






目录
摘要
本周在论文阅方面,阅读了一篇基于SVM-BP降雨型黄土滑坡灾害安全评价模型研究论文,SVM模型在数据筛选上具有相当好的效果。在深度学习上,学习了优化算法:蚁群算法。通过最高浓度信息素寻找最优路径。
This week,in terms of thesis reading,a research paper on the safety assessment model of rainfall-type loess landslide based on SVM-BP is perusal.SVM model has quite good effect on data filtering.In depth learning,learning optimization algorithm: ant colony algorithm.It seeks the optimal path through the highest concentration of pheromones.
文献阅读
1、题目和摘要
题目:基于SVM-BP降雨型黄土滑坡灾害安全评价模型研究
摘要:地质滑坡灾害的监测预警体系中存在地质灾害调查、数据监测和预测预警环节融合度不够、相互分散、结果评价缺失等缺点,本文针对降雨型黄土滑坡灾害监测预警中存在的实际问题和不足,结合多源信息和智能风险评估,提出一种准确率高和满足快速性的基于SVM-BP的地质灾害安全评价混合模型。本文主要针对降雨型黄土滑坡灾害,以降雨引发的坡体内部土壤含水率的变化为主因,使用坡体实测数据训练算法模型作为分类器,根据当前数据的分类结果评价坡体的危险等级。
2、SVM和BP神经网络
支持向量机 SVM 模型是二分类线性模型,特征空间中原始数据利用 SVM 模型获得间隔最大化的超平面分割。
超平面外的一点到该超平面的距离d为:(其中||W||为超平面的范数,常数b为截距。)
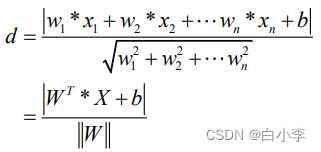
模型目标是找到所有数据与超平面距离最大化的超平面,目标函数定义为:
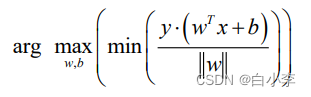
经过化简后,可以获取最优的值:
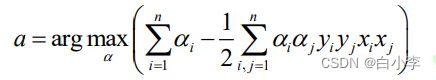
接下来计算出w和b:
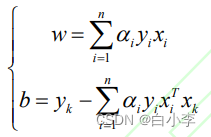
而通过w和b确定分离超平面,最后通过决策函数,输出分类结果:
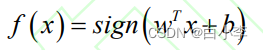
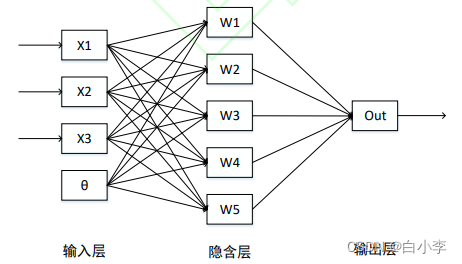
典型的BP神经网络是多层前馈网络,由输入层,隐含层与输出层构成。
3、SVM-BP混合模型
SVM分类器作为滑坡安全评价模型的初步判断模型,主要将滑坡数据分为安全和不安全两大类,如果安全,则直接输出评价结果;如果不安全,将滑坡数据输出至BP神经网络进一步分类,输出评价结果分为一般或者危险,评价滑坡坡体的状况。
第一步设计混合模型的 SVM 分类器完成数据初步筛选。滑坡数据包括安全、一般、危险三种状态,在运用 SVM 分类器前,将分类标签转为安全(安全)和不安全(一般和危险)两类。
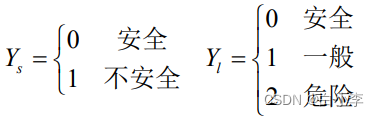
第二步再设计 BP 分类器,针对不安全的数据进一步分类,提高混合模型对于危险情况的敏感度,某滑坡数据 xi标准化处理如式

根据滑坡数据特征,实验前确定输入层节点为 9,输出层结点数为 1,隐含层暂时设置为 5,后续根据实验结果调整,其中,m为输入层节点数目,r为隐含层节点数目,n为输出层节点数目,a为1到10之间的常数。
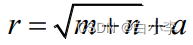
4、数据处理
数据首先使用灰色综合关联分析法处理得到指标权重和综合指数,完成原始数据安全、一般和危险的分类。
本文通过模糊层次分析结合灰色综合关联度人工评价滑坡数据。建立模糊一致判断矩阵R是由本层元素和与本层元素有关的上层元素之间相对重要程度比较结果组成的矩阵。则模糊一致判断矩阵为公式:

各个指标的权重:
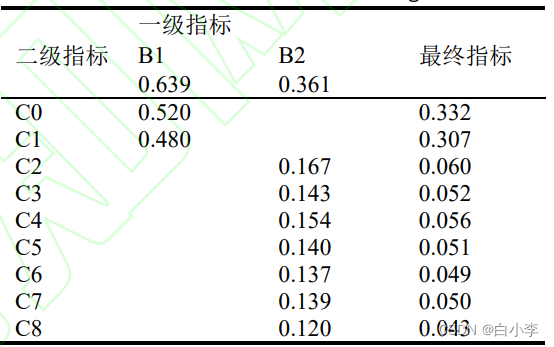
根据地质灾害特点可假设坡体安全状态综合指数符合正态分布,滑坡安全状态综合指数距离均值越远,坡体安全的概率就越小;越靠近均值,坡体安全概率越大。实验中可得到坡体安全状态综合指数的均值为 13.417,标准差为 1.739。实际中选取 2 倍标准差作为坡体安全的评价基准,选取 2.5 倍标准差作为坡体状态一般的评价标准,超出 2.5 倍标准差则作为坡体危险状态的评价基准。
