







PyTorch的nn.LSTM使用说明
PyTorch的nn包下面自带很多经典的模型,我们可以快速的引入一个预训练好了的模型用来处理我们的任务,也可以单纯的添加一个这种架构的空白网络称为我们模型的子结构。其中LSTM是使用的相当多的一个,本文介绍nn.LSTM的一些使用情况。
LSTM
在介绍其使用之前先简述一下LSTM,好和具体实现对应起来。
LSTM的结构如下图,也是一种链式重复结构;但是和传统的RNN节点输出仅由权值,偏置以及激活函数决定相比,它重复结构中有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力,消除了RNN中无法考虑长期依赖的缺点。
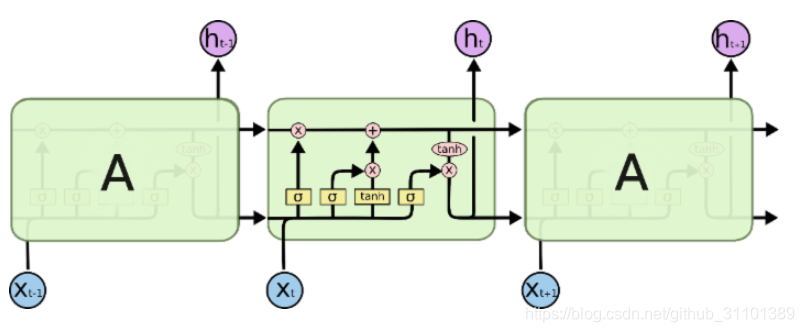
接下来对重复结构里面的每个小结构进行拆解分析。
细胞状态
首先关注最上面这个数据线,

