







 本文详细介绍了半加器、全加器和超前进位加法器的工作原理,以及它们在数字电路设计中的应用,特别是通过Verilog代码展示了这些加法器的实现过程。重点强调了行波进位加法器的串行计算与超前进位加法器的并行计算方式,以及它们的性能优劣和适用场景。
本文详细介绍了半加器、全加器和超前进位加法器的工作原理,以及它们在数字电路设计中的应用,特别是通过Verilog代码展示了这些加法器的实现过程。重点强调了行波进位加法器的串行计算与超前进位加法器的并行计算方式,以及它们的性能优劣和适用场景。
参考【HDL系列】超前进位加法器原理与设计 - 知乎 (zhihu.com)
一、半加器
半加器是最简单的加法器,不考虑进位输入。单bit
真值表:
| A | B | S | CO |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
逻辑表达式:
verilog语言:
assign S=A^B; //按位异或
assign CO=A&B; //按位与二、全加器
全加器考虑进位输入Ci。单bit
真值表:
| A | B | Ci | S | CO |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
逻辑表达式:
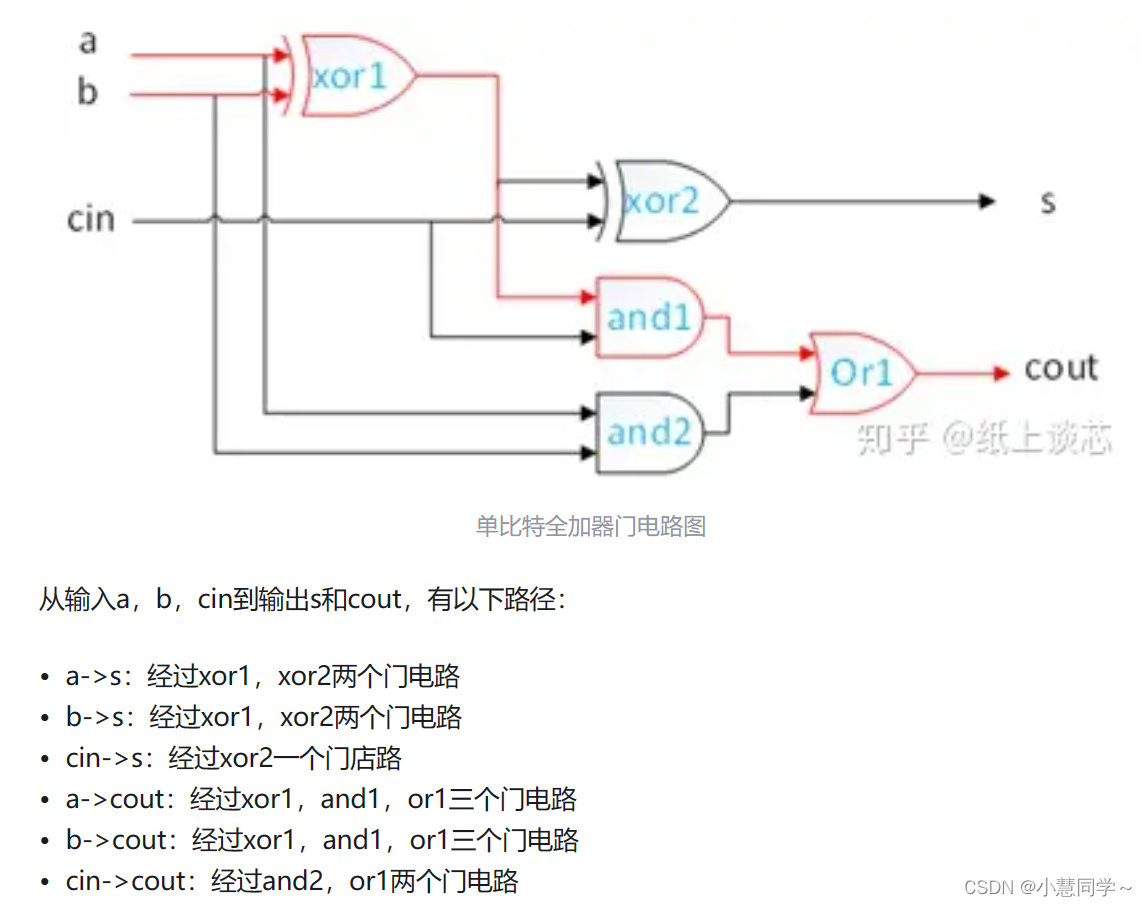
