







专业调参20年。。。
2020年4月11日更新:注意!余教授团队最近已经将此文章的代码迁移到了PyTorch环境下,相关代码可以在OpenVQA项目找到。旧代码就请直接忽略掉吧,作者在最新的代码中更改了部分细节,如不再使用ResNet-152作为图片feature的提取器,而是使用类似bottom-up-attention中的方法,Faster RCNN作为特征提取器,提取图片中前100个目标的feature(所以最终的feature size是 100 × 2048 100 \times 2048 100×2048)。总而言之,一切以新代码为准!
这是ICCV2017上的一篇文章(文章链接),代码在github上的地址:链接,pytorch版本在这里。
文章里面实现的模型结构示意图:
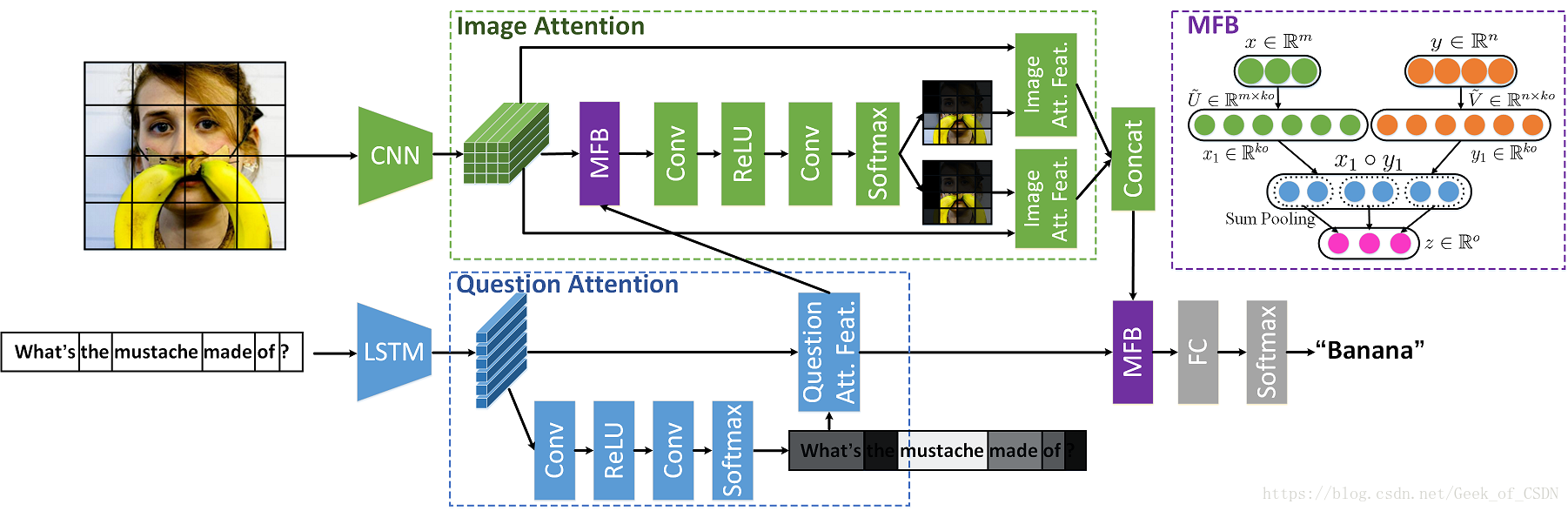
项目页的笔记:
要使用他们给出的代码的话就要先看下vqa-mcb项目里面的要求,因为代码是基于这个项目开发的。注意因为代码里面的MFB和MCB有点不同,所以caffe版本要用这里给出的,并且要在使用代码的时候禁用掉CuDNN(因为CuDNN还不支持sum pooling)。
重新训练模型
在官方给出的mfb-baseline和mfb-coatt-glove文件夹里面就已经给出了所有训练会用到的脚本,只需要跑对应文件夹下面的train_*.py来训练就可以了。大部分超参数被定义在了config.py文件里面,solver配置被定义在了train_*.py脚本里面的get_solver函数里;训练mfb-coatt-glove模型时要用到预先训练好了的GloVe word embedding模型(spacy库里面的,这个库是一个python的自然语言处理工具包;spacy和GloVe模型的安装方法可以在这里找到)。
论文里面的内容笔记:
简单翻译一下摘要:
摘要
VQA(visual question answering 图像问答)问题的解决因为需要模型同时对图像信息和问题的信息进行理解,所以比较难解决。为解决这种问题建立的模型的性能在很大程度上取决于怎么从问题中提取特征,怎么在图像中在细粒度程度上提取需要的特征,以及怎么对这两种提取出来的特征进行整合。尽管各类基于双线性池化的模型在VQA问题上的表现优于传统的线性模型,但是由于这类模型的高维度特征(but their high-dimensional representations)及需要高复杂度的计算量的特点,限制了这类模型的适用范围。作者设计出了Multi-modal Factorized Bilinear (MFB) 多模态拆分双线性池化模型来高效地融合多模态的特征。作者设计的模型在VQA问题上相比于其他双线性池化模型有更加好的表现。在细粒度图像和问题特征的提取上,作者用一种端对端深度学习网络设计了一种“co-attention”(双重注意)机制,来实现同时在图像和问题上学习。最后,作者将MFB模型和双重注意学习结合成一个专门针对VQA开发的网络模型。作者的实验数据表明这种新的模型能够在现有的VQA数据集上拥有目前最优异的表现。
总结:团队设计的将MFB模型和co-attention机制结合后产生的新模型,在现有VQA上获得了目前最好的成绩。
引言
(下面只记录与团队工作有关的东西)
现有VQA解决步骤大概可以分成三步:
- 分别从图像和问题提取特征
- 将特征融合形成图像-问题特征
- 在融合的特征上训练分类器并以此预测出答案
绝大多数团队在多模态的特征融合上使用了线性模型,但是因为多模态不同特征之间的分布差异特别大,直接线性叠加或使用线性模型融合的话效果不会很好,融合出来的新特征也就没有办法找到图片和问题之间的联系。(这里就引出bilinear了)bilinear pooling现在被用在整合不同CNN网络生成的特征上,用来实现细粒度图像识别。但是这种方法会产生高维度特征,而且模型的参数很多,所以严重限制了它的适用范围。
Multi-modal Compact Bilinear (MCB)模型可以通过Tensor Sketch算法来有效减少模型的参数数量和计算时间。但是MCB模型需要输出高维度特征来保证鲁棒性,所以需要大量的内存空间,这样就限制了适用范围。
Multi-modal Low-rank Bilinear (MLB)模型是基于Hadamard product来融合两种特征的。MLB的输出具有相对低的维度,模型参数又少,简直不能再好(这句是贫僧加的,原文没有)。但是(反正有了这句“但是”前面再怎么吹都没用),对超参数敏感,收敛速度又慢,简直不能再烂(这句原文没有!)。
于是为了用1个模型实现2个愿望(MLB的低维度特征输出,MCB的输出鲁棒性),团队设计了Multi-model Factorized Bilinear pooling (MFB)。
特征提取上不会使用所有从图片里面得到的特征(因为可能会引入与问题不相关的信息),而是用了visual attention方法来选择与问题最相关的信息。同时与现在的大部分模型不同,作者的模型还考虑了对问题进行特征处理(因为问题本身可能含有方言/偏僻词这类相当于噪音的信息)。最后作者在MFB基础上设计了co-attention learning模块(一种深度神经网络)来同时提取图像和文本的attention。
文章的贡献:
- 提出了MFB
- 在MFB基础上发展了co-attention
- 通过实验证明了normalization在bilinear模型起到了非常重要的作用
Multi-modal Factorized Bilinear Pooling
公式是这样的,假设 x ∈ R m x \in \mathbb{R}^{m} x∈Rm,就是假设 x x x是图片的特征向量,而 y ∈ R n y \in \mathbb{R}^{n} y∈Rn, y y y属于问题的特征向量。那么bilinear pooling就可以定义为:
z i = x T W i y z_i = x^T W_i y zi=xTWiy
上面出现的 W i ∈ R m × n W_i \in \mathbb{R}^{m \times n} Wi∈Rm×n就是一个投影矩阵, z i ∈ R z_i \in \mathbb{R} zi∈R是bilinear模型的输出。上面公式里面的 W W W里面包含了偏置项,所以没有单独写出偏置项。需要通过训练 W = [ W i , … , W o ]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 79
79











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









