







目录
YOLOv7算法分析
YOLOv7作为YOLO系列的成员,以其卓越的速度和精度在目标检测领域引起了广泛关注。以下是对YOLOv7的详细介绍:
-
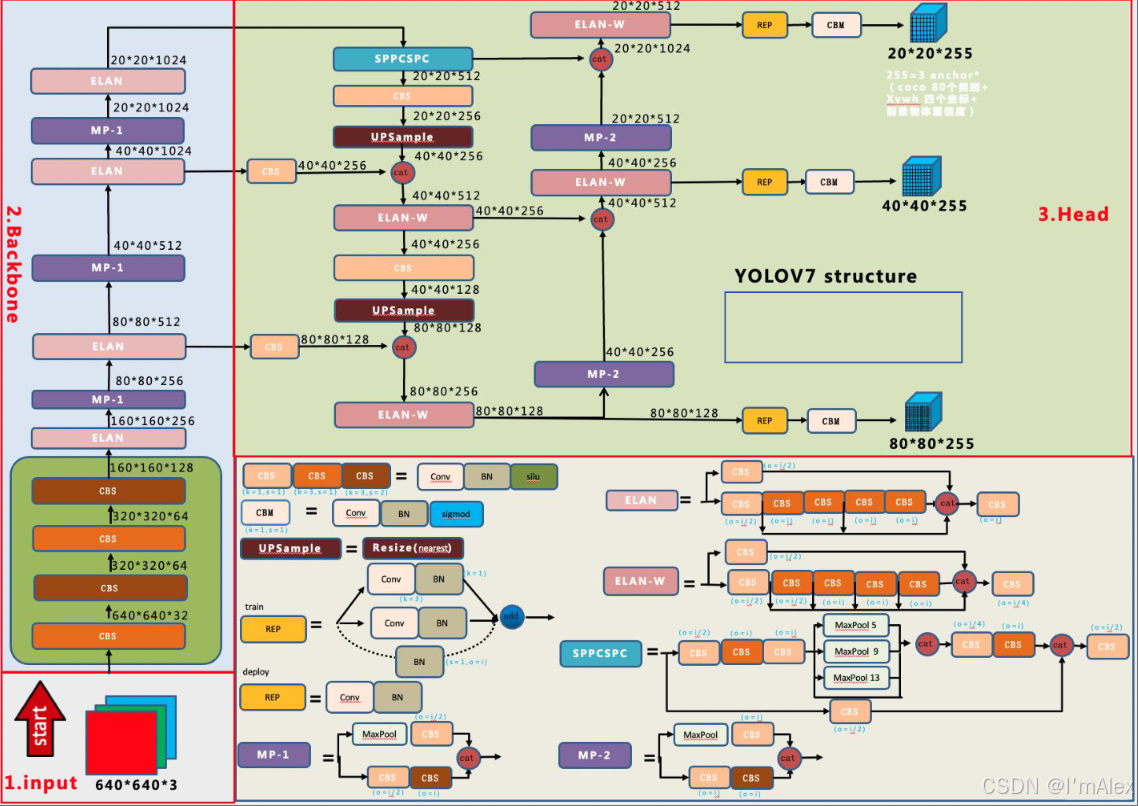
网络结构:YOLOv7的网络结构主要包括输入处理、Backbone网络、Head层网络以及输出处理。输入图像首先被调整为640x640的大小,然后通过具有50层的Backbone结构,特征图大小变为160x160x128。Head层网络输出三层不同大小的feature map,经过进一步处理后输出预测结果。最终,输出处理阶段为每个预测目标生成包含坐标位置、尺寸和类别信息的向量 。
-
性能优势:YOLOv7在速度和精度上均优于其他目标检测器。例如,与基于transformer的检测器相比,YOLOv7的速度高出509%,精度高出2%。与其他目标检测器相比,如YOLOR、YOLOX等,YOLOv7也展现出明显的优势 。
-
技术要点:YOLOv7引入了四大技术要点,包括模型重参数化、标签分配策略、ELAN高效网络架构以及带辅助头的训练。模型重参数化提升了模型的表达能力;标签分配策略提高了检测的准确性;ELAN网络架构降低了模型的计算复杂度;带辅助头的训练方法通过增加训练成本提升精度,同时不影响推理速度 。
-
新功能:YOLOv7通过引入多项架构改革提高了速度和准确性。它不使用ImageNet预训练的主干,而是完全使用COCO数据集进行训练。YOLOv7还引入了E-ELAN(扩展高效层聚合网络),这是一种新的计算块,通过expand、shuffle、merge cardinality增强网络学习能力 。
-
模型缩放:YOLOv7执行模型缩放以适应不同的应用需求,考虑分辨率、宽度、深度和阶段等参数,采用复合模型缩放方法,使得宽度和深度是连贯地缩放的 。
-
Bag of FreeBies:YOLOv7引入了可训练的Bag of FreeBies(BoF)方法,这是一种在不增加训练成本的情况下提高模型性能的方法。包括计划重参数化卷积和粗为辅助,细为Lead Loss的多头训练方法 。
-
推理演示:YOLOv7在实际应用中,如视频流的目标检测推理,展现了出色的性能。它能够在不同的硬件平台上运行,从边缘GPU到高端云GPU 。
YOLOv7凭借其创新的设计和优化的性能,成为了目标检测领域的新里程碑,预计将在实际应用中发挥更加重要的作用 。
YOLOv7网络结构图
创新点分析
CoTTransformer
上下文Transformer(Contextual Transformer, CoT)模块是一种新颖的Transformer风格架构,旨在改善视觉识别任务中的注意力机制。CoT模块通过结合静态上下文和动态自注意力学习,充分利用输入键之间的上下文信息来指导动态注意力矩阵的学习,从而加强视觉表征的能力。具体来说,CoT模块首先通过3×3卷积对输入键进行上下文编码,生成静态上下文表示,然后将编码后的键与输入查询合并,通过连续的1×1卷积来学习动态多头注意力矩阵。最终,将静态和动态上下文表示的融合作为输出。CoT模块的优势在于能够作为标准卷积的替代品,直接嵌入到现有的ResNet架构中,形成上下文变换器网络(Contextual Transformer Networks, CoTNet),在多种计算机视觉任务中展现出卓越的性能。
class CoTAttention(nn.Module):
def __init__(self, dim=512, kernel_size=3):
super().__init__()
self.dim = dim
self.kernel_size = kernel_size
self.key_embed = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=kernel_size, padding=kernel_size // 2, groups=4, bias=False),
nn.BatchNorm2d(dim),
nn.ReLU()
)
self.value_embed = nn.Sequential(
nn.Conv2d(dim, dim, 1, bias=False),
nn.BatchNorm2d(dim)
)
factor = 4