5、实验结果以及分析
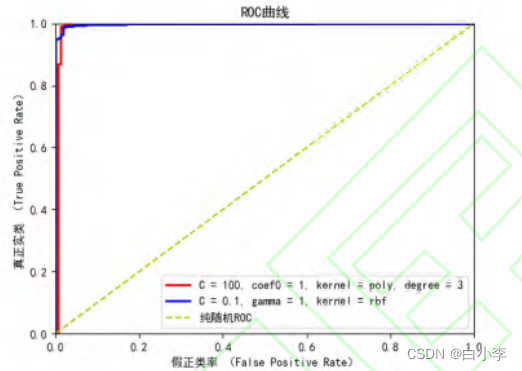
首先训练 SVM 模型。将量化的训练集标签分为安全和不安全(一般、危险)两大类,然后输入到SVM支持向量机分类器中,利用网格搜索方法,通过比较各个超参数的不同组合输出的评分,找到SVM模型超参数的最优组合,从而将数据分为安全和不安全两类。选择了 8 种组合绘制 ROC 曲线,将八种中较好的两种再次进行 ROC 对比。
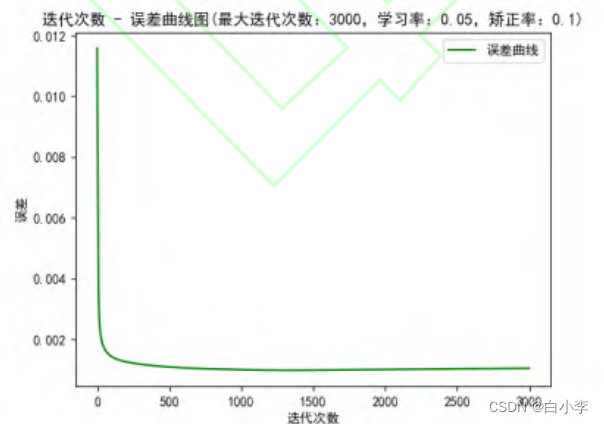
然后训练BP神经网络模型。当 SVM 模型训练好后,将分类为不安全的数据作为BP神经网络的输入,预先设置参考的学习率和矫正率,通过设置最大训练步数和误差精度来结束BP神经网络的训练。训练结束需要保存模型,测试的时候直接读取模型即可。在训练 BP 神经网络的过程中,通过观察绘制的损失函数曲线调整模型参数:
将 SVM、BP 神经网络以及 SVM-BP 混合模型三者进行对比分析,得出最适合的评价模型。
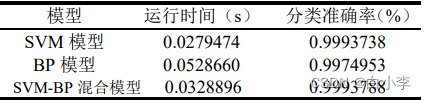
SVM-BP混合模型准确率与单一SVM模型基本一致这一情况而言,由于测试数据大部分为安全状态,所以经过SVM分类器分类后,直接输出结果,很少有数据需要通过BP分类器再分类,此时混合模型相当于单一的SVM模型,所以准确率基本一致。
针对单一BP模型准确率较SVM模型稍低情况而言,原始数据负样本较少,导致BP模型的训练集较少,导致其精度不高,表现出分类的准确率相较其他两种略低。
深度学习
1、蚁群算法
蚁群算法是一种用来寻找优化路径的概率型算法。
生物学原理:蚂蚁在寻找食物的路上,会通过在路途中留下信息素,路途越长,这条路的信息素挥发的也就越快,后续的蚂蚁会选择信息素浓度高的路进行行走,病并在上面留下新的信息素,逐渐循环下去最短的路径信息素浓度越来越浓,最短路径也就找到了。
优点:
-
采用正反馈制,使得搜索过程不断收敛,最终逼近最优解。
-
蚁群算法具有较强的鲁棒性。相对于其他算法,蚁群算法对初始路线的要求不高。
-
搜索过程采用分布式计算方式,多个个体同时进行并行计算,大大提高了算法的计算能力和运行效率。
-
蚁群算法的参数较少,设置简单,因而该算法易于应用到组合优化问题的求解。
缺点:
-
收敛速度慢:需要较长时间才能发挥正反馈的作用,导致算法初期收敛速度较慢。
-
局部最优问题:正反馈会使次优解很快占据优势,使算法陷入局部最优,且难以跳出局部最优。
-
优化能力不足:参数选择更多是依赖经验和试错,不恰当的初始参数会减弱算法的寻优能力。
-
种群多样性与收敛速度的矛盾:正反馈加快了蚁群算法的收敛速度,却使算法较早地集中于部分候选解,因此正反馈降低了种群的多样性,也不利于提高算法的全局寻优能力。
2、 步骤
1、初始化。包括信息素初始化,启发信息初始化,以及种群规模、信息素挥发率等参数初值的设置。
2、构建解空间。将各个蚂蚁随机置于不同的出发点,对每个蚂蚁按照转移概率公式确定下一个要去的城市,访问完所有城市后,就有了一条路径。
转移概率计算公式:
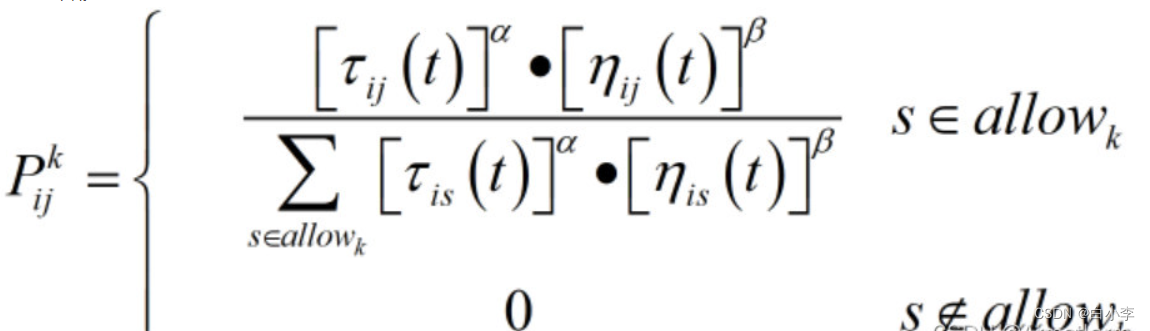
3、更新信息素。信息素更新包括两个环节。
(1)信息素挥发,用于降低路径上的信息素,减小信息素对未来蚂蚁行为的影响,增加算法的探索能力;
(2)信息素释放,蚂蚁在其所经过的路径上释放信息素,加强对蚂蚁未来选择该路径的影响,增强算法的开发能力。
信息素浓度计算公式:(0<p<1)
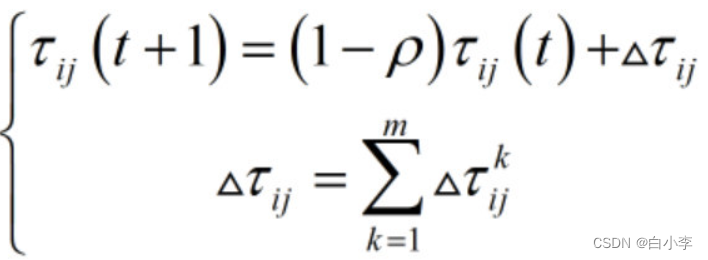
4、判断是否结束。如果达到最大迭代次数,就终止计算,输出最优解。否则清空蚂蚁经过路径的记录表,返回步骤2。
3、代码
import random
import numpy as np
import copy
import sys
# 城市位置
coordinates = np.array([[565.0, 575.0], [25.0, 185.0], [345.0, 750.0], [945.0, 685.0], [845.0, 655.0],
[880.0, 660.0], [25.0, 230.0], [525.0, 1000.0], [580.0, 1175.0], [650.0, 1130.0],
[1605.0, 620.0], [1220.0, 580.0], [1465.0, 200.0], [1530.0, 5.0], [845.0, 680.0],
