







- 视频理解
视频分类,也叫做动作识别,或者视频理解。因此对人的动作感兴趣。
- 概述

单个cnn仅适合学习局部信息,不适合学习移动信息。
因此,学习光流到动作的映射。
时间流网络:一系列的光流。
-
- 光流
观察者和场景中各种物体的运动。描述视频中各个物体时如何运动的。

背景没有动。越亮的地方,运动越厉害。
光流是非常有效的表示物体之间运动的特征。
光流可以忽略性别,穿着等,仅仅关注与动作本身。
3. 摘要
3.1 需要同时获取两种信息:
(1)静止图像的外观信息:形状,大小,颜色,场景等;
(2)物体的运动信息,或者视频的时序信息。
3.2 三个贡献
(1)双流网络-空间流 + 时间流;
(2)少量数据上,即使只用光流信息,也可以获得不错的结果。
(3)多任务学习,2个数据集,同时学习backbone。
4. 引言
(1)视频自带数据增强功能;
(2)视频帧直接丢i给网络。很差
(3)手工特征,在光流轨迹上提取特征,很好的抓取运动信息。空间流,采用预训练网络。
(4) 将一个视频扔给一个2D网络,和将一系列视频丢给一个3D网路,很相似,学不到时空信息。
5. 双流网络的结构
空间流:获取外观信息;
时间流:获取运动信息;
最后,合并信息,采用加权平均/svm分类。
5.1 空间流
采用静止的信息,图像学习关联物体,本来就不错了。并且可以做预训练。
5.2 时间流

每个像素点,都会运动,如果不运动,光流幅度就会为0.
每两张图像,得到一张光流。
5.2.2.如何使用光流
如果将光流图,拆解出来,则意义不大了。学不到时序信息。
因此,光流网络是输入多个光流的。

5.2.3.如何叠加光流
光流已经经过resize了
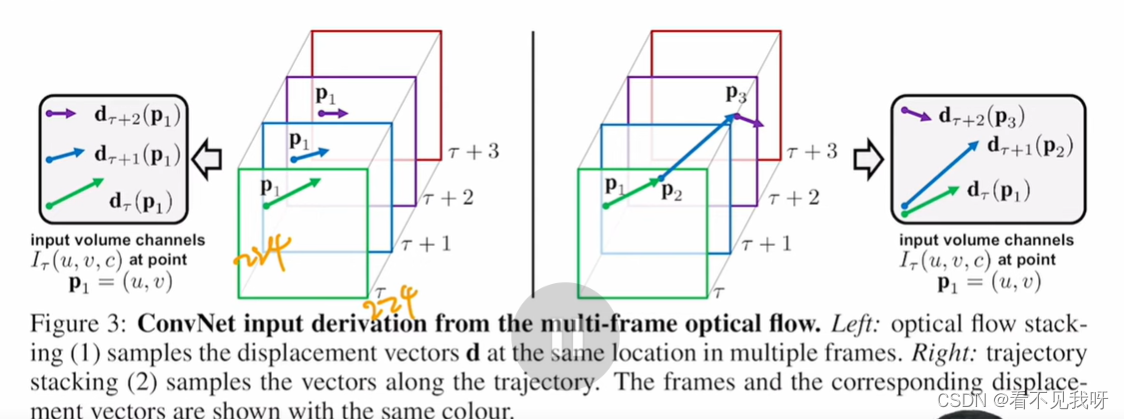
左边:基于固定坐标的方式搜索;右边:基于移动坐标的方式搜索(基于轨迹的方式)。
实验结果:左边的方式,比 右边要好一些。

双向光流:前半段做前向光流,后半段做后向光流。此时的光流输入为2L。
光流怎么叠加:

此光流送入时间流网络。
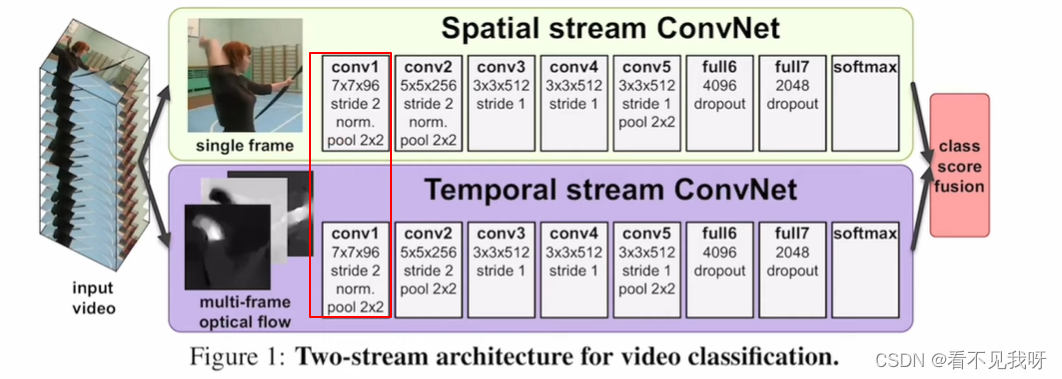
上面输入维度为3,下面输入维度为2L。
11帧。
叠加方式:先叠加水平的光流,后竖直的光流。

5.2.4 实现细节
测试:等间距抽帧

光流:先取25帧,然后往后连续取11帧,获取光流,然后光流送入时间流网络。
最后将所有的结果,取平均。
空间流和时间流,分别各自取平均,然后做late fusion,加一起除以2。此为最终的双流网络的结果。
抽取光流:很耗时,密集表示,存储空间大。

6.实验结果

光流时序越长,效果越好。
简单的堆叠更好
双向光流更好。

论文音声
















 7482
7482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









