









之前的方法,采用RNN + RL,那个代价太大。
本节介绍的方法,是常用的方法。

Darts:目标函数是NN结构超参数的可微函数,于时可以对目标函数,关于超参数求梯度,直接用梯度来更新超参数。这样不用RL,更好的找到RL。
FBNet:是Darts的特例。
- 基本思想
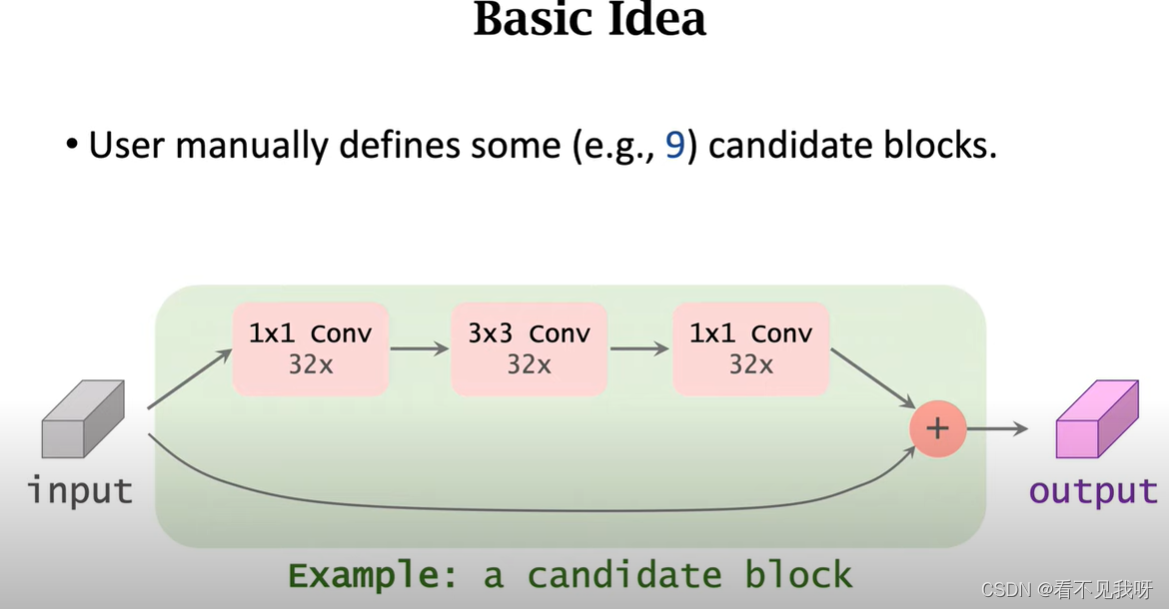
用户需要手动定义一些模块,作为候选方案,例如:9中候选模块,包含conv以及其他。《候选模块越多,计算量越大,搜索越慢》。
图为9个候选框的一个。
输入为张量;经过conv,输出张量,其维度和输入相同。然后采用直连。
用户搭建的9个这样的候选模块,内部不相同。如:不同的卷积层,不同的卷积核,以及是否有pooling,此模块由用户自行设计。

