






文章目录
《姿态估计与人体解析联合学习》论文阅读
总结创新点
(利用人体解析任务指导姿态估计任务,整体基于MULA方法)
- 拼接SE模块,将经过全局池化的人体解析特征与姿态估计特征拼接在一起,独自作用在自己的任务。使得拼接后的表达力更强。(参考于CVPR2019行人重识别任务)
- 新的提纯模块:改进MULA中自适应模块,利用空洞卷积捕获全局信息
- 提出交换权重的SE模块,将人体解析权重参数与姿态特征做通道乘法;将姿态特征与人体解析权重做姿态乘法,最后再与经过残差模块模块前的原特征进行加和运算。使得各自任务能有所提升。
- 新的对抗训练方式——双输出生成器与两个判别器分别称为宏观判别器和微观判别器。用于解决单一的对抗损失与收敛性差的问题。宏观判别器输入低分辨率的分割图,输出语义一致性的置信分数;微观判别器输入高分辨率的分割图,输出局部一致性的置信分数。
- 自监督的结构语义学习损失来训练网络。通过解析的结果估计姿态,再利用姿态联合优化解析。
网络结构
1 特征编码与拼接
输入图像 I 最开始分别送入姿态编码器与解析编码器,编码成高级特征表示,编码器为沙漏网络,经过编码器后得到人体解析特征与姿态估计特征,而后将这两个特征送入拼接 SE 模块中。
【该 SE 模块与一般的 SE 模块的区别在于有两个输入同时进行全局平均池化,再在通道上将两个特征拼接在一起。后续操作与经典 SE 模块相同,经过 sigmoid 激活函数后分别与原特征相乘,最后再与残差模块相加】

- 自监督学习 :解决在一些场景中,有姿态标注信息缺失的情况。学习损失来训练网络。通过解析的结果估计姿态,再利用姿态联合优化解析。

- 拼接的DE模块

2 提纯模块与自适应卷积
【提纯模块(空洞卷积)、自适应卷积(参考MULA中的自适应卷积)】

根据提纯函数与提纯模块得到有利于解析任务与姿态任务的互引导参数—>通过自适应卷积将引导参数与经过编码器后得到的特征进行卷积运算—>得到姿态特征与解析特征—>将之前的特征与经过自适应卷积后的特征加和—>得到各自整体特征
3 交换权重互引导学习
【对人体解析精度有所提升,对姿态估计任务没大影响】
对上一步得到的特征进行最后的微调。使用交换权重的SE模块引导特征之间的相互学习。
【将经过第一步挤压与激励后的权重与另一个任务特征相乘】
结果
在LIP数据集上精度相比MULA有所提升,在行人重识别数据集中效果也不错。
可改进的地方
- 将沙漏网络替换成HRNet
- 注意力机制上除了SE模块(通道上)还可以同时引入空间上的注意力机制
- 跨数据集训练,提升精度和鲁棒性
其思考思路
- 人体解析任务缺乏对人体结构的考虑,而人体姿态估计任务可以为人体解析提供帮助;人体解析分割结果所包含的上下文信息和人体结构关系对人体姿态估计有帮助。两个任务互补。
- 基于MULA框架,主要改进了① SE模块,参考CVPR2019行人重识别任务中的拼接SE模块的思想,加上自己的交换权重SE,改进原版SE。②在自适应卷积前添加空洞卷积提纯模块
给我的思路启发
- 多读不同领域的论文,寻找可以借鉴的地方,在这之上大胆思考,勇于尝试与创新
- 多对比,思考原因
- 可借鉴的点:HRNet、特征拼接、权重交换
基础知识点汇总
沙漏网络Hourglass Network
CNN 能自动提取出对分类、检测和识别等任务有帮助的特征,并且随着网络层数的增加,所提取的特征逐渐变得抽象。以人脸识别为例,低层卷积网络能够提取出一些简单的特征,如轮廓;中间卷积网络能够提取出抽象一些的特征,如眼睛鼻子;较高层的卷积网络则能提取出更加抽象的特征,比如完整的人脸。如果我们只使用最后一层的 feature map,就会造成一些信息的丢失


SHN 的主要贡献——利用多尺度特征来识别姿态。
bottom-up过程将图片从高分辨率降到低分辨率,top-down过程将图片从低分辨率升到高分辨率,这种网络结构包含了许多pooling和upsampling的步骤,pooling可以将图片降到一个很低的分辨率,upsampling可以结合多个分辨率的特征。
为了捕获图片在多个尺度下的特征,通常的做法是使用多个pipeline分别单独处理不同尺度下的信息,然后再网络的后面部分再组合这些特征,而作者使用的方法就是用带有skip layers的单个pipeline来保存每个尺度下的空间信息。
卷积和max pooling被用来将特征降到一个很低的分辨率,在每一个max pooling步骤中,网络产生分支并在原来提前池化的分辨率下使用更多的卷积,当到达最低的分辨率的时候,网络开始upsample并结合不同尺度下的特征。这里upsample(上采样)采用的方法是最邻近插值,之后再将两个特征集按元素位置相加。
当到达输出分辨率的时候,再接两个1×1的卷积层来进行最后的预测,网络的输出是一组heatmap,对于给定的heatmap,网络预测在每个像素处存在关节的概率。