self.attention_embed = nn.Sequential(
nn.Conv2d(2 * dim, 2 * dim // factor, 1, bias=False),
nn.BatchNorm2d(2 * dim // factor),
nn.ReLU(),
nn.Conv2d(2 * dim // factor, kernel_size * kernel_size * dim, 1)
)
def forward(self, x):
bs, c, h, w = x.shape
k1 = self.key_embed(x) # bs,c,h,w
v = self.value_embed(x).view(bs, c, -1) # bs,c,h,w
y = torch.cat([k1, x], dim=1) # bs,2c,h,w
att = self.attention_embed(y) # bs,c*k*k,h,w
att = att.reshape(bs, c, self.kernel_size * self.kernel_size, h, w)
att = att.mean(2, keepdim=False).view(bs, c, -1) # bs,c,h*w
k2 = F.softmax(att, dim=-1) * v
k2 = k2.view(bs, c, h, w)
return k1 + k2
本文涉及的完整代码可以到这里获取。
LSKBlock
Large Selective Kernel Network (LSKNet)是一种面向遥感目标检测任务的新型网络结构,它通过动态调整大空间感受野来适应不同类型遥感对象所需的不同范围的上下文信息。LSKNet的核心是大核心选择(LK Selection)子块和前馈网络(FFN)子块,其中LK Selection子块利用一系列分解的大核心卷积和空间选择机制来有效建模对象的长距离依赖性,而FFN子块则负责通道混合和特征细化。LSKNet在标准的遥感基准测试中取得了新的最佳成绩,证明了其在处理具有独特先验知识的遥感图像方面的有效性。
class LSKblock(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim // 2, 1)
self.conv2 = nn.Conv2d(dim, dim // 2, 1)
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3)
self.conv = nn.Conv2d(dim // 2, dim, 1)
def forward(self, x):
attn1 = self.conv0(x)
attn2 = self.conv_spatial(attn1)
attn1 = self.conv1(attn1)
attn2 = self.conv2(attn2)
attn = torch.cat([attn1, attn2], dim=1)
avg_attn = torch.mean(attn, dim=1, keepdim=True)
max_attn, _ = torch.max(attn, dim=1, keepdim=True)
agg = torch.cat([avg_attn, max_attn], dim=1)
sig = self.conv_squeeze(agg).sigmoid()
attn = attn1 * sig[:, 0, :, :].unsqueeze(1) + attn2 * sig[:, 1, :, :].unsqueeze(1)
attn = self.conv(attn)
return x * attn
DCNv2
Deformable convolution V2(DCNv2)是卷积神经网络中的一项创新技术,它通过在标准卷积操作中引入额外的可学习偏移量,允许卷积核根据输入特征图的内容动态调整其采样位置。这种动态调整赋予了网络更强的几何变换建模能力,特别是在处理目标物体的形状变化时。DCNv2进一步引入了调制机制,不仅调整采样位置,还调节每个采样点的特征增益,使得网络能够更精细地控制哪些特征是重要的。此外,DCNv2采用了特征模仿方案,借鉴了R-CNN网络的分类能力,通过模仿损失来指导网络学习更加聚焦于目标的特征表示。这些改进使得DCNv2在复杂的视觉任务,如COCO数据集上的对象检测和实例分割中,取得了显著的性能提升,超越了其前身DCNv1,并为解决深度学习中几何不变性问题提供了新的视角和解决方案。
