






ELECTRA
一、 ELECTRA是什么
ELECTRA是谷歌提出的一种预训练模型。全称(Efficiently Learning an Encoder that Classifies Token Replacements Accurately.)
论文:ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
使用判别式而非生成式的预训练文本编码器。
二、 ELECTRA模型结构
整体结构如下图所示:
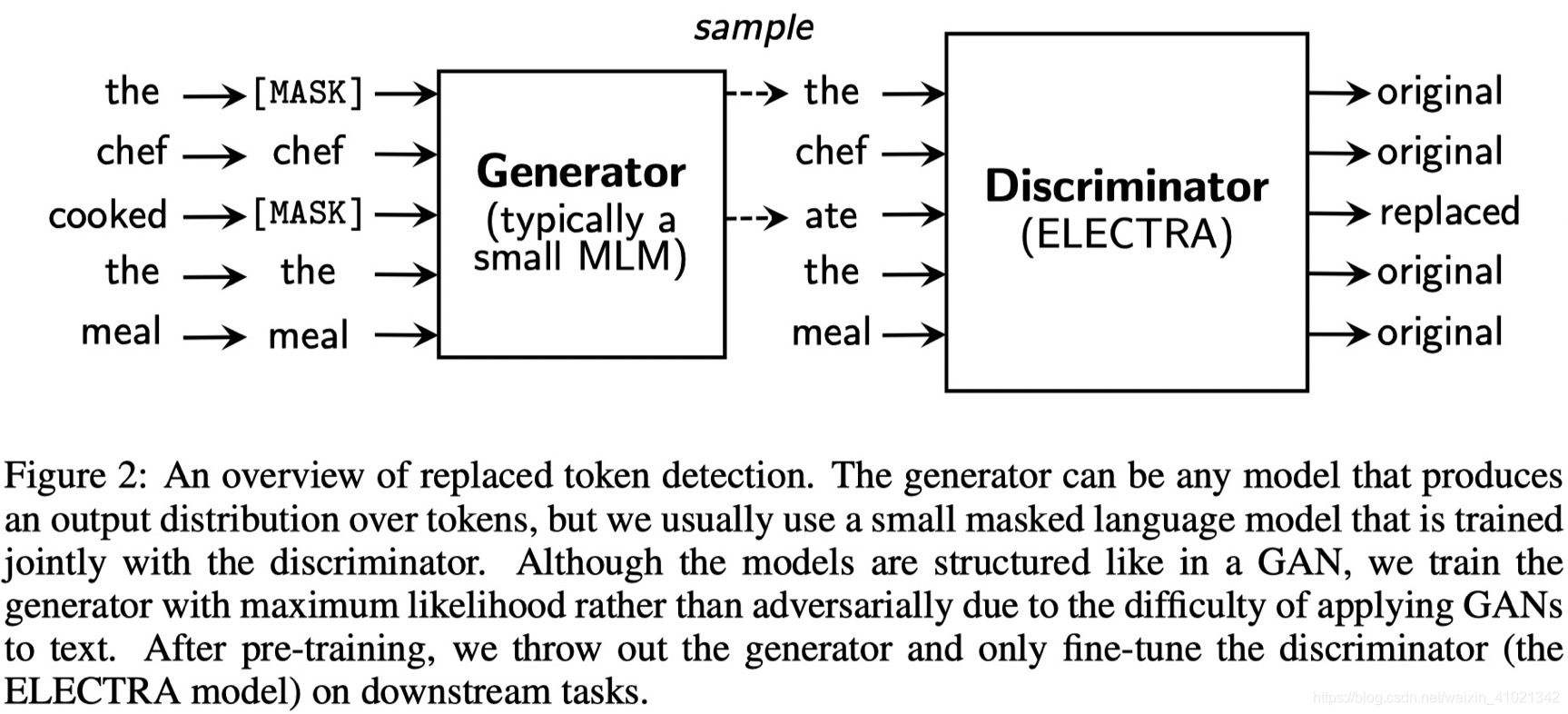
借鉴了对抗网络的思想,共训练两个神经网络模型
左边生成器Generator:
随机屏蔽原始文本中的单词,进行预测学习。
右边判别器Discriminator:
判定单词是否与原始文本一致,如果一致则为真,如果不同则为假。
三、ELECTRA模型如何训练
采用联合训练的方法,但与对抗网络不同的时,参数不在生成器和判别器中反向传播,只共享embedding。embedding大小和判别器的隐层一致。
1.训练生成器n步
2.根据生成器参数初始化判别器,冻结生成器参数,同样训练判别器 n步。
训练完成后丢弃生成器,使用判别器进行下游任务的微调。
模型大小,更小的生成器效果更好,实验证明生成器为判别器的1/2或1/4效果最好。
与对抗网络的区别:
生成器使用最大似然估计训练,而非对抗式训练
当生成器生成与原始文本一致的单词时,判别器的预测标签为“真”。(在对抗网络中,如果是生成器生成的则判别器判定为“假”)
四、ELECTRA 优点
优点:比Bert 模型更小,效率更高,效果更好。计算耗时1 GPU in 4 days

















 2098
2098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