红色是全加器的关键路径。电路的延迟包括门延迟和线延迟等,分析忽略线延迟。
verilog代码:
assign S=A^B^Ci; //按位异或
assign co=(A&B)|((A^B)&Ci); //按位与自己的理解:这里都是按位异或,按位与,如果是多bit的加法器运算,也是先计算低位,再计算高位,同时低位的进位输出是高位的进位输入,因此每一个计算也应该是按位计算,而不是逻辑运算。
三、行波进位加法器(Ripple-carry adder,RCA)
N-bit加法器可以根据1-bit全加器组合而成。每个全加器的输出进位cout作为下一个全加器的输入进位cin,如一个16bit加法器的结构如下图所示,其中A,B为16比特的加数,S为A+B的和,c16为该加法器的输出:
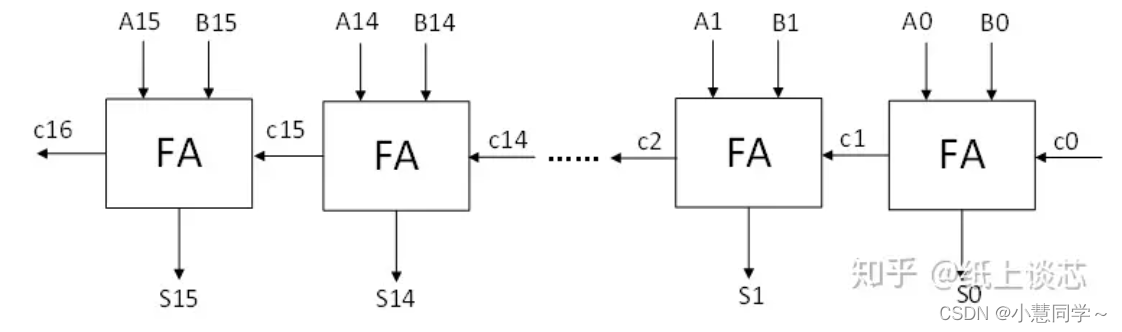
行波进位加法器设计简单,只需要级联全加器即可,但它的缺点在于超长的进位链,限制了加法器的性能。
我的理解:各位的和就是A与B的各位相加,只有进位输出变成下一位计算的进位输入。
verilog代码:
//行波进位加法器RCA
module rca #(parameter WDITH = 16)(
input [WDITH-1:0] a,
input [WDITH-1:0] b,
input cin,