class DCNv2(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=1, groups=1, act=True, dilation=1, deformable_groups=1):
super(DCNv2, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = (kernel_size, kernel_size)
self.stride = (stride, stride)
self.padding = (autopad(kernel_size, padding), autopad(kernel_size, padding))
self.dilation = (dilation, dilation)
self.groups = groups
self.deformable_groups = deformable_groups
self.weight = nn.Parameter(
torch.empty(out_channels, in_channels, *self.kernel_size)
)
self.bias = nn.Parameter(torch.empty(out_channels))
out_channels_offset_mask = (self.deformable_groups * 3 *
self.kernel_size[0] * self.kernel_size[1])
self.conv_offset_mask = nn.Conv2d(
self.in_channels,
out_channels_offset_mask,
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
bias=True,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
self.reset_parameters()
def forward(self, x):
offset_mask = self.conv_offset_mask(x)
o1, o2, mask = torch.chunk(offset_mask, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
mask = torch.sigmoid(mask)
x = torch.ops.torchvision.deform_conv2d(
x,
self.weight,
offset,
mask,
self.bias,
self.stride[0], self.stride[1],
self.padding[0], self.padding[1],
self.dilation[0], self.dilation[1],
self.groups,
self.deformable_groups,
True
)
x = self.bn(x)
x = self.act(x)
return x
def reset_parameters(self):
n = self.in_channels
for k in self.kernel_size:
n *= k
std = 1. / math.sqrt(n)
self.weight.data.uniform_(-std, std)
self.bias.data.zero_()
self.conv_offset_mask.weight.data.zero_()
self.conv_offset_mask.bias.data.zero_()
SAConv
Switchable Atrous Convolution (SAC) 是一种创新的卷积技术,它通过将输入特征与不同扩张率(atrous rates)的卷积核对齐,并使用空间依赖的开关函数来聚合结果,从而增强了模型对不同尺度物体的感知能力。SAC的核心在于其灵活性,它允许在保持与预训练标准卷积网络(例如ImageNet预训练模型)兼容性的同时,通过简单的转换机制来增强网络对多尺度特征的捕捉能力。此外,SAC采用了一种新的权重锁定机制,确保了不同扩张卷积之间的权重共享,除了可训练的差异部分。在DetectoRS框架中,SAC通过在底层主干网络中替换所有3x3卷积层,显著提升了目标检测器的性能,同时保持了较高的计算效率。
