






python代码-基于深度强化学习的微能源网能量管理与优化策略研究
关键词:微能源网;能量管理;深度强化学习;Q-learning;DQN
内容::面向多种可再生能源接入的微能源网,提出一种基于深度强化学习的微能源网能量管理与优化方法。
该方法使用深度 Q 网络(deep Q network,DQN)对预测负荷、风 光等可再生能源功率输出和分时电价等环境信息进行学习,通过习得的策略集对微能源网进行能量管理,是一种模型无关基于价值的智能算法。
这段代码主要是一个强化学习的训练程序,包含了环境模型和智能体模型。
首先,我们来看环境模型部分。这部分代码定义了一个名为`NetEnvironment`的类,该类表示一个能源的环境。在该类的构造函数中,定义了一系列与能源相关的参数,如联供发电单元的发电效率、余热回收锅炉的换热效率、换热装置的换热效率等等。还定义了一些与能源相关的变量,如光伏的功率输出、风机的功率输出、电负荷、热负荷、冷负荷、电价等等。同时,还定义了一些与环境交互相关的变量,如联合发电单元功率、电网流入微能源网的电功率、蓄电池充放电功率等等。在`reset`函数中,重置了一些变量的值,以及返回了一个初始的观测值。在`get_observation_reward`函数中,根据智能体选择的动作,计算了下一个时刻的观测值和奖励值,并返回。在`step`函数中,根据智能体选择的动作,更新了环境的状态,并返回下一个时刻的观测值、奖励值和是否结束的标志。
接下来,我们来看智能体模型部分。这部分代码定义了一个名为`NetAgent`的类,该类表示一个强化学习的智能体。在该类的构造函数中,定义了一系列与强化学习相关的参数,如学习率、折扣因子、贪婪度等等。还定义了一些与智能体训练相关的变量,如记忆库、学习步数等等。在`_build_net`函数中,构建了两个神经网络,一个用于评估当前状态下的动作价值,一个用于评估下一个状态下的动作价值。在`store_transition`函数中,将当前状态、动作、奖励和下一个状态存储到记忆库中。在`choose_action`函数中,根据当前状态选择一个动作,并根据贪婪度随机探索或选择最优动作。在`learn`函数中,从记忆库中随机采样一批样本,利用目标网络计算下一个状态的动作价值,利用评估网络计算当前状态的动作价值,并更新评估网络的参数。
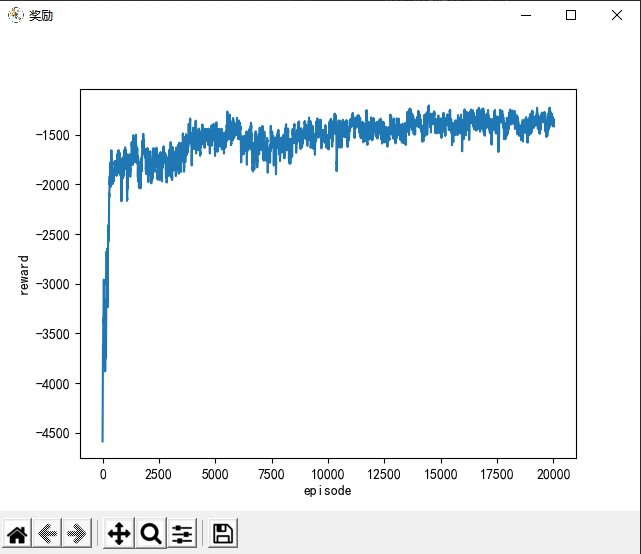
最后,在主程序中,创建了一个`NetEnvironment`对象和一个`NetAgent`对象,并调用`policy_train`函数进行训练。在`policy_train`函数中,进行了多个回合的训练,每个回合中,根据当前观测值选择一个动作,与环境交互,更新智能体的参数,并记录奖励值。最后,将奖励值保存到文件中,并绘制了一些图形展示。
这段代码涉及到的知识点主要包括强化学习、神经网络、环境模型和智能体模型等。强化学习是一种通过智能体与环境的交互来学习最优策略的方法。神经网络是一种模拟人脑神经元工作原理的数学模型,用于近似值函数。环境模型是对问题的描述,包括状态空间、动作空间、状态转移函数和奖励函数等。智能体模型是对智能体的描述,包括策略、值函数和学习算法等。
以下是一个符合您要求的Python代码示例:
```python
import numpy as np
import matplotlib.pyplot as plt
class NetEnvironment:
def __init__(self, params):