注意:指定nn的层数。此处的一层,为一个block。即:一个候选模块。哪怕该候选模块中有3个conv,也是一层。另外注意其搜索空间,很大,因此不能暴力搜索。

SuperNet 是一个很大的NN,每一层都有9个候选模块并联而成。在训练集中训练superNet,然后找到输入到输出的一条路径,此路径即为最优的NN。

用9个模块处理张量x,得到9个输出张量f,然后加权输出z。
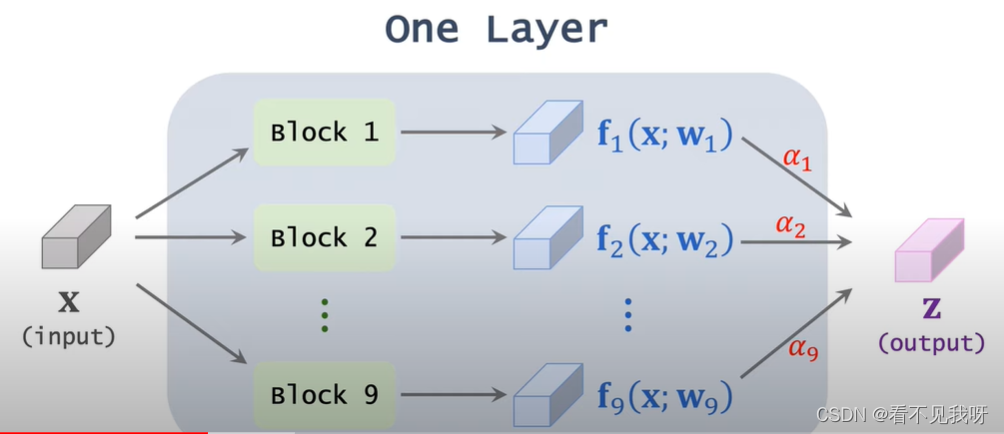
Alpha为NN的超参数,目的就是学习此参数。
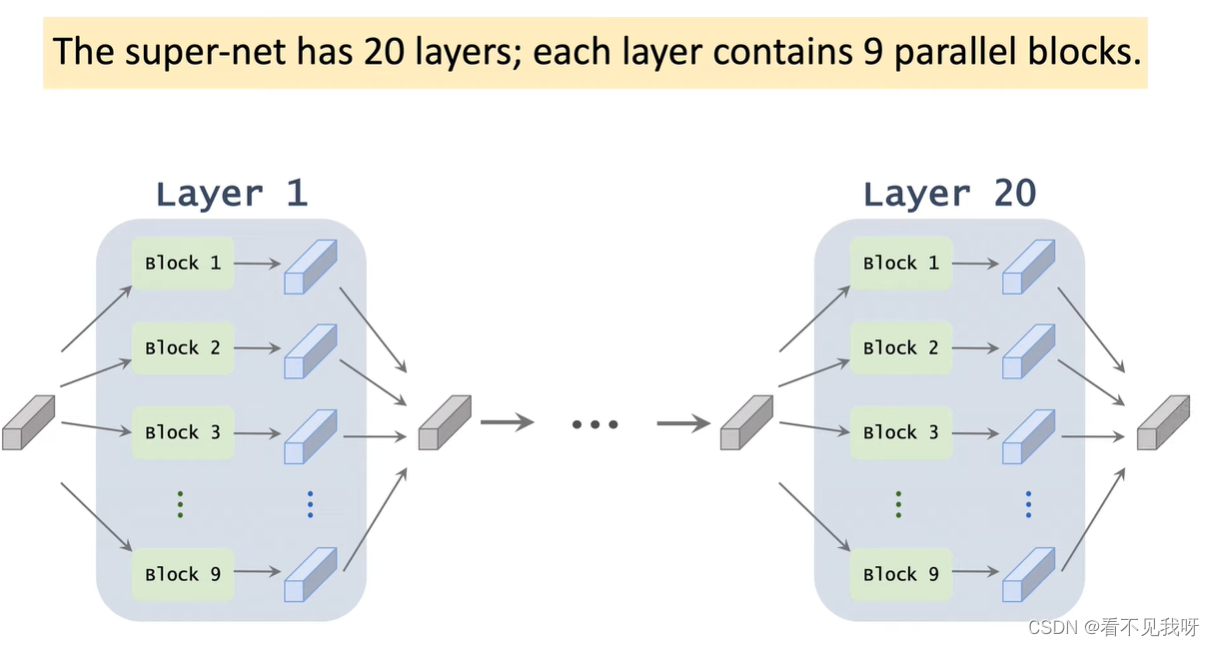
一共20层,但是每一层的结构一样,但是参数不同。即不会共享参数。