class SAConv2d(ConvAWS2d):
def __init__(self,
in_channels,
out_channels,
kernel_size,
s=1,
p=None,
g=1,
d=1,
act=True,
bias=True):
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=s,
padding=autopad(kernel_size, p),
dilation=d,
groups=g,
bias=bias)
self.switch = torch.nn.Conv2d(
self.in_channels,
1,
kernel_size=1,
stride=s,
bias=True)
self.switch.weight.data.fill_(0)
self.switch.bias.data.fill_(1)
self.weight_diff = torch.nn.Parameter(torch.Tensor(self.weight.size()))
self.weight_diff.data.zero_()
self.pre_context = torch.nn.Conv2d(
self.in_channels,
self.in_channels,
kernel_size=1,
bias=True)
self.pre_context.weight.data.fill_(0)
self.pre_context.bias.data.fill_(0)
self.post_context = torch.nn.Conv2d(
self.out_channels,
self.out_channels,
kernel_size=1,
bias=True)
self.post_context.weight.data.fill_(0)
self.post_context.bias.data.fill_(0)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
# pre-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(x, output_size=1)
avg_x = self.pre_context(avg_x)
avg_x = avg_x.expand_as(x)
x = x + avg_x
# switch
avg_x = torch.nn.functional.pad(x, pad=(2, 2, 2, 2), mode="reflect")
avg_x = torch.nn.functional.avg_pool2d(avg_x, kernel_size=5, stride=1, padding=0)
switch = self.switch(avg_x)
# sac
weight = self._get_weight(self.weight)
out_s = super()._conv_forward(x, weight, None)
ori_p = self.padding
ori_d = self.dilation
self.padding = tuple(3 * p for p in self.padding)
self.dilation = tuple(3 * d for d in self.dilation)
weight = weight + self.weight_diff
out_l = super()._conv_forward(x, weight, None)
out = switch * out_s + (1 - switch) * out_l
self.padding = ori_p
self.dilation = ori_d
# post-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(out, output_size=1)
avg_x = self.post_context(avg_x)
