







分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
本篇文章并不打算描述所有这些类别,要具体阐述它们的细节和意义实在有点困难。这个大纲的目的,第一:提供一个貌似详细的距离度量的分类体系,列出相关的关键字。 第二:就像一个词典一样供参考和查阅,如果需要了解具体的细节,可以参考wiki或者具体文献。
大纲:
1. 相似性和不相似性的定义
2. 预备概念
3. 距离度量
3.1 Numerical Data
3.1.1 欧拉距离(Euclidean Distance)
3.1.2 曼哈顿距离(Manhattan Distance)
3.1.3.最大距离(Maximum Distance)
3.1.4 明考夫斯基距离(MinKowski Distance)
3.1.5 马式距离(Mahalanobis Distance)
3.1.6 平均距离(Average Distance)
3.1.7 其他距离:Chord Distance,Geodesic distance,…..
3.2 Categorical Data
3.2.1. 简单匹配距离(Simple matching Distance)
3.2.2 其他匹配距离
3.3. Binary Data
3.3.1 Jaccard, Dice, Pearson, Yule, Russel-Rao, Sokal-Michener, Rogers-Tanimoto, Rogers-Tanimoto-a, Kulzinsky.
3.4 Mixed-type Data
3.5 Time Series Data
3.7 Other
3.7.1 Based on Longest Common Subsequence
3.7.2 Based on Probability Models
3.7.3 Based on Landmark Model
3.7.4 Based on Link Model
3.8 概率变量的相似性
3.8.1 Pearson 协方差
3.8.2 卡方统计(Chi-square Statistic)
3.8.3 基于最优预测( Optimal Class Prediction)
3.8.4 基于组的距离度量(Group-based Distance)
定义:
一直误解相似(similarity)度量和不相似(dissimilarity)度量,相似性度量在以前的一篇中已经描述过了,通常情况下不相似度量满足下面的三条性质:
1) 0<= s(x,y) <=1
2) s(x,x) = 1
3) s(x,y) = s(y,x)
当然,还有更多的相似度量和不相似度量方法(@see representation of similarity matrices by trees)
预备概念:
1. Proximity Matrix
给定数据集合D={x1,x2,x3,…,xn}
Mdis(D) = (dij) dij = d(xi, xj)
Msim(D) = (sij) sij = s(xi, xj)
2. 离差矩阵Scatter Matrix

 或者
或者
![]()
3. 协方差矩阵Covariance Matrix:
![]()
来源:http://blog.csdn.net/beta2/article/details/5714733
距离和相似性度量
相似性度量或者距离函数对于像聚类,邻域搜索这样的算法是非常重要的。前面也提到,网页去重复也是相似性应用的一个例子。然而,如何定义个合适的相似或者距离函数,完全依赖于手头的任务是什么。一般而言,定义一个距离函数d(x,y),需要满足以下几个准则:
1. d(x,x) = 0 ;//到自己的距离为0
2. d(x,y)>=0 // 距离要非负
3. 对称性,d(x,y) = d(y,x) //如果A到B距离是a,那么B到A的距离也应该是a
4. 三角形法则(两个之和大于第三边) d(x,k)+ d(k,y) >= d(x,y)
满足这4个条件的距离函数很多,一般有几类是比较常见的,通常来自比较直观的形象,如平面的一个两点的直线距离。下面讨论应用比较广泛的几类距离或相似性度量函数,欧拉距离,余弦函数cosine,Pearson函数,Jaccard index,edit distance。如果一个对象d(如:一篇文档)表示成一个n维的向量(d1,d2,….,dn),每一个维度都为对象的一个特征,那么这些度量函数极容易得到应用。
1.范数和欧拉距离
欧拉距离,来自于欧式几何(就是我们小学就开始接触的几何学),在数学上也可以成为范数。如果一个对象对应于空间的一个点,每一个维度就是空间的一个维度。特殊情况,如果n=1,那么,小学我们就学过,直线上两个点的距离是|x1-x2|。推广到高纬情况,一个很自然的想法是,把每一个维度的距离加起来不就可以呢。这就形成了传说中的一范数:

看,是不是很简单。有一范数就有二范数,三范数。。。无穷范数。其实,二范数来的更加直观,我们都知道二维空间,三维空间的两点的距离公式。他就是二范数,在二维三维上的形式了。

好了,一鼓作气,p范数(p-norm)
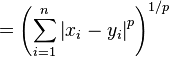
无穷范数: 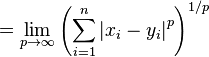

空间两点的距离公式(2-范数),是最常用的距离公式,他就是传说中的欧拉距离。多简单。
2. cosine similarity
cosine similarity是备受恩宠啊,在学向量几何的时候,应该接触过这个神奇的公式
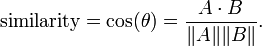
分子是两个向量的点积,||A||是向量的长度,这个公式神奇的地方是,随着角度的变化的,函数是从-1,1变化的。向量夹角的余弦就是两个向量的相似度。cosine similarity 说,如果两个向量的夹角定了,那么无论一个向量伸长多少倍,他们的相似性都是不变的。所以,应用cosine 相似性之前,要把对象的每一个维度归一化。在搜索引擎技术中,cosine 相似性在计算查询和文档的相似性的时得到了很好的应用。对查询语句而言(如:“明天天气如何”),它的每一个维度是对应词的tf-idf.
cosine similarity的一个扩展是,Tonimoto系数:

其实也没什么大不了。T(A,B)的分母是大于等于 cos similarity的分母,但且仅仅但 A,B长度一样是才相等。这就意味着,Tonimoto系数考虑了两个向量的长度差异,长度差异越大相似性约小。
3. Jacard index
Jacard 相似性直观的概念来自,两个集合有多相似,显然,Jacard最好是应用在离散的变量几何上。先看公式(不要头晕)
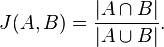
分子是集合交集,分母是集合并集,画个图,马上就明白咋回事了。
和Jacard index 相似的一个公式是Dice‘ coefficient, 它也很直观,

4. Pearson correlation coefficient
学过概率论的人都知道,有均值,反差,还有相关系数,相关系数就是就是描述两组变量是否线性相关的那个东西。相关系数的优点是,它跟变量的长度无关,这个都点像cosine相似性。有一个应用是,比如一个商品推荐系统,要给用户A推荐相应的产品,首先要通过对商品的打分,找到与A相似k个用户。但是有些人,可能天生喜欢打高分,有些人偏向于打低分,为了消除这个问题 相关系数是一个很好的度量方法。列公式,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









