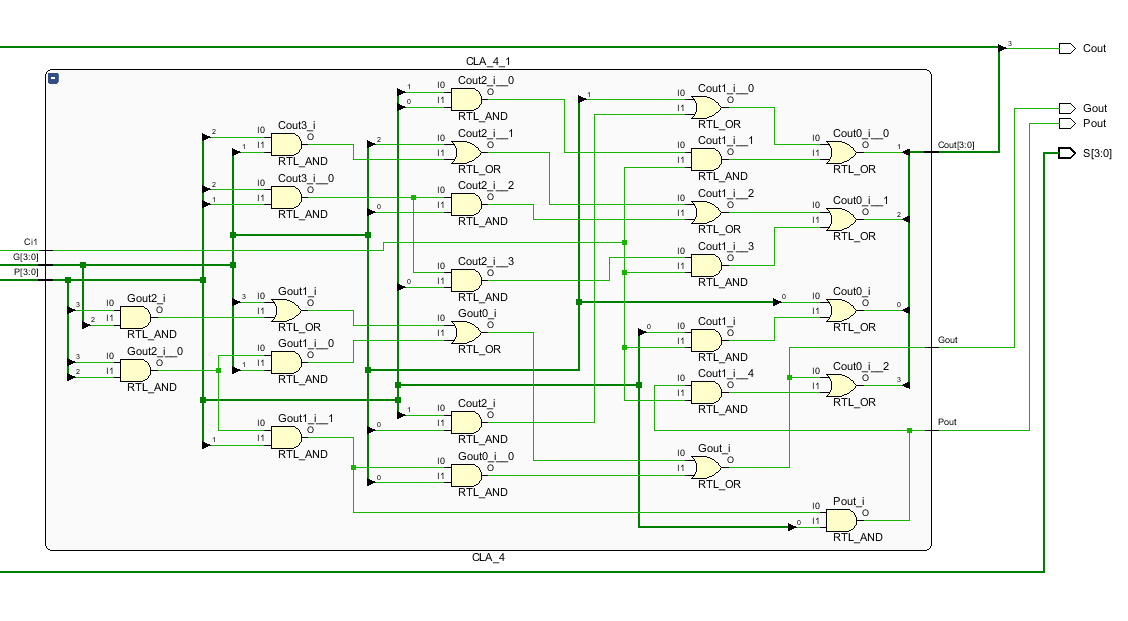
6、综合:
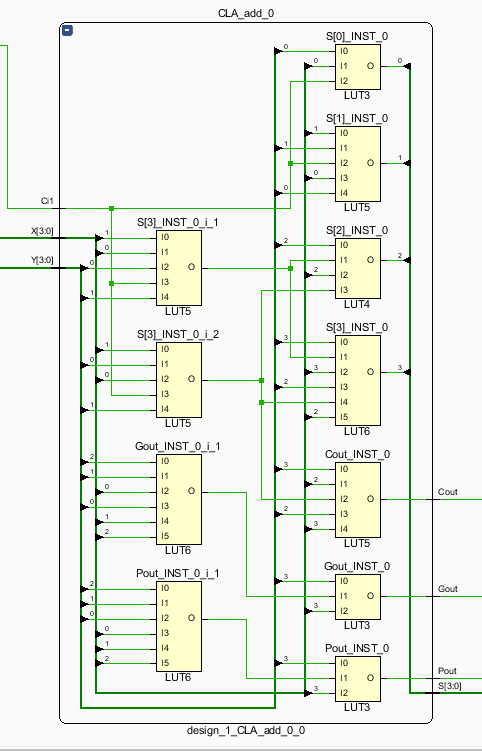
7、实现:
消耗了10个LUT。
有很多地方都分析不了,先做个暂存结果吧。















 7141
7141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