avg_x = avg_x.expand_as(out)
out = out + avg_x
return self.act(self.bn(out))
DSConv
DSConv是一种高效的卷积操作符,它通过将传统的单精度运算替换为成本更低的整数运算,同时保持卷积核权重和输出的概率分布不变,从而实现对卷积神经网络(CNN)的量化。DSConv通过分解卷积权重,引入一个低精度的组件和一个高精确度的分布偏移组件,以及采用块浮点(Block Floating Point, BFP)方法量化激活值,实现了在不牺牲准确性的前提下,显著减少模型大小和提高推理速度。在不使用标记训练数据的情况下,DSConv能够在4位量化水平下,作为标准卷积的即插即用替代品,实现小于1%的准确度损失。此外,DSConv还展示了通过使用未标记数据进行知识蒸馏适应阶段可以进一步提高结果。这一创新方法为在资源受限的环境中部署高效的神经网络提供了新的可能性。
class DSConv(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=None, dilation=1, groups=1, padding_mode='zeros', bias=False, block_size=32, KDSBias=False, CDS=False):
padding = _pair(autopad(kernel_size, padding))
kernel_size = _pair(kernel_size)
stride = _pair(stride)
dilation = _pair(dilation)
blck_numb = math.ceil(((in_channels)/(block_size*groups)))
super(DSConv, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias, padding_mode)
# KDS weight From Paper
self.intweight = torch.Tensor(out_channels, in_channels, *kernel_size)
self.alpha = torch.Tensor(out_channels, blck_numb, *kernel_size)
# KDS bias From Paper
self.KDSBias = KDSBias
self.CDS = CDS
if KDSBias:
self.KDSb = torch.Tensor(out_channels, blck_numb, *kernel_size)
if CDS:
self.CDSw = torch.Tensor(out_channels)
self.CDSb = torch.Tensor(out_channels)
self.reset_parameters()
def get_weight_res(self):
# Include expansion of alpha and multiplication with weights to include in the convolution layer here
alpha_res = torch.zeros(self.weight.shape).to(self.alpha.device)
# Include KDSBias
if self.KDSBias:
KDSBias_res = torch.zeros(self.weight.shape).to(self.alpha.device)
# Handy definitions:
nmb_blocks = self.alpha.shape[1]
total_depth = self.weight.shape[1]
bs = total_depth//nmb_blocks
llb = total_depth-(nmb_blocks-1)*bs
# Casting the Alpha values as same tensor shape as weight
for i in range(nmb_blocks):
length_blk = llb if i==nmb_blocks-1 else bs
