







标题: Learning in High Dimension Always Amounts to Extrapolation
arXiv链接: https://arxiv.org/abs/2110.09485
阅读原因: 推荐,LeCun出品,Facebook AI出品,机器学习理论
摘要: The notion of interpolation and extrapolation is fundamental in various fields from deep learning to function approximation. Interpolation occurs for a sample x whenever this sample falls inside or on the boundary of the given dataset’s convex hull. Extrapolation occurs when x falls outside of that convex hull. One fundamental (mis)conception is that state-of-the-art algorithms work so well because of their ability to correctly interpolate training data. A second (mis)conception is that interpolation happens throughout tasks and datasets, in fact, many intuitions and theories rely on that assumption. We empirically and theoretically argue against those two points and demonstrate that on any high-dimensional (>100) dataset, interpolation almost surely never happens. Those results challenge the validity of our current interpolation/extrapolation definition as an indicator of generalization performances.
自译: 从深度学习到概率建模(function approximation),插值(interpolation)和外推(extrapolation)这两个概念都是这些领域的基础。插值发生在当采样点位于数据集的凸包内部或边缘,外推发生在该采样点落在凸包外部。
一个基本概念/误解是,当前最好的算法(SATA)能够起作用,是因为它能够在训练集中进行插值采样。另一个基本概念/误解是,插值发生在贯穿整个任务和数据集的流程中(估计就是说采样和预测)。事实上,很多直觉(intuitions)和理论都是依赖这个假设(指刚刚的基本概念/误解)。
【贡献】我们从经验和理论上反对上述两点假设,并展示在任意高维(大于100)数据集中,插值采样从来不会发生。这些结果,是对我们现有“将插值和外推定义为衡量泛化能力的指标”这一概念有效性的一种挑战。(啥意思?)
下面就是观后感,希望真正从事机器学习领域的大神能提供解释,这里就是抛砖引玉了。
一、Data Manifold
1.1 这是啥
全文一直在强调Data Manifold,但由于才粗学浅,我并不知道Data Manifold是个啥,这对于机器学习、统计学习的同学来说应该是个很简单的概念吧。在网上翻了翻,找了篇感觉靠谱的科普文章:Manifolds in Data Science — A Brief Overview,而这个Data Manifold对应的中文解释应该是数据流形,数据在高维空间中的一种可视化表示,即“流动的形状”。
回到这篇科普文章Manifolds in Data Science — A Brief Overview,流形的定义,经过带有我理解的翻译,大致就是,这个manifold用于描述数据在高维空间的几何表示。一般地,我们三维生物无法理解四维及以上的几何表示,但如果这种高维几何表示,符合如下条件,即可认为是一种manifold:
想象自己是一只蚂蚁,在三维空间中行走,从自己的观察角度下,看到的面是平面(二维的)
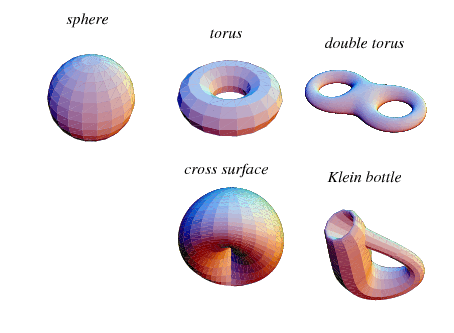
文中提供了一些manifold的例子,这里就贴出来供直观感受。即所有的面都没有边、顶点,从三维的视角下,作为蚂蚁所踩到的面均是二维的平面。
1.2 有啥用
我无法考证(鄙人菜鸡一只),只能认为下面的叙述是正确的。因为在高维空间的数据无法被可视化,我们可以通过将高维数据集拆分成特殊的子集,来可视化,而这些特殊的子集,即为manifold。也即是说,manifold是用于将高维数据降维表示的工具(stepping stone,文中为垫脚石)。
1.3 Manifold Learning
如果我们有了manifold,这个manifold是学到的,是对高维空间数据的一种数据表示形式,我们就可以通过这个manifold来进行预测,预测的内容是留在原来的剩余空间内的。
Many tasks in machine learning are concerned with learning manifold representations for data, and then utilizing this representation to make predictions about the remaining space.
这就跟Learning in High Dimension Always Amounts to Extrapolation相关联起来了,“预测关于剩余空间的内容”,如果这个“预测”超出了“剩余空间”呢?
二、插值与外推
2.1 结论
直接上结论:
“我们一般认为,模型泛化能力的高低,取决于模型的插值能力,也即是说,如果模型能够在一个凸包中准确地描述这个数据集,那么这个模型的泛化能力就很强”
上述理论是有问题的。为了满足模型插值行为,数据集的数量必须呈指数型地上升,即数据集维度越高,数据集的大小就必须越大(这跟我们平时训练网络的直观想法是一致的);在训练集上,模型的表现很好,但在测试集上,模型的表现就不好了(这也是一致的),其原因就是,模型所描述的凸包,训练集是在凸包内的,但测试集几乎都在凸包外。
2.2 推理
- 模型将数据集描述为manifold,是个凸包。训练过程,是在凸包内部采样,因此训练可以视为插值。预测过程,被视为在凸包内部采样,也就是说经由模型描述的凸包,将预测数据也包含在其中,即泛化能力强,模型好。
- 当预测数据在凸包外,这种行为叫做外推,因为这些预测数据没有被模型考虑到,因此模型无法准确预测出结果。我们可以观察到,当预测行为,从插值到外推,性能(预测准确度)降低。
- 作者通过生成数据与真实数据,观察到了一种现象,并在后续篇幅中通过理论推导进行证明:当数据维度大于100时,模型只能外推
咋推理的,我觉得对我的方向没有好处,就没再看下去了。
2.3 个人理解
数据维度大了,就只能外推。啥意思?这是不是在说:
- 现有模型,无法怎么描述数据集,当出现新的采样的时候,这个采样点就一定会落在模型描述的凸包外
- 进一步地,模型无法囊括全部内容,就像在平面上画圈,始终有内部和外部
- 那咋办,我也不知道
- 我们现在的模型,因为拥有超人的能力,能够处理外推的情况
- 有没有方法能够能够将外推情况降低,那岂不是模型的预测能力就提高了
- 有没有办法让外边的采样点通过什么转换,变到内部,或则让模型能够更能适应外推的情况?
三、其它
一些讨论: https://www.reddit.com/r/MachineLearning/comments/qbbknr/r_learning_in_high_dimension_always_amounts_to/
以及我觉得重要的话:
“manifold” refers to spaces with a differentiable or topological structure, while “variety” refers to spaces with an algebraic structure, as in algebraic varieties. 来自https://en.wikipedia.org/wiki/History_of_manifolds_and_varieties
这里声明下我在机器学习方向上是小白,想看看大神例如LeCun怎么从“哲学”等高纬度方向、自顶向下、宏观地看待机器学习、深度学习,为我做CV提供方向、指导,例如问题的定义、深层描述等。看了老半天,似乎还是没能理解LeCun大神的点在哪儿,修为不够。















 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