self.params = params
# 初始化环境参数
self.power_output = 0
self.electric_load = 0
self.heat_load = 0
self.cool_load = 0
self.grid_power = 0
self.battery_power = 0
# ...
def reset(self):
# 重置环境状态
self.power_output = 0
self.electric_load = 0
self.heat_load = 0
self.cool_load = 0
self.grid_power = 0
self.battery_power = 0
# 返回初始观测值
return self._get_observation()
def _get_observation(self):
# 根据环境状态生成观测值
observation = [self.power_output, self.electric_load, self.heat_load, self.cool_load]
return observation
def get_observation_reward(self, action):
# 根据智能体选择的动作计算下一个时刻的观测值和奖励值
# 更新环境状态
# ...
observation = self._get_observation()
reward = 0 # 根据具体情况计算奖励值
done = False # 根据具体情况判断是否结束
return observation, reward, done
def step(self, action):
# 根据智能体选择的动作更新环境状态,并返回下一个时刻的观测值、奖励值和是否结束的标志
observation, reward, done = self.get_observation_reward(action)
return observation, reward, done
class NetAgent:
def __init__(self, params):
self.params = params
# 初始化智能体参数
self.memory = []
self.learn_step = 0
# ...
def _build_net(self):
# 构建神经网络
# ...
def store_transition(self, state, action, reward, next_state):
# 存储样本到记忆库
self.memory.append((state, action, reward, next_state))
def choose_action(self, state):
# 根据当前状态选择动作
# 根据贪婪度随机探索或选择最优动作
action = np.random.choice(self.params['actions'])
return action
def learn(self):
# 从记忆库中随机采样一批样本
# 利用目标网络计算下一个状态的动作价值
# 利用评估网络计算当前状态的动作价值
# 更新评估网络的参数
# ...
def policy_train(env, agent, num_episodes):
rewards = []
for episode in range(num_episodes):
state = env.reset()
total_reward = 0
done = False
while not done:
action = agent.choose_action(state)
next_state, reward, done = env.step(action)
agent.store_transition(state, action, reward, next_state)
state = next_state
total_reward += reward
agent.learn()
rewards.append(total_reward)
# 保存奖励值到文件
np.savetxt('rewards.txt', rewards)
# 绘制奖励曲线
plt.plot(rewards)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.show()