shp = self.alpha.shape # Notice this is the same shape for the bias as well
to_repeat=self.alpha[:, i, ...].view(shp[0],1,shp[2],shp[3]).clone()
repeated = to_repeat.expand(shp[0], length_blk, shp[2], shp[3]).clone()
alpha_res[:, i*bs:(i*bs+length_blk), ...] = repeated.clone()
if self.KDSBias:
to_repeat = self.KDSb[:, i, ...].view(shp[0], 1, shp[2], shp[3]).clone()
repeated = to_repeat.expand(shp[0], length_blk, shp[2], shp[3]).clone()
KDSBias_res[:, i*bs:(i*bs+length_blk), ...] = repeated.clone()
实现过程
环境配置
YOLOv7配置
克隆项目
git clone https://github.com/WongKinYiu/yolov7.git
相关包配置
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
数据集格式转换
数据集格式转换相对简单,可以通过以下链接把voc格式数据集转为yolo格式
CSDN–voc格式数据集转为yolo格式
目录以及代码解释
yolov7-main/
├── cfg/ # 配置目录
│ ├── baseline/ # 基线配置目录
│ ├── deploy/ # 部署配置目录
│ └── training/ # 训练配置目录
│
├── data/ # 数据目录
│ ├── coco.yaml # COCO数据集配置文件
│ ├── hyp.scratch.custom.yaml # 自定义超参数配置文件
│ ├── hyp.scratch.p5.yaml # P5模型超参数配置文件
│ ├── hyp.scratch.p6.yaml # P6模型超参数配置文件
│ └── hyp.scratch.tiny.yaml # Tiny模型超参数配置文件
│
├── deploy/ # 部署目录
│
├── models/ # 模型目录
│
├── utils/ # 工具目录
├── detect.py # 检测代码
├── export.py # 导出代码
│── hubconf.py # hub配置文件
├── requirements.txt # 项目依赖文件
├── test.py # 测试代码
├── train.py # 训练代码
└── train_aux.py # 辅助训练脚本
代码运行
训练命令
--workers 8: 设置训练过程中的工作线程数为8。这可以提高数据加载的效率。--device 0: 指定训练使用的设备编号为0,通常用于GPU编号。--batch-size 32: 设置每个训练批次的样本数量为32。较小的批次大小可以提供更频繁的更新,但可能影响训练稳定性。--data data/coco.yaml: 指定数据集配置文件的路径,这里是data/coco.yaml,它包含了数据集的相关信息和设置。--img 640 640: 设置训练过程中使用的图像尺寸为640x640像素。这通常决定了模型输入的分辨率。--cfg cfg/training/yolov7.yaml: 指定模型配置文件的路径,这里是cfg/training/yolov7.yaml,其中包含了模型架构和训练过程的详细配置。--weights '': 指定预训练权重文件的路径,空字符串表示从头开始训练,不使用预训练权重。--name yolov7: 为本次训练运行指定一个名称,这里是yolov7,用于在保存模型和日志时区分不同的训练。--hyp data/hyp.scratch.p5.yaml: 指定超参数配置文件的路径,这里是data/hyp.scratch.p5.yaml,包含了用于优化训练过程的超参数设置。