output [WDITH-1:0] sum,
output cout);
wire [WDITH:0] tmp;
assign tmp[0]=cin;
assign cout=tmp[WDITH];
genvar i;
generate
for(i=0;i<WDITH;i=i+1) begin
addr u1 (
.a(a[i]),
.b(b[i]),
.c_i(tmp[i]),
.s(sum[i]),
.c_o(tmp[i+1])
);
end
endgenerate
endmodule
//子模块,全加器
module addr (
input a,
input b,
input c_i,
output s,
output c_o );
assign s=a^b^c_i;
assign c_o=(a&b)|((a^b)&c_i);
endmodule测试用例:
//行波加法器的测试用例
`timescale 1ns/1ns
module rca_tb ();
parameter WDITH=16;
reg [WDITH-1:0] a;
reg [WDITH-1:0] b;
reg cin;
wire [WDITH-1:0] sum;
wire cout;
initial begin
a=16'b0100_1111_0000_0001;
b=16'b0001_0010_1110_1110;
cin=1'b1;
#400;
a=16'b0100_1111_0000_0001;
b=16'b0001_0010_1110_0000;
cin=1'b0;
end
rca u_rca(
.a(a),
.b(b),
.cin(cin),
.sum(sum),
.cout(cout)
);
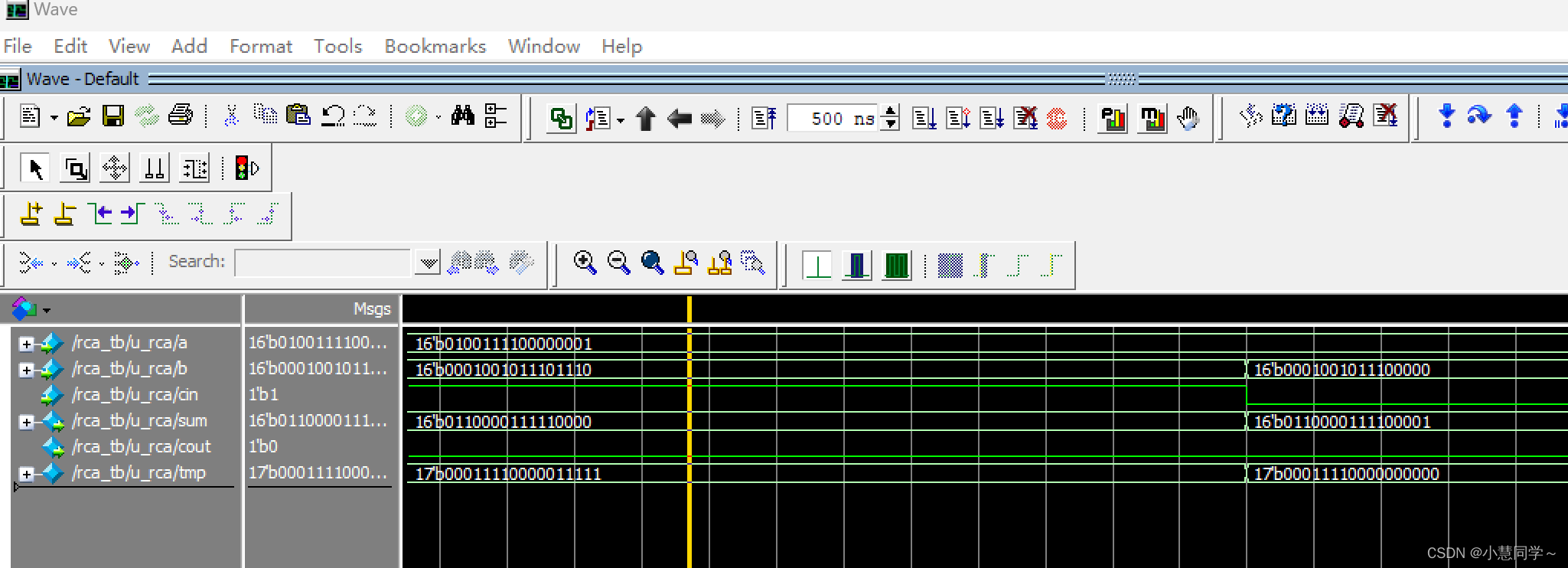
endmodule仿真波形:
四、超前进位加法器(Lookahead Carry Adder,LCA)
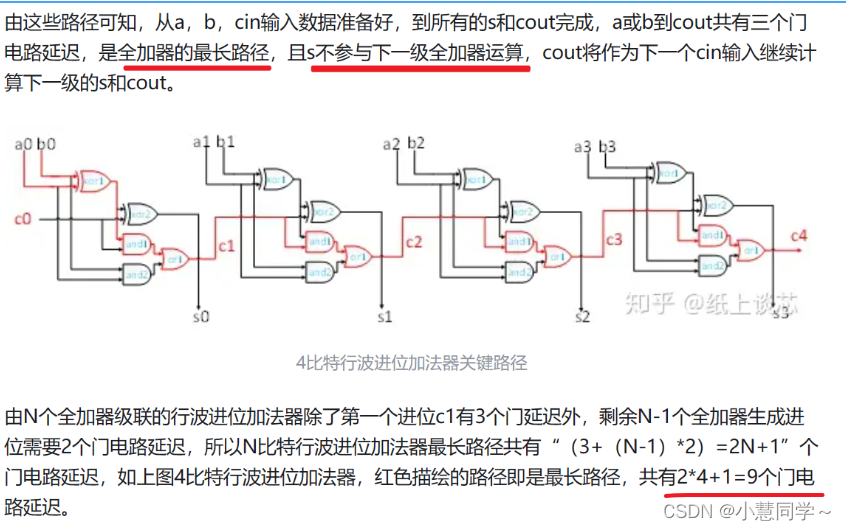
超前进位加法器优化改进行波进位器的关键路径。RCA的缺点在于第k位的进位Ck必须依赖于前一级的Ck-1,所以最高位的进位将必须等待之前所有级进位计算完毕后才能计算出结果。
超前进位加法器的思想是并行计算进位Ck
就是提前把进位计算好,按照逻辑表达式连线,并行计算进位;而之前的行波进位加法器(RCA)是串行计算。
之前全加器逻辑表达式:
观察上式,共有部分分别定义:
以4bitLCA加法器为例,其进位链和公式计算:
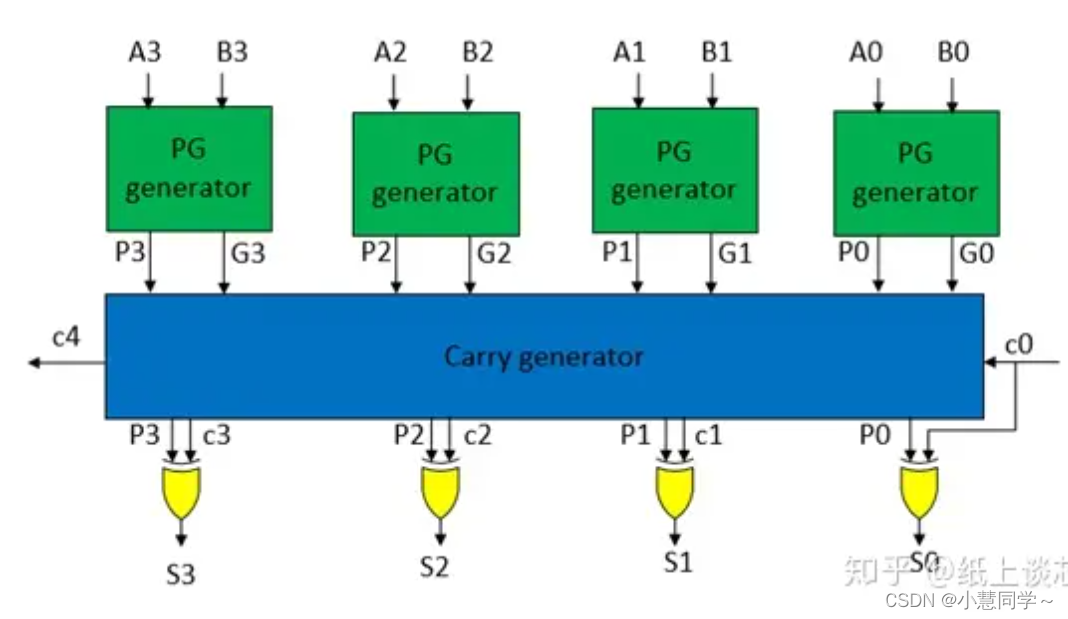
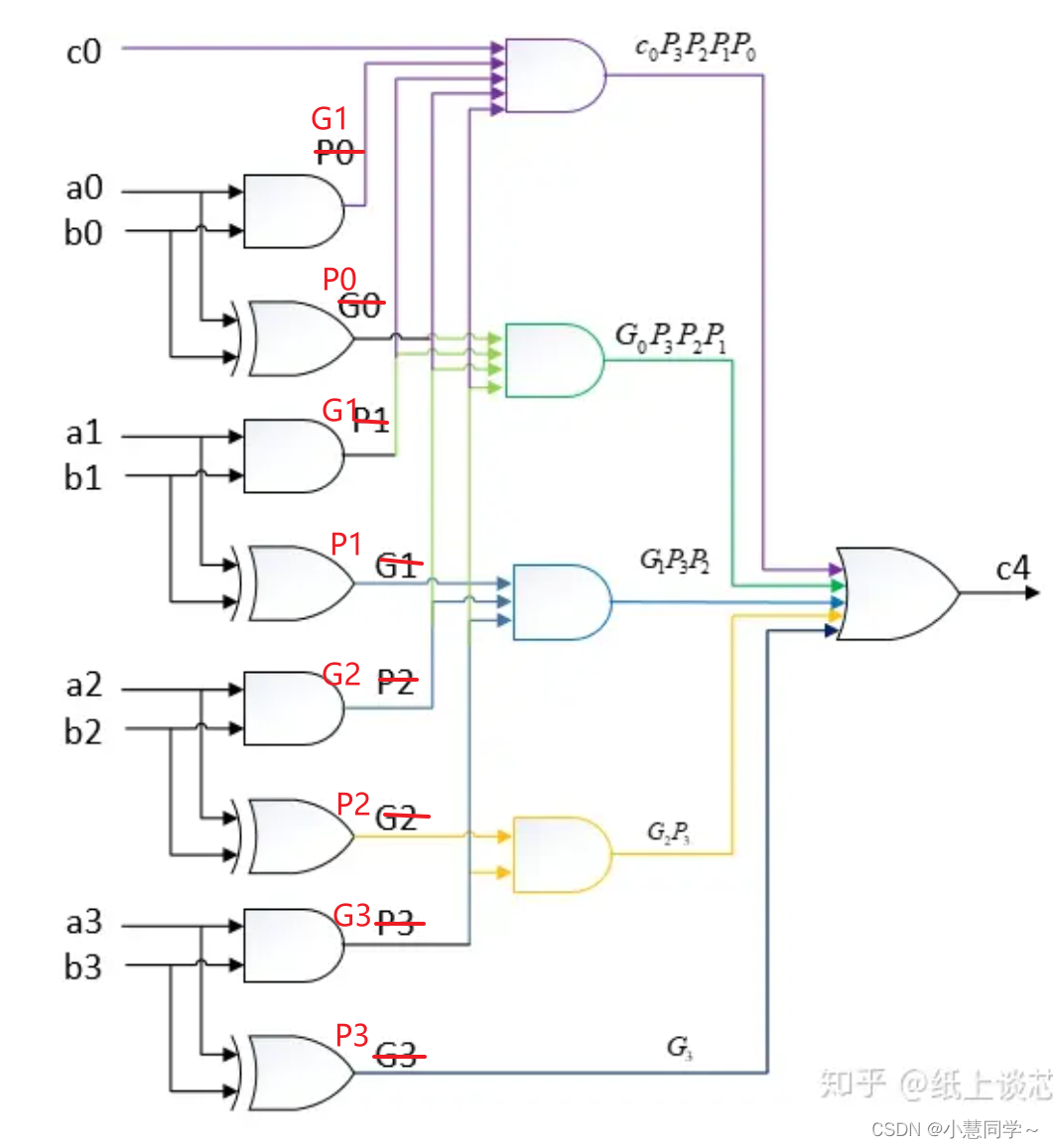
