







在人工智能领域,追求高效与性能的平衡始终是人们孜孜以求的目标。想象一下一个聪明绝顶的语言模型,它不仅能像全精度的大师那般博学多才,还能以超低的内存占用、极低的能耗和闪电般的推理速度驰骋在边缘设备上。这便是BitNet b1.58 2B4T的奇妙世界——一款全新开源的、本身采用1-bit极限量化训练的20 亿参数级语言模型。从最初构思到最终实现,BitNet b1.58 2B4T凭借对极端低精度量化技术的大胆尝试,颠覆了人们对大模型的传统印象,开启了语言模型高效部署的新纪元。
🌍 初探低精度世界:BitNet b1.58 2B4T的诞生
从技术报告的开篇,我们便能感受到一种颠覆传统的力量。开放源代码的语言模型一直是促进人工智能普及和应用研究的重要基石,但与此同时,那些成熟的全精度模型却常常由于庞大的参数量和高昂的运算资源需求,使得它们在边缘设备和资源有限的环境中难以落地应用。BitNet b1.58 2B4T正是在这种背景下应运而生,它以1.58比特的权重存储方式及8比特的激活量化,为大家展示了一种既高效又拥有强大性能的另类进化之路。
“1-bit”的极限量化技术并非简单地将权重压缩为{-1, 0, +1}三种离散值,而是巧妙地结合了绝对均值(absmean)量化方案,将权重映射为理想的三态值。在这种设计下,我们可以将多个三态权重打包存储于单个8位整型数据中,大幅度降低模型内存占用;同时,通过针对每个token独立使用绝对最大值(absmax)策略对激活值进行8比特量化,进一步保证了数值计算的高效性。正如宇宙中的星辰,在有限的空间内释放出无尽的能量,BitNet b1.58 2B4T以其独特的量化理念,推动着低精度模型步入全新纪元。
🛠 架构革新——从Transformer到BitLinear
BitNet b1.58 2B4T的架构基础源自于Transformer模型,但在细节上进行了大胆改造。其最大亮点在于将传统全精度线性层(torch.nn.Linear)替换为定制的BitLinear层。这种变革不仅大幅减少了参数量,更使得模型在前向传播的过程中直接应用1.58比特的权重。具体来说,BitLinear层中的权重采用绝对均值量化策略,使得权重在经过量化后仅有{-1, 0, +1}三个值,这种压缩手段使得模型内存极大降低,而反向传播时则通过恢复原始值的方法保持训练的稳定性。
此外,为了进一步稳定量化训练过程,模型在激活量化上选择了8比特整数表示,并在特定子层中引入了subln归一化方法,这在低比特精度下尤为关键。值得一提的是,在所有线性映射和归一化层中,Bias参数均被移除,这不仅简化了模型结构,更有助于避免量化误差的累积。正如精妙绝伦的天文仪器,一丝不苟地调整每一个细节,BitNet b1.58 2B4T凭借架构上的革新,完美平衡了效率和准确性。
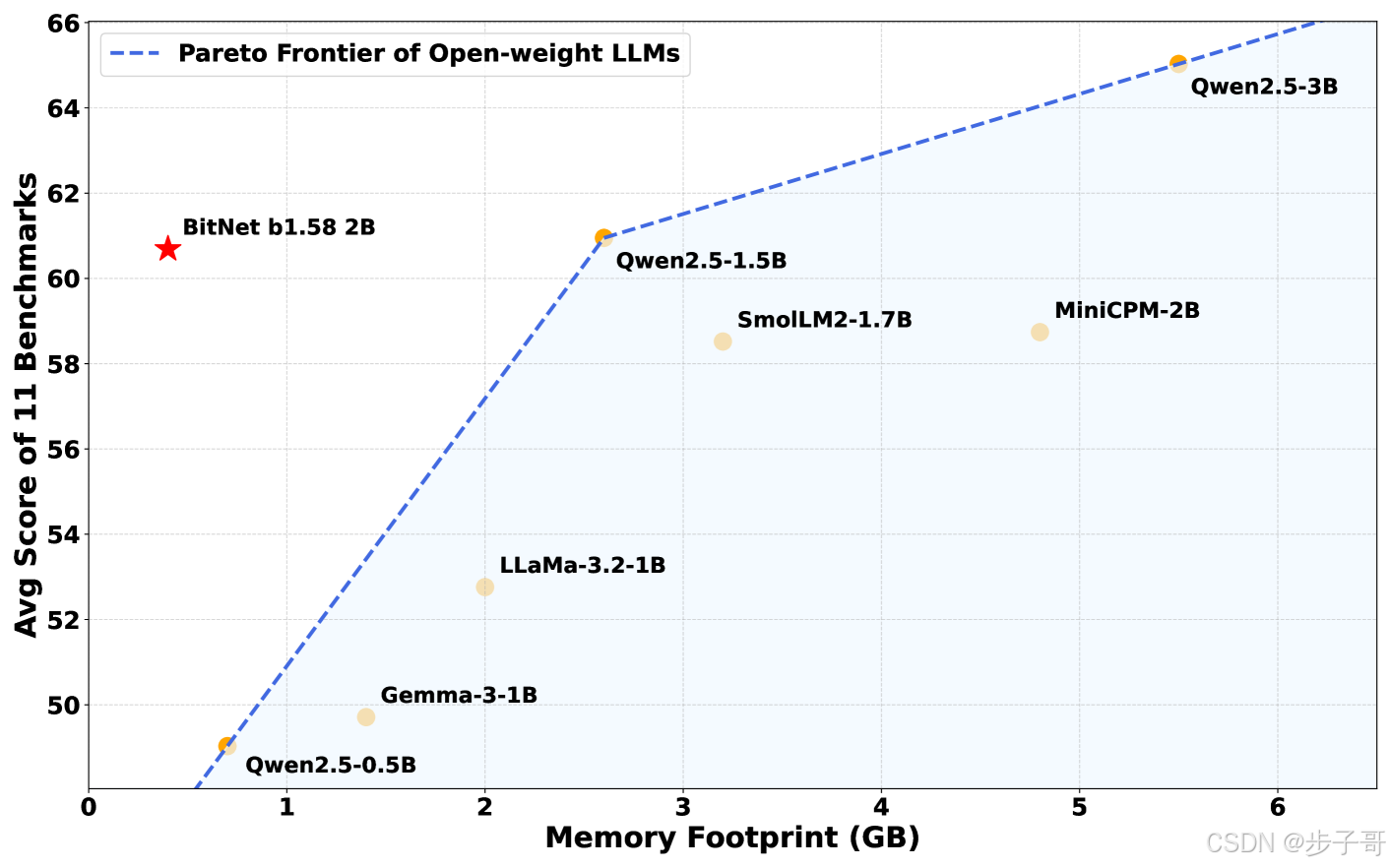
🚀 训练之路——从预训练到微调,再到偏好优化
构建一个如此高效的1-bit模型,离不开系统而精心的训练过程。BitNet b1.58 2B4T的训练分为三个阶段:大规模预训练、监督微调(SFT)以及直接偏好优化(DPO),每一阶段都通过精心设计的策略,实现了质量与效率的双赢。
🔥 预训练:高起点与冷却阶段的协奏曲
预训练阶段的目标在于为模型注入广博的世界知识和语言理解能力。整个预训练过程分为两个主要阶段:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