python train.py --workers 8 --device 0 --batch-size 32 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml
推理
--weights yolov7.pt: 指定模型权重文件yolov7.pt。--conf 0.25: 置信度阈值设定为25%,意味着只有当预测置信度超过这个值时,结果才会被采纳。--img-size 640: 图像尺寸设置为640x640像素,这通常与模型训练时使用的尺寸一致。--source inference/images/horses.jpg: 指定图像文件horses.jpg作为检测源,该文件位于inference/images/目录下。
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source yourvideo.mp4
python detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --source inference/images/horses.jpg
导出不同格式模型
--weights yolov7-tiny.pt: 指定要导出的模型权重文件,这里是yolov7-tiny.pt。--grid: 启用网格化输出,可能用于模型推理时的并行处理。--end2end: 表示端到端模型导出,包括模型的所有部分。--simplify: 对模型进行简化,移除冗余操作,减小模型大小。--topk-all 100: 在所有类别中选择置信度最高的前100个预测结果。--iou-thres 0.65: 设置IOU(交并比)阈值,用于非极大值抑制(NMS),0.65表示重叠程度超过65%的预测框将被抑制。--conf-thres 0.35: 设置置信度阈值,只有超过这个阈值的预测结果才会被保留。--img-size 640 640: 设置模型输入图像的尺寸为640x640像素。--max-wh 640: 设置输出图像的最大宽度和高度限制为640像素,保持图像尺寸的一致性。
python export.py --weights yolov7-tiny.pt --grid --end2end --simplify \
--topk-all 100 --iou-thres 0.65 --conf-thres 0.35 --img-size 640 640 --max-wh 640
修改步骤
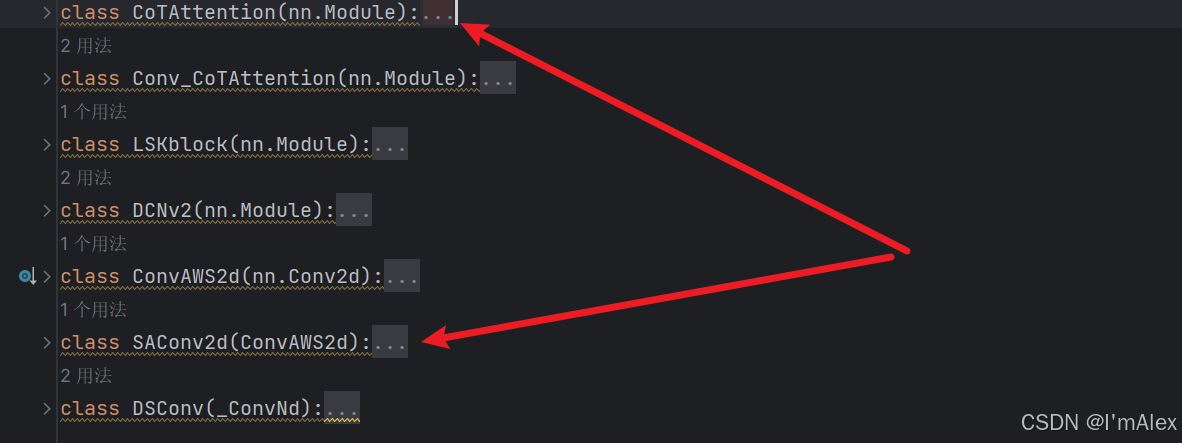
- 有序列表将新模块导入到common.py文件中
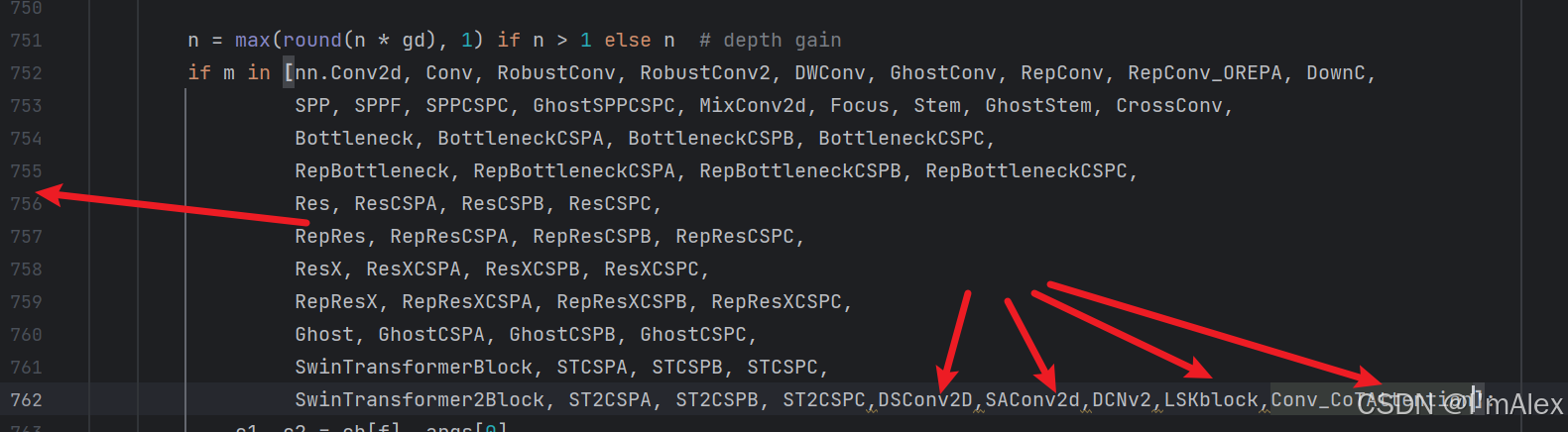
- 将模块名称加入到yolo.py文件中
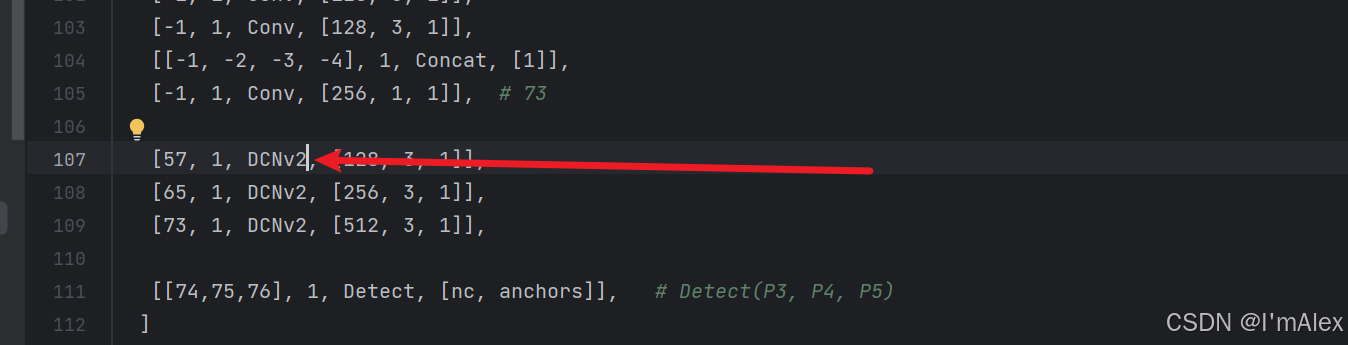
- 在YAML网络结构框架中进行修改
结果展示
无人机数据集训练数据
以上模型创新结果数据
| 模型 | P | R | mAP50 | mAP95 |
|---|---|---|---|---|
| Yolov7-tiny | 0.811 | 0.762 | 0.767 | 0.462 |
| Yolov7-tiny-DSConv2D | 0.839 | 0.779 | 0.793 | 0.489 |
| Yolov7-tiny-SAConv2d | 0.790 | 0.775 | 0.784 | 0.478 |
| Yolov7-tiny-DCNv2 | 0.838 | 0.756 | 0.783 | 0.474 |
| Yolov7-tiny-LSKblock | 0.856 | 0.776 | 0.803 | 0.494 |
| Yolov7-tiny-Conv_CoTAttention | 0.858 | 0.790 | 0.811 | 0.504 |
检测展示


总结
该教程主要包含了注意力机制和卷积模块等方面的创新,所有代码均在附件中,且经过实际的运行试测,均无bug,但创新或者提升针对不同数据集有不同的效果,读者可以反复尝试,另外对于不同的模块可以在网络结构中放置到不同的位置,可以反复尝试确定能够提升的点。



















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