RCA的缺点在于关键路径长,限制了速度,性能不高;LCA关键路径短,速度快,进位链计算依赖少,但对于位宽较大的加法器,PG和进位生成逻辑大,变化信号多,会有较多的glitch,且面积与复杂度比同等的RCA大。
verilog代码:
//4bit超前进位加法器
`timescale 1ns/1ns
module lca(
input [3:0] A_in ,
input [3:0] B_in ,
input C_1 ,
output wire CO ,
output wire [3:0] S
);
wire [3:0] G;
wire [3:0] P;
assign G[0]=A_in[0]&B_in[0];
assign G[1]=A_in[1]&B_in[1];
assign G[2]=A_in[2]&B_in[2];
assign G[3]=A_in[3]&B_in[3];
assign P[0]=A_in[0]^B_in[0];
assign P[1]=A_in[1]^B_in[1];
assign P[2]=A_in[2]^B_in[2];
assign P[3]=A_in[3]^B_in[3];
assign CO=G[3]||(P[3]&G[2])||(P[3]&P[2]&G[1])||(P[3]&P[2]&P[1]&G[0])||(P[3]&P[2]&P[1]&P[0]&C_1);
assign S[0]=P[0]^C_1;
assign S[1]=P[1]^(G[0]|(C_1&P[0]));
assign S[2]=P[2]^(G[1]|(P[1]&G[0])|(P[1]&P[0]&C_1));
assign S[3]=P[3]^(G[2]|(P[2]&G[1])|(P[2]&P[1]&G[0])|(P[2]&P[1]&P[0]&C_1));
endmodule//超前进位加法器测试用例
`timescale 1ns/1ns
module lca_4_tb(
);
reg [3:0] A_in;
reg [3:0] B_in;
reg C_1;
wire C0;
wire [3:0] S;
initial begin
A_in=4'b0100;
B_in=4'b0010;
C_1=1'b1;
#40;
C_1=1'b0;
$stop;
end
lca u1(.A_in(A_in),.B_in(B_in),.C_1(C_1),.CO(CO),.S(S));
endmodule仿真波形:
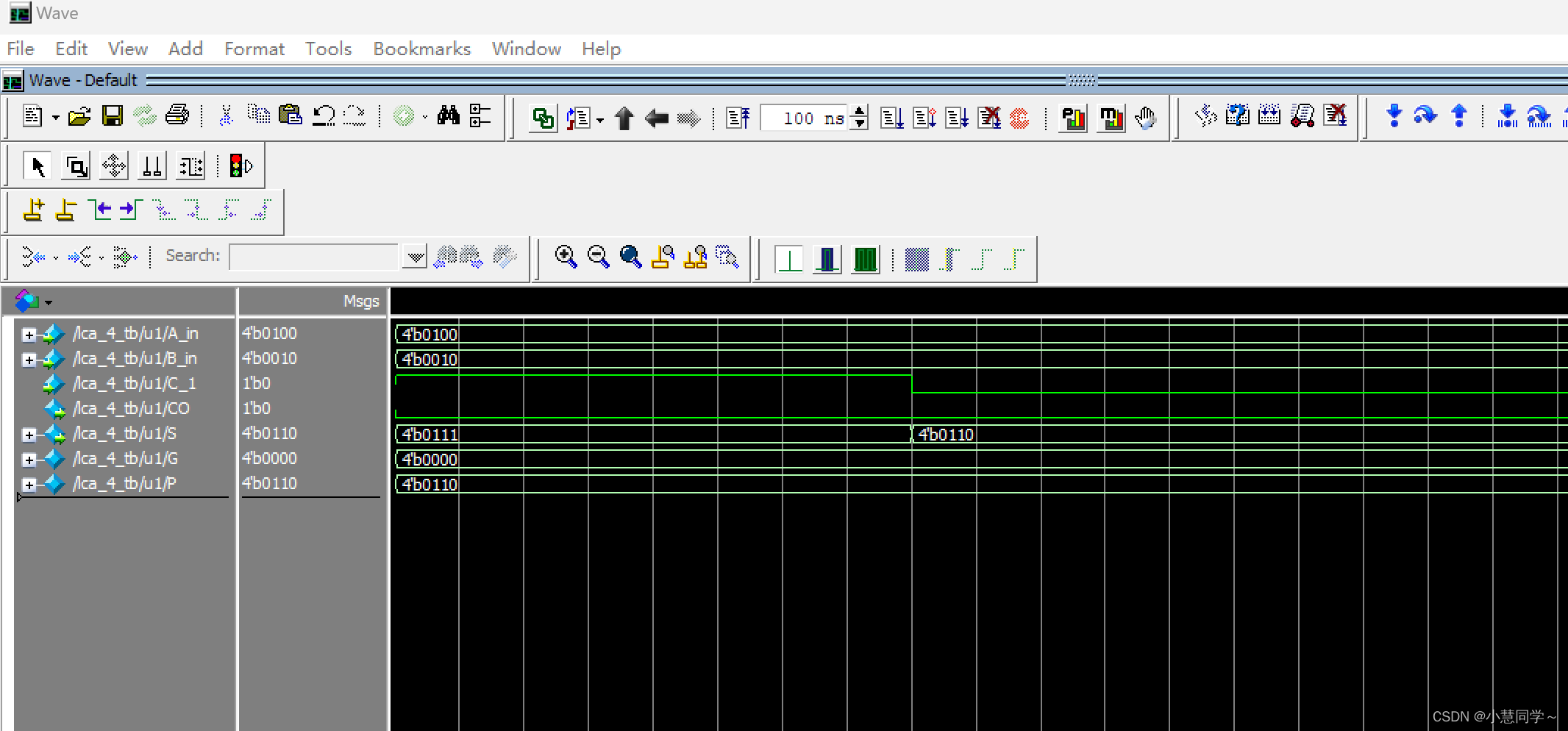















 3742
3742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