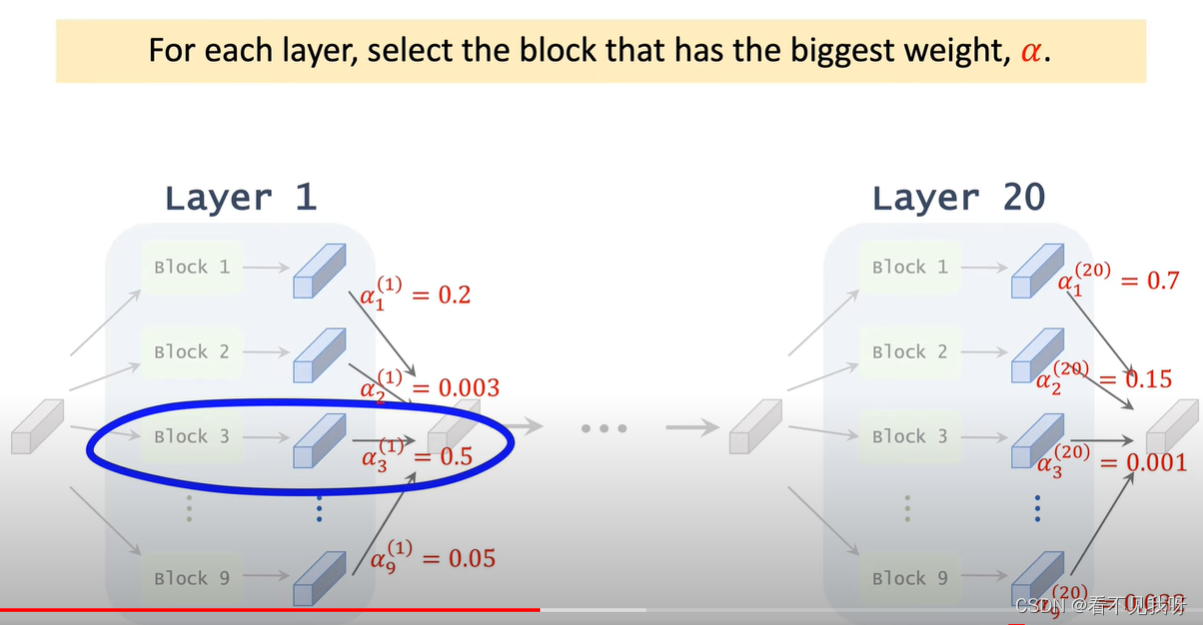
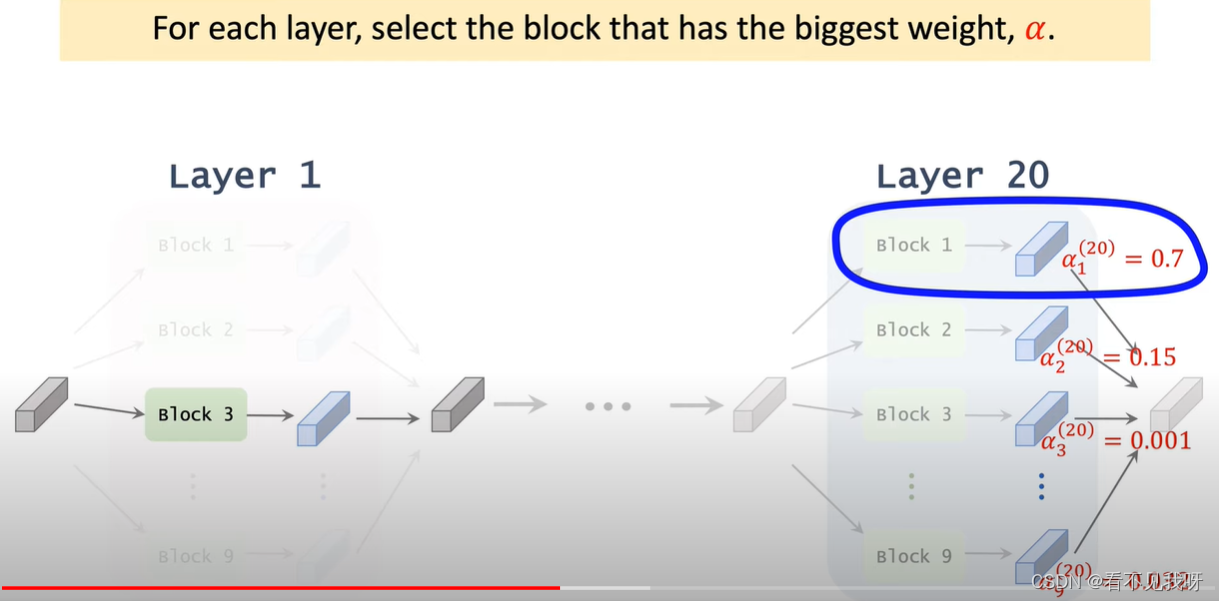
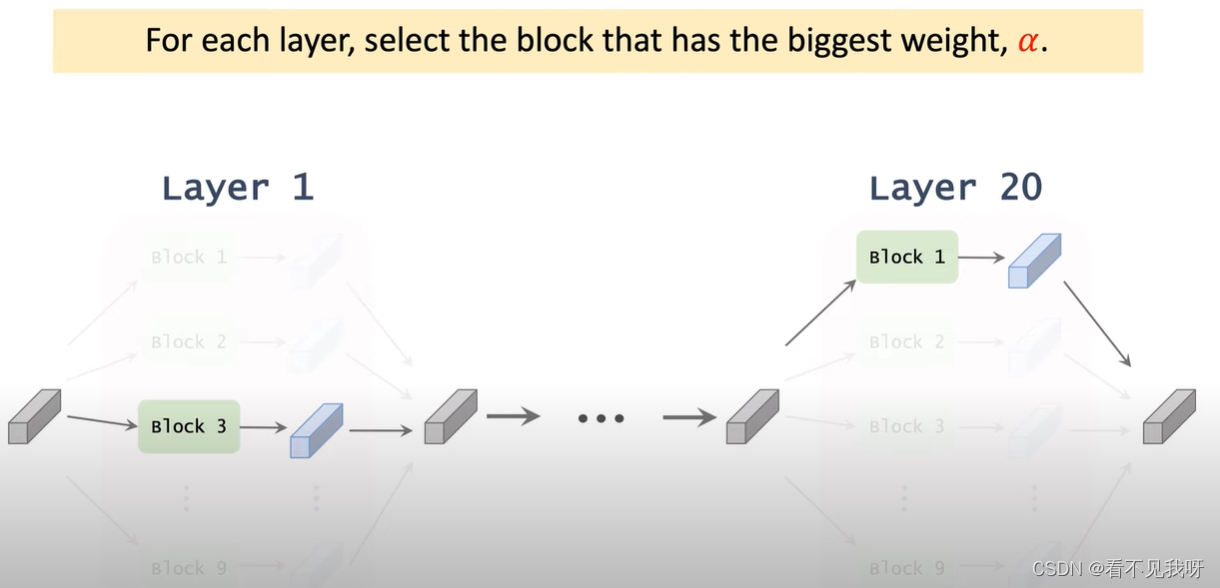
<当然,可以根据alpha,做随机抽样,而不是取最大值>















 2014
2014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