它代表的运算是

其中
C
t
−
1
C_{t-1}
Ct−1就是上一时刻的细胞状态,而
f
t
f_t
ft和
i
t
i_t
it就是独特的遗忘门和更新门。
遗忘门 f t f_t ft
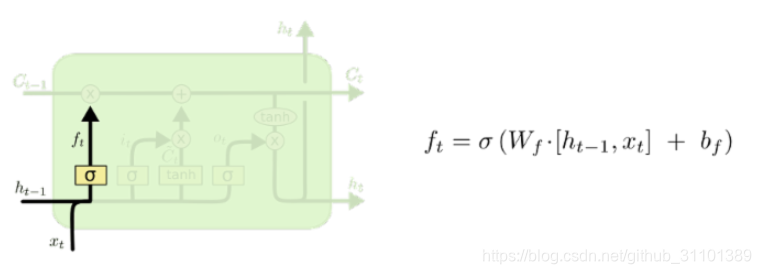
遗忘门由前一时刻的隐状态和当前时刻的输入计算得到。通常我们使用
s
i
g
m
o
d
sigmod
sigmod作为激活函数,输出一个在 0 到 1 之间的数值给每个在细胞状态
C
t
−
1
C_{t-1}
Ct−1中的数字。1 表示“完全保留”,0 表示“完全舍弃”,决定我们会从细胞状态中丢弃什么信息。
输入门 i t i_t it
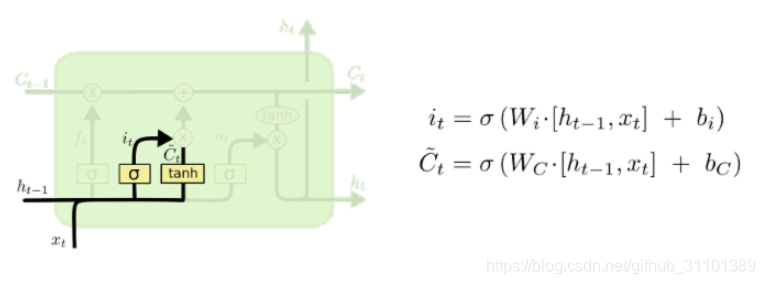
输入门同样由前一时刻的隐状态和当前时刻的输入计算得到。用来更新旧细胞状态,其中
i
t
i_t
it的激活函数也是用
s
i
g
m
o
d
sigmod
sigmod但是单元状态更新值
C
~
\tilde{C}
C~一般用tanh作激活函数。
i
t
i_t
it用来控制
C
~
\tilde{C}
C~哪些部分用来更新C
输出门 o t o_t ot
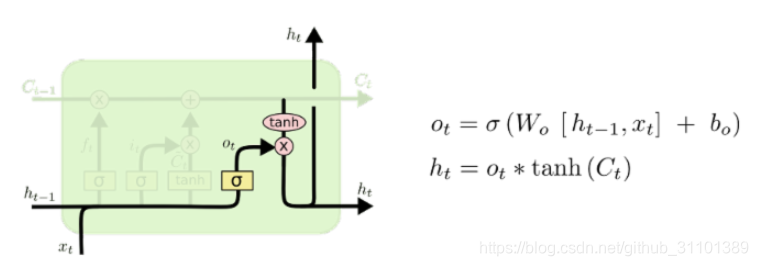
o
t
o_t
ot和计算和其他两个门大同小异,问题在于还需要依托于输出结果去更新隐状态。
nn.LSTM详解
查看官方文档可以看到其有9个参数,下面一一解释。
- input_size,这个很好理解就是输入数据的大小。整个网络的输入应该是这样
input(seq_len, batch, input_size),该参数就决定每一个词的维度。 - hidden_size,隐藏层节点特征维度。
- num_layers,LSTM的层数,经常使用的以及上面展示的和默认参数都是1层,多层LSTM后面层的节点输入不是x了,是前一层对应隐节点的状态 h t l − 1 h^{l-1}_t htl−1.
- bias ,网络是否设置偏置,默认是True.
- batch_first ,上面说到网络的输入应该是这样
input(seq_len, batch, input_size),但是如果这个参数为True,输入可以用input(batch, seq_len, input_size)这样更直接的形式。 - dropout,随机丢失的比例,但是仅在多层LSTM的传递中使用。
- bidirectional,如果设置为True,则网络是双向LSTM,默认是False.
实际运用
import torch.nn as nn
#需要引用这个包
self.lstm = nn.LSTM(self.map_dim, self.lstm_size, bidirectional=True, batch_first=True)
#模型声明里面加入指定参数的声明
lstm_output, (h_n, c_n) = self.lstm(X_maps)
#在模型的前向传播里面使用即可(单双向LSTM的h_n和c_n尺寸不同需要注意)
nn.LSTMcell
上述的nn.LSTM模块一次构造完若干层的LSTM,但是为了对模型有更加灵活的处nn中还有一个LSTMCell模块,是组成LSTM整个序列计算过程的基本组成单元,也就是进行sequence中一个word的计算。
同时它的参数也就只有3个:输入维度,隐节点数据维度,是否带有偏置。仅提供最基本一个LSTM单元结构,想要完整的进行一个序列的训练的要还要自己编写传播函数把cell间的输入输出连接起来。但是想要自定义不同cell隐节点维度的多层LSTM的话,这个模块还是挺有用的。
import torch
from torch import nn
# 两个不同LSTMcell,隐节点的维度分别为30和20
cell_l0 = nn.LSTMCell(input_size=100, hidden_size=30)
cell_l1 = nn.LSTMCell(input_size=30, hidden_size=20)
# 分别初始化l0层和l1层的隐藏单元h和记忆单元C,取batch=3
h_l0 = torch.zeros(3, 30)
C_l0 = torch.zeros(3, 30)
h_l1 = torch.zeros(3, 20)
C_l1 = torch.zeros(3, 20)
# 这里是seq_len=10个时刻的输入,每个时刻shape都是[batch,feature_len],和上面的LSTM不同,没有长度序列概念,所以输入的第一维就是batchsize,也不要设置batch_first参数
xs = [torch.randn(3, 100) for _ in range(10)]
# 对每个时刻,从下到上计算本时刻的所有层,注意是两层,不是一层的两个单元
for xt in xs:
h_l0, C_l0 = cell_l0(xt, (h_l0, C_l0)) # l0层直接接受xt输入
h_l1, C_l1 = cell_l1(h_l0, (h_l1, C_l1)) # l1层接受l0层的输出h为输入

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