[725.0, 370.0], [145.0, 665.0], [415.0, 635.0], [510.0, 875.0], [560.0, 365.0],
[300.0, 465.0], [520.0, 585.0], [480.0, 415.0], [835.0, 625.0], [975.0, 580.0],
[1215.0, 245.0], [1320.0, 315.0], [1250.0, 400.0], [660.0, 180.0], [410.0, 250.0],
[420.0, 555.0], [575.0, 665.0], [1150.0, 1160.0], [700.0, 580.0], [685.0, 595.0],
[685.0, 610.0], [770.0, 610.0], [795.0, 645.0], [720.0, 635.0], [760.0, 650.0],
[475.0, 960.0], [95.0, 260.0], [875.0, 920.0], [700.0, 500.0], [555.0, 815.0],
[830.0, 485.0], [1170.0, 65.0], [830.0, 610.0], [605.0, 625.0], [595.0, 360.0]])
# 参数设置
ALPHA, BETA, RHO, Q = 1.0, 2.0, 0.5, 100.0
# 城市数目和蚂蚁数
city_num, ant_num = 50, 50
# 城市距离
distance_grap = np.zeros((city_num, city_num))
# 信息素
pheromone_grap = np.ones((city_num, city_num))
# ---------------------蚂蚁----------------------
class ant(object):
# 初始化
def __init__(self, ID):
self.ID = ID # 蚂蚁编号
self.born()
def born(self):
self.path = [] # 存储蚂蚁走过的路径
self.total_distance = 0.0 # 蚂蚁走过的路径的和
self.current = -1 # 初始当前蚂蚁所在的位置
self.city_state = np.ones(city_num, dtype=int) # 是否遍历过的城市状态,1为还没遍历,0为已经遍历
city_index = random.randint(0, city_num - 1) # 随机选择出生点
self.current_city = city_index # 出生点作为当前蚂蚁所在的城市
self.path.append(city_index)
self.city_state[city_index] = 0 # 把该城市改为已经遍历
self.move_count = 1
# 选择下一个城市
def select_city(self):
next_city = -1 # 初始化下一个城市
select_city_prob = np.zeros(city_num) # 用于存储选择每个城市的概率
total_prob = 0.0 # 概率概率总和
# 获取下一个城市的概率
for i in range(city_num):
if self.city_state[i]:
try:
# 计算选择每个城市的的概率
select_city_prob[i] = pow(pheromone_grap[self.current_city][i], ALPHA) * pow(
1.0 / distance_grap[self.current_city][i], BETA)
total_prob += select_city_prob[i]
except ZeroDivisionError as e:
sys.exit(1)
# 轮盘算法
if total_prob > 0:
temp_prob = random.uniform(0.0, total_prob)
for i in range(city_num):
if self.city_state[i]:
# 轮次相减
temp_prob -= select_city_prob[i]
if temp_prob < 0.0:
next_city = i
break
if (next_city == -1):
next_city = random.randint(0, city_num - 1)
while ((self.city_state[next_city]) == False):