串联的沙漏网络是因为姿态关节之间可以相互参考预测。例如知道脖子位置后,可以更好预测两肩位置。

将第一个沙漏网络给出的热力图作为下一个沙漏网络的输入,就意味着第二个沙漏网络可以使用关节点件的相互关系,从而提升了关节点的预测精度。
如上图,N1代表第一个沙漏网络,提取出的混合特征经过1个1x1全卷积网络后,分成上下两个分支,上部分支继续经过1x1卷积后,进入下一个沙漏网络。下部分支先经过1x1卷积后,生成heat map,就是图中蓝色部分。
heat_map继续经过1x1卷积,将depth调整到与上部分支一致,如256,最后与上部分支合并,一起作为下一个沙漏网络的输入。 第一个hourglass生成的heatmap的主要作用有两个:第一是给下一个hourglass提供关节点相互参考预测的参考信息(类似于注意力机制);第二是用于中间监督计算loss。
源码
空洞卷积
空洞卷积能有效聚合多尺度的上下文,避免因连续上采样和下采样造成的分辨率丢失。

SENet(Squeeze-and-Excitation Networks)
挤压与激励网络,易于实现,并且很容易可以加载到现有的网络模型框架中。SENet主要是学习了channel之间的相关性,筛选出了针对通道的注意力,稍微增加了一点计算量,但是效果比较好。
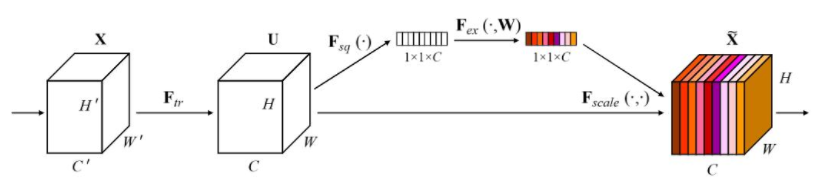
SE可以实现注意力机制最重要的两个地方一个是全连接层,另一个是相乘特征融合
假设输入图像H×W×C,通过global pooling+FC层,拉伸成1×1×C,然后再与原图像相乘,将每个通道赋予权重。在去噪任务中,将每个噪声点赋予权重,自动去除低权重的噪声点,保留高权重噪声点,提高网络运行时间,减少参数计算
注意力机制
注意力机制没有严格固定的数学公式,图像处理中的特征提取、滑动窗口、边缘算子等操作都可以被视为一种特殊的注意力机制。
注意力机制一般可以分为两大类:软注意力机制、硬注意力机制。 软注意力机制就是虽然词语权重不同,但是在训练模型的时候雨露均沾,每个词语都用到,加权平均,焦点词语的全重大。硬注意力机制是从存储的多个信息中只挑出一条信息来,可能是概率最大的那个词向量。选取概率最高这一步骤通常是不可微的,因此,硬注意力更难训练。可以借助如强化学习的手段去学习。
从空间角度分类可以分为三种注意力域:通道域、空间域、混合域
通道域:在深度学习中彩色图片用三通道形式表示,在经过各种卷积操作之后,从信号变化的角度去看每个通道就会生成新的信号,这里的卷积操作可以理解为傅里叶变换,将特征一个通道上的信息分解成卷积核个数个信号分量,每个通道上对于信号的贡献各不相同通道域。通道域注意力机制就是去学习每个通道上信号的权重,权重越大表示该通道域关键信息的相关度就越高,最为典型的就是 SE 模块。
空间域:空间转换网络(STN),将图像中的空间域信息进行空间变换,保留关键性的信息,从而达到注意力的效果。
混合域:结合空间域与通道域两种思路。
自注意力机制:保留了查询、键值对等名称。在序列内部做注意力,寻找序列内部之间的联系。
关节点评价标准
PCK

PCKh

语义分割

对抗学习
对抗训练(adversarial training)是增强神经网络鲁棒性的重要方式。在对抗训练的过程中,样本会被混合一些微小的扰动(改变很小,但是很可能造成误分类),然后使神经网络适应这种改变,从而对对抗样本具有鲁棒性。
自监督学习
自监督学习(self-supervised learning),模型直接从无标签数据中自行学习,无需标注数据。
- 自监督学习的核心,在于如何自动为数据产生标签。例如输入一张图片,把图片随机旋转一个角度,然后把旋转后的图片作为输入,随机旋转的角度作为标签。再例如,把输入的图片均匀分割成3*3的格子,每个格子里面的内容作为一个patch,随机打乱patch的排列顺序,然后用打乱顺序的patch作为输入,正确的排列顺序作为label。类似这种自动产生的标注,完全无需人工参与。
- 自监督学习如何评价性能?自监督学习性能的高低,主要通过模型学出来的feature的质量来评价。feature质量的高低,主要是通过迁移学习的方式,把feature用到其它视觉任务中(分类、分割、物体检测…),然后通过视觉任务的结果的好坏来评价。目前没有统一的、标准的评价方式。
强化学习
强化学习是一种探索式的学习方法,通过不断 “试错” 来得到改进,不同于监督学习的地方是 强化学习本身没有 Label,每一步的 Action 之后它无法得到明确的反馈(在这一点上,监督学习每一步都能进行 Label 比对,得到 True or False)。
有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
迁移学习
把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习 。
















 3607
3607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