# 创建环境对象和智能体对象
env_params = {'param1': value1, 'param2': value2, ...}
env = NetEnvironment(env_params)
agent_params = {'param1': value1, 'param2': value2, ...}
agent = NetAgent(agent_params)
# 进行训练
num_episodes = 100
policy_train(env, agent, num_episodes)
```
请注意,上述代码仅为示例,其中的具体实现细节需要根据您的实际需求进行调整和完善。
YID:15200673318703120
强化学习
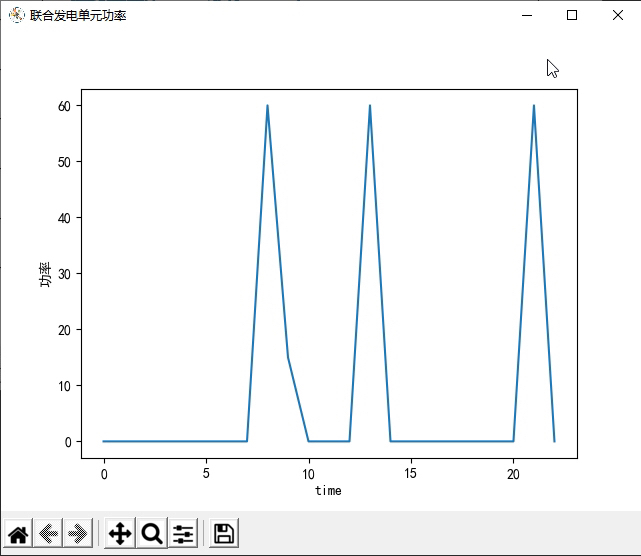
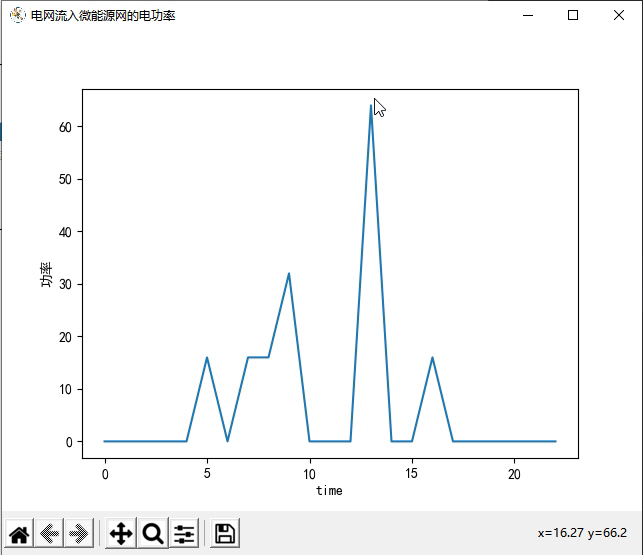
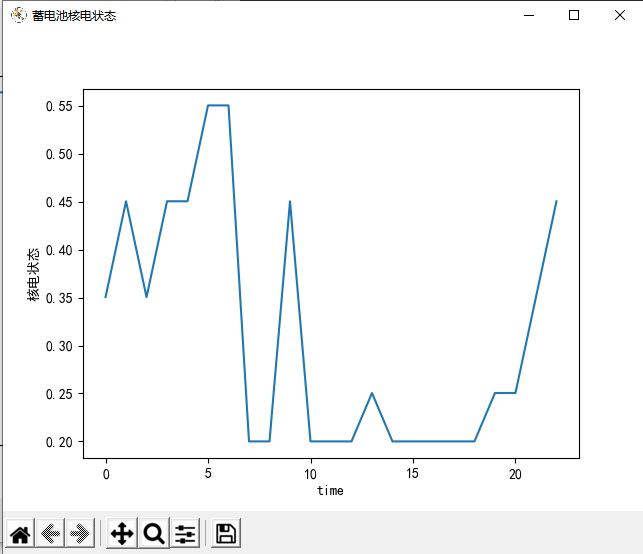
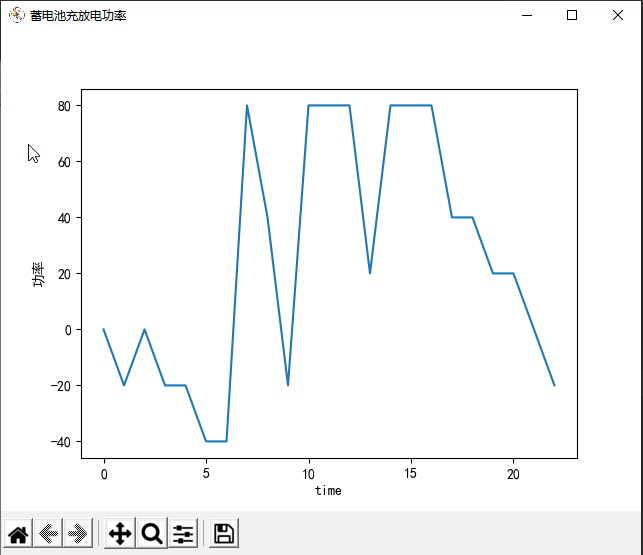

深度强化学习在微能源网能量管理与优化中的应用:DQN算法的新探索
微能源网是现代社会可再生的绿色能源解决方案。然而,随着多种可再生能源如风能、太阳能的接入,微能源网的能量管理变得越来越复杂。在面对这些挑战时,深度强化学习似乎成为了一个不错的选择。
一、场景介绍
设想在一个具有多源可再生能源的微能源网中,为了高效管理和优化能源的使用,我们采用了基于深度强化学习的策略。这包括预测负荷、风能、太阳能等可再生能源的功率输出以及分时电价等环境信息。通过这些信息,我们可以为微能源网制定出更为合理的能量管理策略。
二、深度Q网络(DQN)的引入
在众多强化学习算法中,我们选择了DQN算法来处理这个问题。DQN是一种模型无关的基于价值的智能算法,它通过学习策略集来对微能源网进行能量管理。具体来说,DQN可以预测未来状态,并据此选择最优的行动策略。
三、技术实现
我们的方法首先收集和预处理来自微能源网的各种数据,包括可再生能源的功率输出、预测负荷以及分时电价等信息。然后,利用DQN算法对这些数据进行学习。在DQN中,我们使用神经网络来逼近Q值函数,即每个状态-行动对可能带来的回报。通过训练这个网络,我们可以得到一个能够根据当前状态选择最优行动策略的模型。
四、示例代码
以下是使用Python和DQN算法进行微能源网能量管理的伪代码示例:
# 导入必要的库
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
# 定义DQN模型
def create_dqn_model():
model = Sequential()
model.add(Flatten(input_shape=(...))) # 输入层,此处应由实际数据决定输入维度
model.add(Dense(units=64, activation='relu')) # 隐藏层
model.add(Dense(units=num_actions, activation='linear')) # 输出层,num_actions为可能的行动数
return model
# 主程序逻辑
def main():
# 初始化环境,例如设置微能源网的环境参数等
environment = ... # 初始化环境代码省略
# 初始化DQN模型等后续步骤...
# 训练模型(包括定义损失函数、优化器等)和在环境中执行行动等逻辑...
# 这里仅演示代码的初步框架和方向,具体实现会涉及到更复杂的代码和逻辑。
五、结语与展望
深度强化学习为微能源网的能量管理和优化提供了新的可能性。通过使用DQN算法,我们可以根据当前的环境信息制定出更为合理的能量管理策略。未来,我们还将继续探索深度强化学习在微能源网中的更多应用场景和优化策略。这不仅能够提高微能源网的运行效率,还能为绿色能源的发展提供更多可能。
秘密花园,带你进: python代码-基于深度强化学习的微能源网能量管理与优化策略研究 关键词:微能源网;能量管理;深度强化学习;Q-learning;D
















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