next_city = random.randint(0, city_num - 1)
# 返回下一个城市序号
return next_city
# 移动
def move_city(self, next_city):
self.path.append(next_city)
self.city_state[next_city] = 0
self.total_distance += distance_grap[self.current_city][next_city]
self.current_city = next_city
self.move_count += 1
# 计算所走过的城市的路程总和
def cumulate_distance(self):
temp_total_distance = 0.0
temp_start = -1
for i in range(1, city_num):
start, end = self.path[i - 1], self.path[i]
temp_total_distance += distance_grap[start][end]
temp_start = start
# 终点到最开始出生点的距离
temp_total_distance += distance_grap[temp_start][0]
self.total_distance = temp_total_distance
# 搜索路径
def search_city(self):
self.born()
while self.move_count < city_num:
next_city = self.select_city()
self.move_city(next_city)
self.cumulate_distance()
if __name__ == "__main__":
# 计算城市间距离
temp_distance = np.zeros((city_num, city_num))
for i in range(city_num):
for j in range(i, city_num):
temp_distance[i][j] = temp_distance[j][i] = np.linalg.norm(coordinates[i] - coordinates[j])
distance_grap = temp_distance
ants = [ant(ID) for ID in range(ant_num)] # 初始蚁群
best_ant = ant(-1)
best_ant.total_distance = 1e6 # 初始最大距离
iter = 1 # 迭代次数
iter_max = 100 # 最大迭代数
while iter < iter_max:
for ant in ants:
ant.search_city()
if ant.total_distance < best_ant.total_distance:
# 更新最优解
best_ant = copy.deepcopy(ant)
# 获取每只蚂蚁在其路径上留下的信息素
temp_pheromone = np.zeros((city_num, city_num))
for ant in ants:
for i in range(1, len(ant.path)):
start, end = ant.path[i - 1], ant.path[i]
# 在路径上的每两个相邻城市间留下信息素
temp_pheromone[start][end] += Q / ant.total_distance
temp_pheromone[end][start] = temp_pheromone[start][end]
# 更新所有城市之间的信息素
for i in range(city_num):
for j in range(city_num):
pheromone_grap[i][j] = pheromone_grap[i][j] * RHO + temp_pheromone[i][j]
print(u"迭代次数:", iter, u"最佳路径总距离:", int(best_ant.total_distance))
iter += 1
print(best_ant.path)结果:

总结
本周对SVM模型进行了再次的学习,以及开始学习优化算法,这次学习的是蚁群算法,只是大致看了一遍,还需继续强化学习。

















 6759
6759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









