







 该文介绍了一个用于从含水印的噪声图像中提取30bit水印信息的Decoder结构。Decoder通过多次卷积、批量归一化和ReLU激活函数进行特征提取,接着应用全局平均池化压缩成固定长度的特征向量,最后通过线性层输出解码后的水印消息。提供的代码实现了Decoder模块,接收含水印图像并输出解码后的水印信息。
该文介绍了一个用于从含水印的噪声图像中提取30bit水印信息的Decoder结构。Decoder通过多次卷积、批量归一化和ReLU激活函数进行特征提取,接着应用全局平均池化压缩成固定长度的特征向量,最后通过线性层输出解码后的水印消息。提供的代码实现了Decoder模块,接收含水印图像并输出解码后的水印信息。
一、简介
论文链接: 点击此链接查看HiDDeN的文献
论文中的Decoder结构,如下图所示:
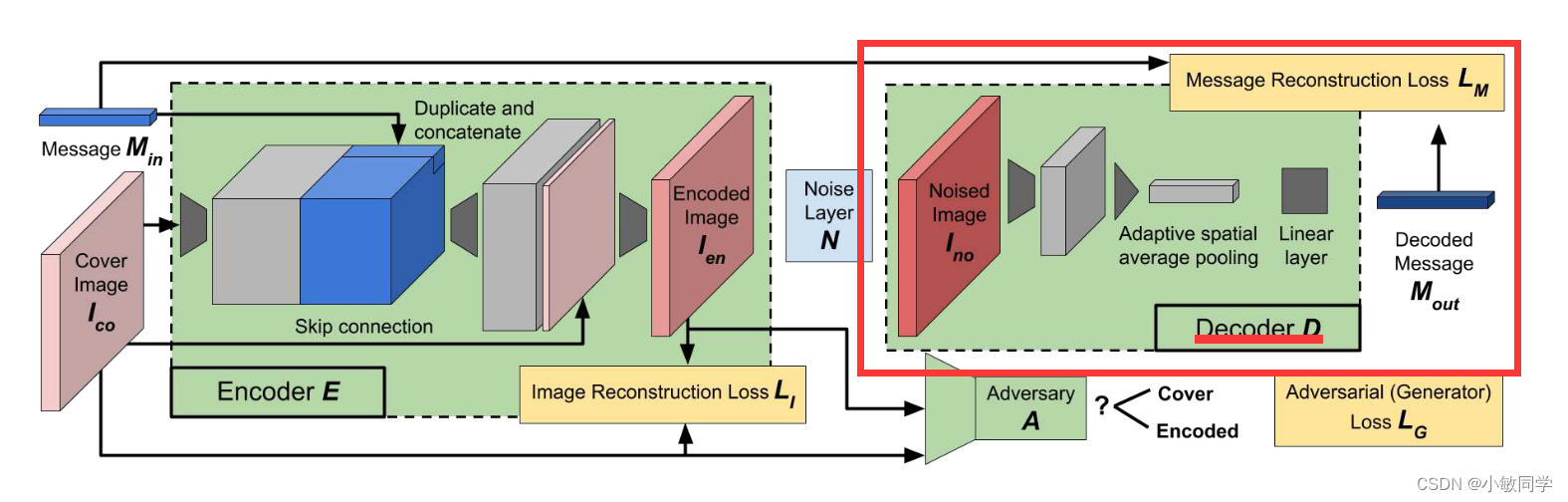
Decoder具体结果如图2所示。
Decoder功能: 从噪声水印图像中提取出30bit的水印信息,目标是尽可能接近原始信息。
Decoder输入: 含水印的 Noised Image(噪声图像) = 3×128×128
Decoder输出: Decoded Message(30bit 解码信息)
Decoder实现步骤:
step 1: 对含水印的Noised Image(噪声图像)应用多次ConvBNRelu卷积,进行特征提取
step 2: 应用AdaptiveAvgPool2d全局平均池化,将输入的特征图压缩成与水印消息等长的特征向量 Decoded Message = [1, 30, 1, 1]
step 3: 进行维度压缩,去掉最后两个维度 Decoded Message = [1, 30]
step 4: 应用Linear全连接,将网络的输出展平为一维向量,产生预测消息
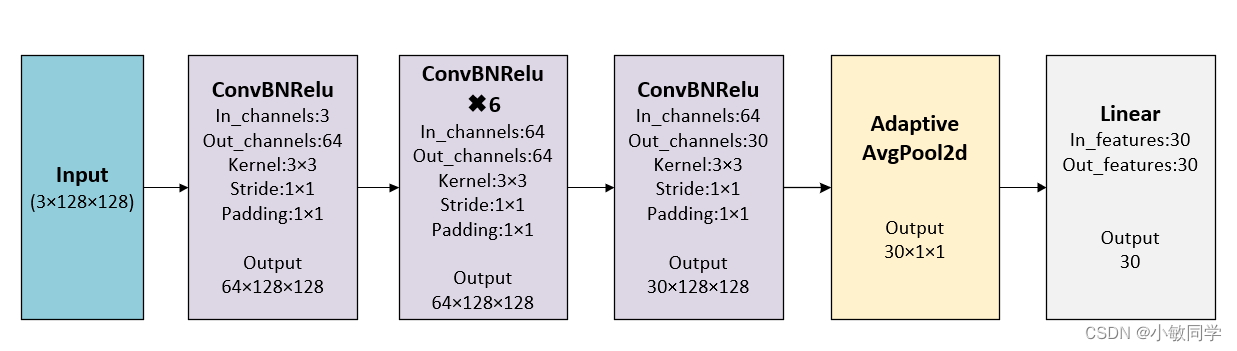

二、解码器代码模块
import torch
import torch.nn as nn
from PIL import Image
from torchvision.transforms import transforms
class ConvBNRelu(nn.Module):
def __init__(self, channels_in, channels_out, stride=1):
super(ConvBNRelu, self).__init__()
self.layers = nn.Sequential(
nn.Conv2d(channels_in, channels_out, 3, stride, padding=1),
nn.BatchNorm2d(channels_out),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.layers(x)
class Decoder(nn.Module):
"""
Decoder module. Receives a watermarked image and extracts the watermark.
"""
def __init__(self):
super(Decoder, self).__init__()
self.config = {
"decoder_blocks": 7,
"decoder_channels": 64,
"message_length": 30
}
self.channels = self.config['decoder_channels']
layers = [ConvBNRelu(3, self.channels)]
for _ in range(self.config['decoder_blocks'] - 1):
layers.append(ConvBNRelu(self.channels, self.channels))
layers.append(ConvBNRelu(self.channels, self.config['message_length']))
# 将输入的特征图压缩成一个固定长度的特征向量
layers.append(nn.AdaptiveAvgPool2d(output_size=(1, 1)))
self.layers = nn.Sequential(*layers)
# 将网络的输出压缩为指定的水印消息长度。
self.linear = nn.Linear(self.config['message_length'], self.config['message_length'])
def forward(self, image_with_wm):
x = self.layers(image_with_wm)
x.squeeze_(3).squeeze_(2) # 维度压缩,去掉最后两个维度
x = self.linear(x)
print("消息:", x)
return x
# 读取图片并转换为Tensor格式
image = Image.open("./data/cover.jpg")
transform = transforms.ToTensor()
image = transform(image)
image = image.unsqueeze(0)
print("image.shape: ", image.shape)
# 创建模型并进行前向传播
model = Decoder()
output = model(image)
# 打印输出张量的形状
print("output.shape: ", output.shape)
print("output: ", output)
运行结果如下图所示:



















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









